개인 에이전트가 오래 쓰일수록 어려워지는 문제 중 하나는 “어떤 도구를 쓸 것인가”다.
사용자는 매번 선호 도구를 명시하지 않는다.
같은 날씨 요청이라도 어떤 사용자는 특정 weather API를 선호하고, 같은 코드 검사 요청이라도 어떤 개발자는 특정 linting skill을 반복해서 고른다.
표면 문장만 보면 가능한 skill이 여럿이고, 정답은 사용자의 누적 습관 속에 있다.
Statistical Priors for Implicit Preferences: Decoupling Skill Selection as a Local Harness in Personal Agents는 이 문제를 개인 에이전트의 implicit preference-driven skill selection으로 정식화한다.
논문의 핵심 주장은 간단하다.
장기적인 선호 학습은 LLM 프롬프트 메모리로 처리하기보다, 로컬에 있는 가벼운 통계 추정기가 맡는 편이 낫다.
LLM은 모든 선택을 최종 판단하는 존재가 아니라, 사용자가 “이번에는 이 도구를 써라”처럼 명시적으로 override한 경우만 판별하는 좁은 예외 처리기로 남긴다.
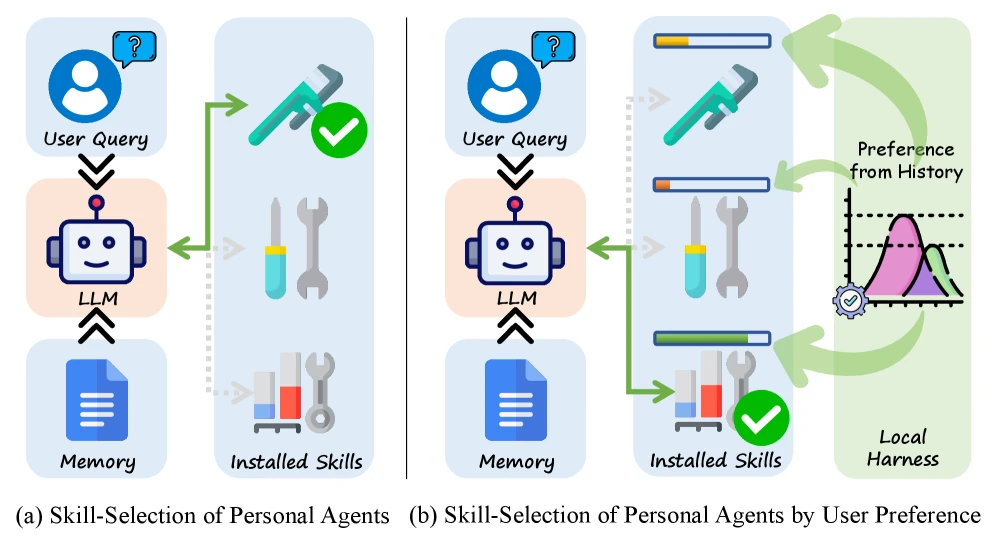
무엇을 해결하려는가
현재 많은 개인 에이전트는 사용자의 과거 선호를 “메모리”로 저장한 뒤, 다음 LLM 호출에 다시 넣는다.
이 방식은 직관적이다.
“사용자는 예전에 A 도구를 좋아했다” 같은 문장을 context에 넣으면 모델이 알아서 반영할 것처럼 보인다.
하지만 논문이 지적하는 병목은 이 방식이 두 종류의 일을 한 모델 호출에 섞어 버린다는 점이다.
첫째는 semantic intent parsing이다.
사용자가 “HouseBrew로 카푸치노를 주문해”라고 말하면, 문장 안에 명시된 도구를 읽어야 한다.
둘째는 statistical preference learning이다.
사용자가 그냥 “카푸치노 주문해”라고 말하면, 그동안 어떤 coffee-ordering skill이 성공 보상을 많이 받았는지 추정해야 한다.
