LLM agent 성능을 이야기할 때 우리는 자주 모델을 먼저 본다.
더 큰 모델인가, instruction tuning을 했는가, tool-use 데이터로 추가 학습했는가, reasoning model인가.
하지만 **Adapting the Interface, Not the Model: Runtime Harness Adaptation for Deterministic LLM Agents**는 질문을 다른 곳으로 돌린다.
에이전트는 모델만으로 움직이지 않는다.
관찰을 어떤 형태로 보여 주는지, tool schema가 얼마나 명확한지, 모델이 낸 action을 실행 전에 고칠 수 있는지, 반복 실패와 loop를 누가 감지하는지, 환경의 성공/실패 신호가 다음 turn에 어떻게 들어가는지가 모두 행동을 만든다.
그렇다면 반복 실패의 일부는 모델 가중치를 다시 학습하지 않아도, 모델과 환경 사이의 runtime interface를 고쳐서 줄일 수 있다.
Life-Harness의 핵심은 이 관점이다.
모델은 frozen 상태로 두고, 평가 환경도 바꾸지 않는다.
대신 training trajectory에서 반복되는 interface failure를 모아 environment contract, procedural skill, action realization, trajectory regulation 네 계층의 하네스로 바꾼 뒤, held-out evaluation에서는 그 하네스를 고정해서 재사용한다.
한 줄로 줄이면 이렇다.
Life-Harness는 에이전트 실패를 “모델이 더 똑똑해야 한다”가 아니라 “실행 인터페이스가 어떤 실패를 흡수해야 하는가”의 문제로 바꾼다.

무엇을 해결하려는가
논문이 겨냥하는 문제는 open-ended chat이 아니라 deterministic, rule-governed agent environment다.
예를 들어 항공 예약, retail support, telecom service, ALFWorld, WebShop, OS interaction, DBBench처럼 tool contract와 evaluation rule이 비교적 안정적인 환경이다.
이런 환경에서 agent가 실패하는 이유는 항상 “추론 능력 부족”만은 아니다.
모델의 의도는 맞는데 action format이 환경이 받는 형태가 아니거나, tool description이 실제 API contract를 충분히 설명하지 못하거나, 같은 bash/SQL/action을 반복하면서 step budget을 태우거나, 이미 결정된 정책 제약을 매 turn 다시 헷갈릴 수 있다.
논문은 Qwen3-4B-Instruct를 training task에 돌려 실패 trajectory를 수집하고, 실패를 네 종류로 분류한다.
| 실패 유형 | 예시 | 하네스가 개입할 수 있는 지점 |
|---|---|---|
| Action realization failure | 모델 의도는 맞지만 환경이 실행할 수 없는 action format, 누락된 argument, 잘못된 call 형태 | 실행 전 validation, canonicalization, repair, block |
| Environment contract mismatch | syntactically valid하지만 tool policy나 environment convention을 어김 | episode 시작 전 tool description과 constraint 보강 |
| Trajectory degeneration | 같은 행동 반복, no-op loop, stagnation, budget exhaustion | 실행 후 trajectory monitor와 recovery feedback |
| General reasoning failure | 계산·판단 자체가 틀림 | 하네스만으로 완전히 해결하기 어려운 잔여 영역 |
중요한 점은 이 분류가 “모든 실패는 하네스로 고칠 수 있다”가 아니라는 것이다.
Life-Harness는 특히 기계적으로 식별 가능한 interface-level failure를 겨냥한다.
결정론적 환경에서는 action validity, 반복 횟수, admissible action, schema mismatch, budget exhaustion 같은 신호가 비교적 명확하므로 runtime layer가 개입하기 좋다.
네 계층의 하네스
Life-Harness는 agent lifecycle의 서로 다른 시점에 네 계층을 배치한다.
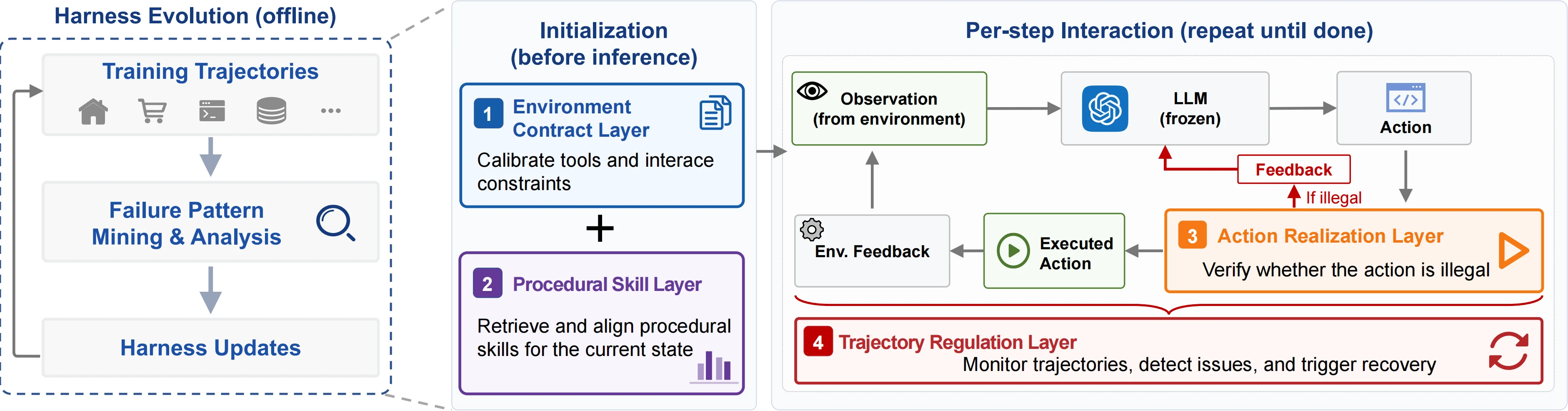
| 계층 | 작동 시점 | 역할 |
|---|---|---|
| Environment Contract Layer | interaction 전 | tool-use rule, policy constraint, common pitfall을 명시해 모델이 환경 계약을 잘못 이해하지 않게 함 |
| Procedural Skill Layer | task conditioning | training trajectory에서 얻은 procedural knowledge를 skill library로 만들고 task description에 맞게 retrieval/injection |
| Action Realization Layer | 모델 action 출력 후, 환경 실행 전 | action이 실제 환경에서 실행 가능한지 확인하고, 명확한 format 오류는 고치며, deterministic하게 실패할 action은 막음 |
| Trajectory Regulation Layer | 환경 feedback 후 | 반복, stagnation, no-op, budget exhaustion 같은 비진전 패턴을 감지하고 recovery guidance를 제공 |
이 구조가 흥미로운 이유는 “프롬프트를 잘 쓰자”보다 훨씬 구체적이기 때문이다.
Environment Contract는 tool description을 바꾸고, Action Realization은 실행 전 gate가 되며, Trajectory Regulation은 action history와 observation sequence를 감시한다.
즉 하네스는 instruction text만이 아니라 검사기, normalizer, monitor, retriever, recovery policy의 조합이다.
공개 GitHub README의 CLI flag도 이 네 계층에 대응한다.
다만 번호는 약간 헷갈릴 수 있다. repository 문서 기준으로 h2는 Action Realization, h3는 Environment Contract, h4는 Trajectory Regulation, h5는 Procedural Skill이다. enabled가 master switch이고, 개별 flag를 켜도 enabled가 없으면 적용되지 않는다고 설명한다.
하네스를 어떻게 만든다는 것인가
Life-Harness는 사람이 손으로 한 번에 완성한 rule set이 아니라, training trajectory를 보고 반복적으로 진화시킨다.
논문은 frozen Qwen3-4B-Instruct를 source model로 두고 training tasks에서 complete interaction trace를 모은 뒤, coding agent인 Codex가 trace와 design criteria를 읽고 harness layer를 수정하는 loop를 사용했다고 설명한다.
여기서 중요한 제약은 세 가지다.
-
모델 가중치는 바꾸지 않는다. fine-tuning, RL, preference optimization이 아니라 runtime side를 바꾼다.
-
benchmark environment와 evaluation logic은 바꾸지 않는다.
환경 자체를 쉽게 만들어서 점수를 올리는 방식이 아니라, agent와 환경 사이의 interface를 명확하게 만든다. -
test set은 harness evolution 중 숨긴다. training trajectory에서 반복 실패를 찾고, 최종 evolved harness를 frozen 상태로 다른 model backbone과 held-out evaluation에 적용한다.