전자는 언어 이해 문제에 가깝고, 후자는 온라인 추천·bandit 문제에 가깝다.
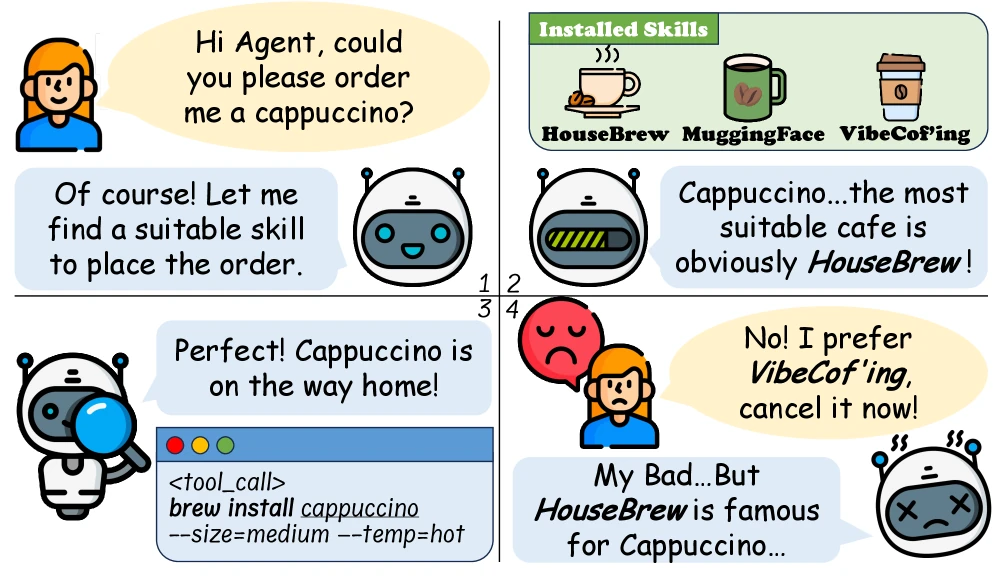
LLM 메모리 주입 방식은 이 둘을 모두 LLM에게 맡긴다.
사용자의 성공/실패 카운트를 prompt에 넣고, LLM이 그 통계와 현재 문장을 함께 해석해 최종 skill을 고르게 한다.
논문은 이것이 context overflow, latency, 긴 대화에서의 logic drift뿐 아니라, 더 근본적으로 확률적 credit assignment를 언어 모델의 비선형 추론에 맡기는 구조적 문제를 만든다고 본다.
핵심 아이디어 / 구조 / 동작 방식
Local Harness는 매 round를 세 단계로 나눈다.
| 단계 | 담당 | 역할 |
|---|---|---|
| Domain classification | LLM | query가 Finance, Travel, eCommerce 같은 어느 domain인지 좁힌다 |
| Local statistical default | 로컬 harness | 해당 사용자·domain에서 가장 가능성 높은 skill을 기본 선택한다 |
| Semantic override probe | LLM | query가 특정 skill 이름을 명시했는지만 좁게 판단한다 |
여기서 중요한 것은 LLM이 최종 선택자가 아니라는 점이다.
표준 query에서는 로컬 통계 prior가 기본 행동을 정한다. explicit query에서는 LLM probe가 “override가 있다”고 판정하고, 문장 안에 명시된 skill을 반환한다.
실행 뒤에는 (query, domain, selected skill, reward)가 로컬 harness에 업데이트된다.
논문은 두 가지 로컬 prior를 실험한다.
| Prior | 동작 방식 | 장점 | 한계 |
|---|---|---|---|
| Frequency prior | 사용자·domain·skill별 success rate를 세고 greedy하게 고른다 | 단순하고 싸다 | explicit exploration이 없어 stochastic preference에서 편향될 수 있다 |
| Bandit prior | LinUCB로 query, skill name, domain feature hashing을 쓰는 contextual bandit arm을 학습한다 | 불확실한 skill을 탐색하고 query context를 반영한다 | 구현이 frequency table보다 조금 복잡하다 |
핵심 baseline도 잘 잡혀 있다.ZeroShot-LLM은 history 없이 query와 skill description만 보고 고른다.InContext-Memory와 Profile-Memory는 LLM이 메모리까지 읽고 최종 선택한다.Bandit-as-Context는 bandit posterior를 LLM prompt에 넣고 LLM이 최종 판단하게 한다.
반면 Bandit-as-Override는 bandit이 기본 선택을 하고, LLM은 명시적 override 여부만 본다.
이 마지막 차이가 논문의 메시지다.
“통계를 LLM에게 설명해 주면 LLM이 잘 통합할 것”이라는 접근보다, 통계적 선택과 언어적 예외 처리를 물리적으로 분리하는 쪽이 낫다는 것이다.
공개된 근거에서 확인되는 점
평가는 저자들이 만든 ToolBench-60 sandbox에서 진행된다.
ToolBench에서 10개 domain, domain별 6개 skill, 총 60개 skill을 뽑고, 합성 사용자 50명에게 domain별 latent preference distribution을 부여한다. query는 두 종류다.
표준 query는 skill 이름을 언급하지 않아 사용자 preference를 맞혀야 하고, explicit query는 특정 skill 이름을 직접 언급해 semantic override 능력을 본다.
주 실험은 사용자당 500 interaction round, 3개 seed, explicit query ratio 10%로 수행된다.
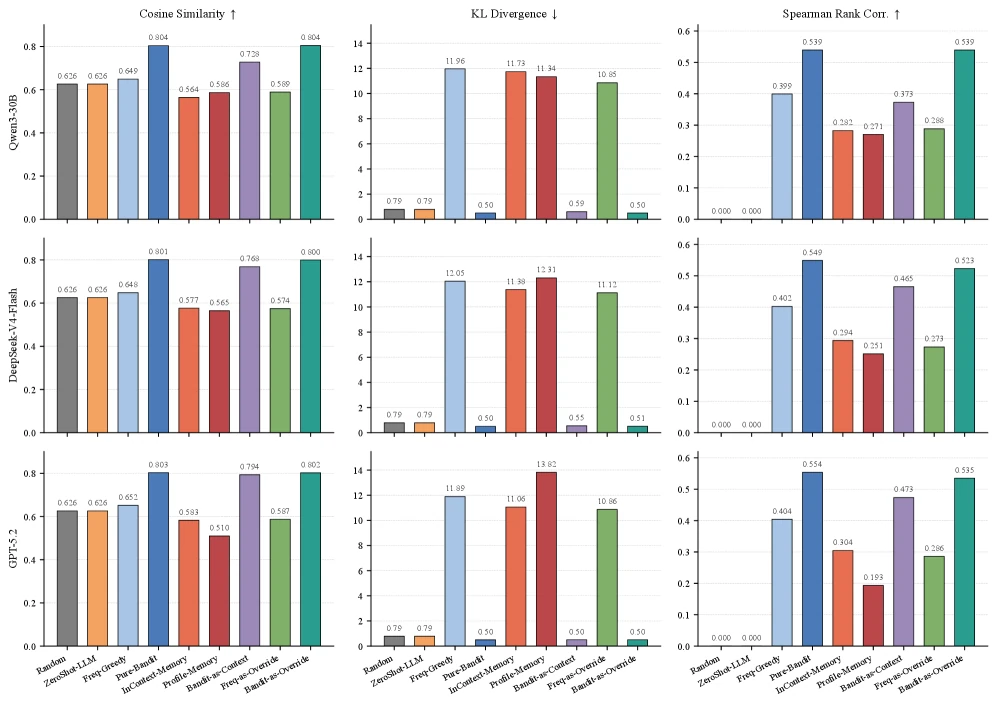
논문은 Qwen3-30B-Instruct, DeepSeek-V4-Flash, GPT-5.2라는 세 backbone에서 같은 비교를 반복한다.