이건 실무적으로 보면 agent runtime을 디버깅하는 방식과 닮았다.
실패 log를 보고 “모델에게 더 잘하라고 말하자”에서 멈추지 않고, 같은 실패가 재발하지 않게 tool schema, action parser, validation gate, state monitor, skill retrieval을 고친다.
좋은 harness engineering은 실패 분석이 곧 runtime patch로 이어지는 작업이다.
실험 결과: 평균보다 중요한 것은 넓은 전이
논문은 세 benchmark suite, 일곱 task scenario, 18개 model backbone에서 Life-Harness를 평가한다.
τ-bench: Airline, Retailτ²-bench: Telecom- AgentBench: ALFWorld, WebShop, OS, DBBench
headline은 강하다.
Life-Harness는 전체 126개 model-environment setting 중 116개를 개선했고, paper abstract 기준 average relative improvement는 **88.5%**다.
README와 overview figure도 같은 숫자를 전면에 둔다.
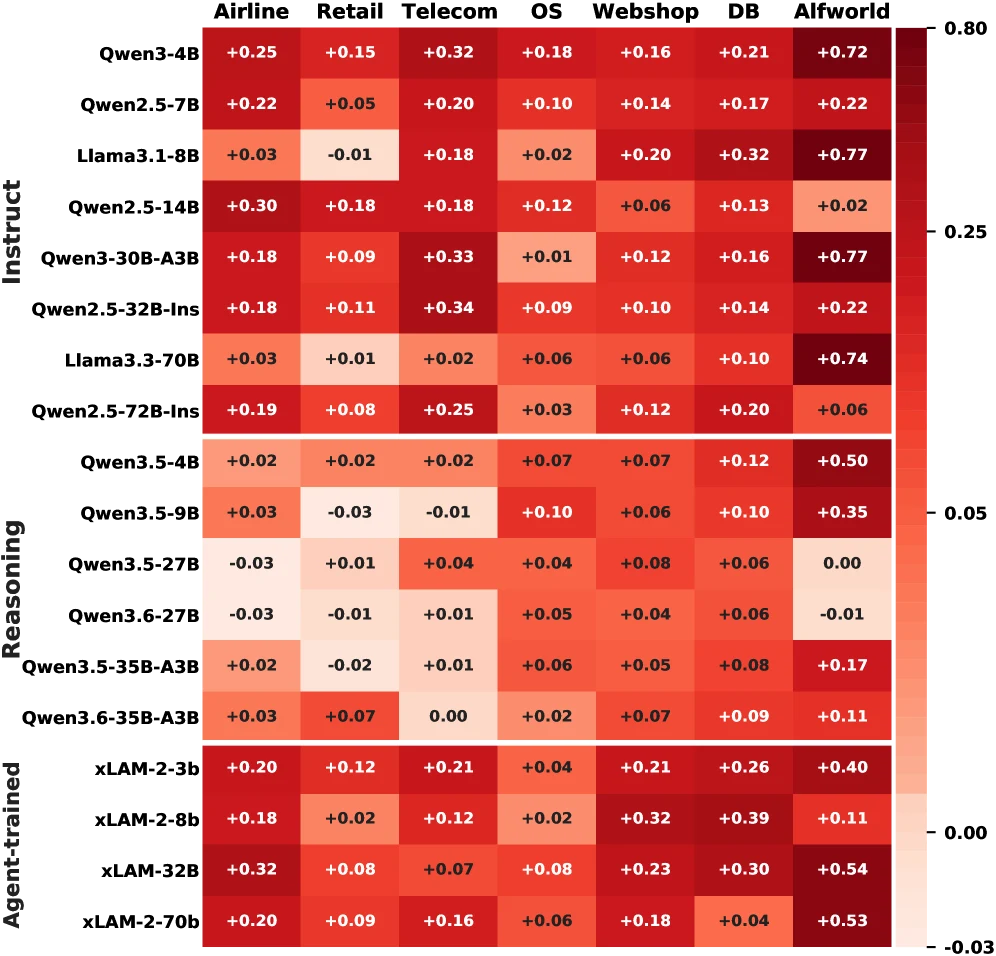
평균만 보면 과장되기 쉽기 때문에, benchmark별 수치를 같이 보는 편이 낫다.