아래는 Qwen3-30B-Instruct의 대표 결과다.
| 방법 | one-hot Regret ↓ | one-hot Acc ↑ | soft-0.3 Regret ↓ | soft-0.3 Acc ↑ | soft SRC ↑ |
|---|---|---|---|---|---|
| ZeroShot-LLM | 377.2 | 23.9% | 377.5 | 24.3% | 0.000 |
| Profile-Memory | 269.5 | 53.4% | 344.2 | 32.9% | 0.271 |
| Pure-Bandit | 140.2 | 80.4% | 282.0 | 39.5% | 0.539 |
| Bandit-as-Context | 344.2 | 34.1% | 369.6 | 26.4% | 0.373 |
| Freq-as-Override | 126.3 | 82.5% | 295.3 | 41.6% | 0.288 |
| Bandit-as-Override | 135.7 | 84.3% | 264.8 | 46.2% | 0.539 |
해석은 세 가지다.
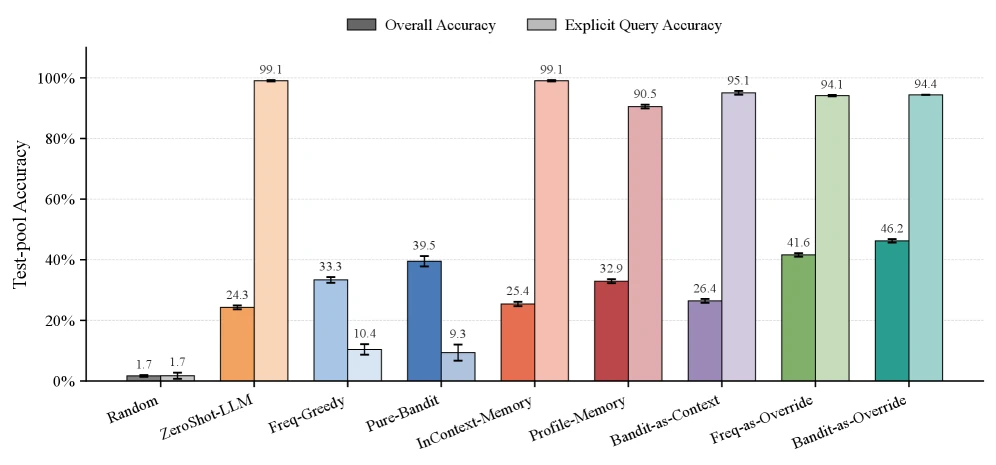
첫째, zero-shot semantics만으로는 implicit preference를 맞히지 못한다.
ZeroShot-LLM은 표준 query에서 사용자의 반복 습관을 볼 수 없기 때문에 regret이 높고 accuracy가 낮다.
둘째, 순수 통계만으로도 preference recovery는 꽤 강하다.
Pure-Bandit은 one-hot recovery rate 99.9%, soft SRC 0.539로 사용자 선호 posterior를 잘 따라간다.
하지만 explicit query를 처리할 언어 이해 channel이 없기 때문에 held-out accuracy는 override 기반 방법보다 낮다.
셋째, LLM에게 통계를 prompt로 넘기는 Bandit-as-Context가 오히려 약하다.
Qwen3 실험에서 soft-0.3 accuracy는 26.4%에 그쳐, pure bandit 39.5%보다도 낮다.
논문이 말하는 “memory-augmented LLM의 병목”이 바로 이 부분이다.
통계 신호를 context에 넣는 것과, 그 신호를 안정적인 의사결정 규칙으로 사용하는 것은 다르다.