| Suite | Benchmark | Metric | w/o | w/ Life-Harness | Relative gain | Improved |
|---|---|---|---|---|---|---|
| AgentBench | ALFWorld | Pass@1 | 41.1% | 75.7% | +84% | 17/18 |
| AgentBench | WebShop | Pass@1 | 31.4% | 44.0% | +40% | 18/18 |
| AgentBench | OS | Pass@1 | 34.7% | 41.2% | +19% | 18/18 |
| AgentBench | DBBench | Pass@1 | 48.4% | 64.6% | +34% | 18/18 |
| τ-bench | Airline | Pass@1 | 49.7% | 62.6% | +26% | 16/18 |
| τ-bench | Airline | Pass³ | 34.7% | 52.2% | +50% | 17/18 |
| τ-bench | Retail | Pass@1 | 56.2% | 61.8% | +10% | 14/18 |
| τ-bench | Retail | Pass³ | 37.9% | 45.3% | +19% | 15/18 |
| τ²-bench | Telecom | Pass@1 | 55.3% | 69.0% | +25% | 17/18 |
| τ²-bench | Telecom | Pass³ | 41.5% | 52.6% | +27% | 18/18 |
가장 큰 메시지는 “Qwen3-4B에서 만든 하네스가 Qwen3-4B에만 맞춘 prompt trick이 아니었다”는 점이다.
논문은 final harness를 17개 추가 model backbone에 적용했고, 전체 setting의 약 92%에서 개선을 봤다고 말한다.
이건 runtime interface가 특정 모델의 말버릇보다 환경 쪽 구조를 많이 담고 있다는 주장과 연결된다.
물론 모든 곳에서 같은 크기의 향상이 난 것은 아니다.
Retail Pass@1은 +10%로 상대적으로 작고, OS도 +19%다.
반대로 ALFWorld는 41.1%에서 75.7%로 크게 오른다.
이는 task마다 지배적인 실패 모드가 다르기 때문이다. embodied household task에서는 trajectory loop와 subgoal control이 크게 작동하고, business workflow에서는 policy/tool contract가 더 중요할 수 있다.
ablation: 어떤 계층이 어디서 중요한가
논문은 Qwen3-4B-Instruct에서 leave-one-layer-out ablation도 제공한다. full Life-Harness를 기준으로 한 계층을 뺐을 때 얼마나 떨어지는지 보는 실험이다.
| 제거한 계층 | 크게 떨어진 예 | 해석 |
|---|---|---|
| Contract | Retail -17.5%, Telecom -16.0%, DBBench -16.9% | tool policy, schema, 환경별 contract가 강한 task에서 중요 |
| Skill | Telecom -17.4%, Retail -15.9%, OS -14.1% | 반복되는 procedure와 task-specific hint가 필요한 환경에서 중요 |
| Action | Airline -61.7%, OS -59.6% | 실행 전 format/validity gate가 없으면 action-level 실패가 크게 늘어나는 환경 |
| Trajectory | ALFWorld -86.5%, Telecom -36.2%, WebShop -26.4% | loop, stagnation, subgoal drift가 치명적인 long-horizon interaction에서 중요 |
이 표가 좋은 이유는 Life-Harness를 단일 “prompt improvement”로 읽지 못하게 만든다는 점이다.
Airline에서는 Action layer 제거가 특히 치명적이고, ALFWorld에서는 Trajectory layer 제거가 치명적이다.
즉 좋은 하네스는 하나의 만능 규칙이 아니라, 실패가 생기는 lifecycle point를 찾아 가장 이른 안전한 지점에서 개입하는 계층 구조다.
prompt evolving이나 tool-use training과 어떻게 다른가
논문은 prompt-only evolving과도 비교한다. prompt evolving은 initial prompt를 반복적으로 최적화하지만, Life-Harness는 prompt 앞단뿐 아니라 action execution 전후의 runtime loop를 바꾼다.
논문은 prompt-only evolving이 일부 이득을 주지만 Life-Harness가 pass@1에서 더 큰 개선을 만들며, 평균 relative improvement가 추가로 120%라고 설명한다.
이 차이는 agent task의 본질과 관련 있다.
정적 QA에서는 prompt가 충분히 큰 영향을 줄 수 있다.
하지만 tool-using agent는 매 turn environment feedback을 받고, action parser를 통과하고, state budget을 쓰고, 실패를 반복할 수 있다.
그러면 성능은 첫 prompt만이 아니라 runtime이 중간 실패를 어떻게 관찰하고 처리하는가에 달린다.
논문은 specialized tool-use training과의 비교도 흥미롭게 제시한다.
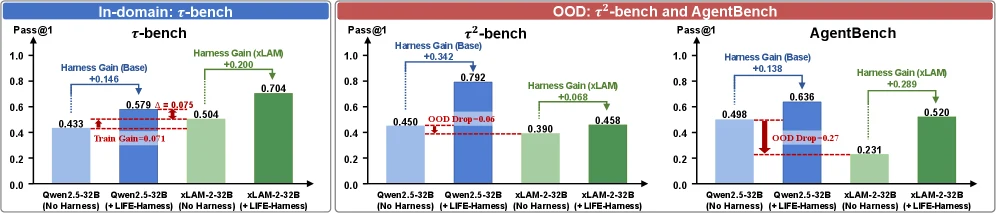
대표 예로 논문은 xLAM-2-32B를 사용한다. xLAM-2-32B는 Qwen2.5-32B-Instruct에서 tool-use scenario 관련 post-training을 거친 모델이다.
그런데 Qwen2.5-32B에 Life-Harness를 붙이면 in-domain τ-bench에서 xLAM-2-32B를 7.5 percentage point 앞선다고 보고한다.
또한 xLAM 자체에 Life-Harness를 붙여도 benchmark group 전반에서 6.8~28.9 point의 추가 이득이 난다고 말한다.
이 결과를 “training은 필요 없다”로 읽으면 위험하다.
더 정확한 해석은 training과 harnessing이 적응하는 대상이 다르다는 것이다. training은 model parameter를 source distribution에 맞추고, harnessing은 stable environment interface와 deterministic failure pattern을 외부 runtime에 넣는다.
그래서 tool-use training이 OOD agent environment로 잘 전이되지 않는 경우에도 harness는 별도의 보정 축이 될 수 있다.
공개 코드와 release maturity
논문은 arXiv abs/html에서 공식 GitHub 링크를 제공한다.
저장소는 Tianshi-Xu/Life-Harness이고, README는 Life-Harness를 논문 공식 구현으로 소개한다.
2026-05-25 조회 기준 GitHub API에서 확인한 상태는 다음과 같다.
| 항목 | 확인한 내용 | 해석 |
|---|---|---|
| GitHub repo | Tianshi-Xu/Life-Harness |
논문 공식 code release |
| 생성 / 최근 push | 2026-05-21 생성, 2026-05-24 push | 논문 공개 직후 정리 중인 초기 artifact |
| stars / forks | 31 / 7 | 초기 관심은 있지만 아직 성숙한 ecosystem은 아님 |
| releases / tags | 없음 | versioned release package보다는 research artifact repo에 가까움 |
| root license | GitHub API 기준 없음 | AgentBench 하위에는 LICENSE가 있지만 root-level license는 별도 확인 필요 |
| root contents | README.md, AgentBench/, TauBench/, assets/ |
installable package 하나가 아니라 benchmark family별 subproject 묶음 |
README는 두 benchmark family를 분리한다.TauBench는 uv 기반이고 Airline, Retail, Telecom을 다룬다.AgentBench는 Python 3.9/conda와 Docker 기반 task worker를 전제로 하며 ALFWorld, DBBench, OS, WebShop을 다룬다.
API endpoint와 key는 .env나 config에서 로컬로 채우도록 안내하고, private key나 private service URL을 commit하지 말라고 명시한다.
이 공개 상태는 꽤 유용하지만, production-ready framework라고 보기는 이르다. root에 pyproject.toml이나 unified requirements.txt가 있는 단일 패키지가 아니라, paper experiment를 재현하기 위한 benchmark-specific harness bundle에 가깝다.
또한 release/tag가 없고 root license도 명확하지 않다.
따라서 이 글에서는 Life-Harness를 “바로 pip install해서 쓰는 범용 agent framework”가 아니라, deterministic agent environment에서 runtime harness adaptation을 어떻게 구현할 수 있는지 보여 주는 연구 아티팩트로 읽는 편이 맞다.
실무 관점에서의 해석
Life-Harness가 실무 팀에게 주는 가장 큰 질문은 “우리 agent 실패 중 모델 학습으로 풀어야 할 것과 하네스로 풀어야 할 것을 구분하고 있는가”다.
예를 들어 다음 실패는 모델을 바꾸기 전에 runtime layer에서 먼저 볼 만하다.
| 반복 실패 | 하네스 쪽 대응 |
|---|---|
| tool call JSON이 자주 깨짐 | forgiving parser, schema validator, repair path, invalid-call feedback |
| 특정 API policy를 계속 어김 | tool description augmentation, environment contract card |
| 같은 명령을 반복하며 진전이 없음 | trajectory monitor, loop detector, budget-aware recovery |
| task마다 자주 쓰는 절차를 잊음 | skill library와 task-conditioned retrieval |
| final answer format이 evaluator와 안 맞음 | answer normalizer, commit gate, final format checker |
| 위험한 shell/API action을 시도함 | pre-execution gate, permission tier, human approval |
이런 장치는 모델 능력을 대체하지 않는다.
대신 모델이 실제 환경과 만나는 경계에서 생기는 마찰을 줄인다.
특히 결정론적 업무 환경에서는 실패가 재현 가능하고, 올바른 action contract가 있으며, tool feedback이 안정적이다.
이 경우 “더 큰 모델을 기다리기”보다 “실패를 runtime invariant로 바꾸기”가 빠를 수 있다.
동시에 caveat도 분명하다.
Life-Harness는 안정적인 environment contract가 있을 때 강하다.
논문도 limitation에서 open-domain task로 확장하는 것은 어렵다고 말한다.
목표, tool, external resource, success criteria가 매번 바뀌는 환경에서는 어떤 신호가 deterministic failure인지 정의하기 어렵고, 하네스가 과잉 개입해 valid behavior까지 막을 수 있다.
그래서 내 해석은 이렇다.
Life-Harness는 모든 agent를 자동으로 강하게 만드는 magic wrapper가 아니다.
하지만 반복되는 agent failure를 관찰 가능한 runtime failure mode로 분해하고, 각 failure mode를 적절한 lifecycle layer에 배치하는 사고방식을 매우 선명하게 보여 준다.
기존 harness 논의와 연결하면
이 블로그에서도 최근 Harness Engineering, Code as Agent Harness, SmallCode 같은 글을 다뤘다.
Life-Harness는 그 흐름에서 특히 연구적으로 흥미로운 위치에 있다.
Harness Engineering이 “에이전트가 일하기 좋은 소프트웨어 환경을 설계하라”는 실무 철학에 가깝다면,Code as Agent Harness는 code, tool, verifier, state를 agent harness라는 taxonomy로 정리한 survey에 가깝고,SmallCode는 작은 로컬 모델의 약점을 runtime harness로 보정하는 구현 사례에 가깝다.
Life-Harness는 여기에 실험 가능한 agent benchmark setting을 붙인다. frozen model과 fixed environment를 두고, runtime harness만 바꿨을 때 18개 model backbone과 7개 deterministic benchmark에서 얼마나 전이되는지를 본다.
그래서 이 논문은 “하네스가 중요하다”는 감각적 주장을, 적어도 rule-governed benchmark에서는 측정 가능한 adaptation axis로 만든다.
정리
Life-Harness의 가치는 headline 수치만이 아니다.
116/126 setting 개선과 평균 88.5% relative gain도 눈에 띄지만, 더 중요한 것은 agent adaptation의 대상을 모델 parameter에서 model-environment interface로 옮겨 놓은 점이다.
에이전트가 실패할 때마다 fine-tuning dataset을 만들 필요는 없다.
어떤 실패는 tool contract를 더 명확히 쓰면 줄어든다.
어떤 실패는 action gate가 실행 전에 막아야 한다.
어떤 실패는 trajectory monitor가 반복을 끊어야 한다.
어떤 실패는 skill library가 procedure를 다시 주입해야 한다.
그리고 어떤 실패는 여전히 reasoning 문제로 남는다.
좋은 agent system은 이 구분을 해야 한다.
Life-Harness는 그 구분을 네 계층의 runtime harness로 구현하고, deterministic benchmark에서 꽤 넓은 전이를 보여 준다.
실무적으로 읽으면 결론은 단순하다.
모델을 바꾸기 전에, 모델이 세계와 만나는 인터페이스를 먼저 디버깅하라.