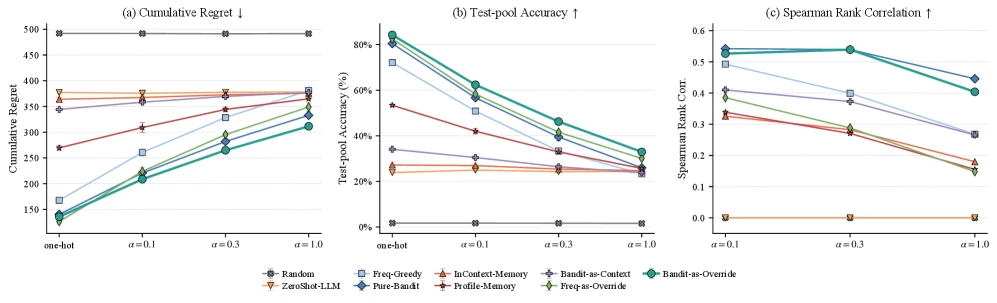
DeepSeek-V4-Flash와 GPT-5.2에서도 순위는 거의 유지된다. soft-0.3에서 Bandit-as-Override는 DeepSeek 기준 regret 255.9, accuracy 47.2%, GPT-5.2 기준 regret 256.8, accuracy 47.3%로 가장 강한 축에 있다.
반면 Profile-Memory는 같은 조건에서 DeepSeek 327.4 / 34.8%, GPT-5.2 316.0 / 38.6%에 머문다.
모델 backbone이 바뀌어도 “LLM memory prompt에 통계를 몰아넣는 방식”보다 “로컬 bandit + 좁은 override probe”가 안정적인 셈이다.
이론 파트도 같은 구조를 설명한다.
Local Harness의 policy는 표준 query 비율에서는 로컬 prior h_t, explicit query 비율에서는 LLM policy P를 쓰므로 P'_t = (1-λ)h_t + λP라는 convex mixture로 쓸 수 있다.
로컬 prior가 일관적으로 사용자 preference Q에 수렴하면, long horizon에서 LLM-only baseline보다 regret이 더 작아진다.
반대로 Profile-Memory나 Bandit-as-Context처럼 모든 신호를 한 번의 LLM 호출에 넣는 구조는 이 convex mixture decomposition을 보존하지 못한다.
실무 관점에서의 해석
이 논문은 개인 에이전트의 memory 설계에 꽤 직접적인 질문을 던진다.
모든 사용자 선호를 자연어 메모리로 저장하고 매번 prompt에 넣는 방식은 편하지만, 반복적인 선택 문제에는 맞지 않을 수 있다.
“사용자가 어떤 skill을 선호하는가”는 사실상 작은 recommender problem이고, success/failure feedback이 있다면 로컬 bandit이나 success-rate table이 더 적절한 표현일 수 있다.
실무적으로는 다음 구조가 유용해 보인다.
| 운영 레이어 | Local Harness식 해석 |
|---|---|
| Tool registry | domain별 후보 skill set과 skill name을 안정적으로 유지한다 |
| Preference state | 사용자·domain·skill별 reward 통계를 로컬에 저장한다 |
| Router | query를 domain으로 좁히고, 로컬 prior가 기본 skill을 고른다 |
| Override detector | LLM은 “이번 요청이 특정 skill을 명시했는가”만 판단한다 |
| Feedback loop | 성공/실패, 사용자의 수정, 재시도 여부를 reward signal로 축적한다 |
이 접근은 privacy 측면에서도 의미가 있다.
세밀한 행동 통계와 preference posterior를 원격 모델 context에 매번 보낼 필요가 줄어든다.
LLM 호출은 여전히 필요하지만, 고빈도 선택의 핵심 상태는 로컬에 남고, LLM은 낮은 entropy의 binary/JSON override 판단만 수행한다.
개인용 데스크톱 에이전트나 조직 내부 agent runtime에서는 이 분리가 latency와 비용뿐 아니라 데이터 경계 관리에도 도움이 된다.
또 하나 중요한 점은 “스킬을 많이 만든 뒤 RAG로 검색한다”와 “사용자가 반복적으로 보상한 skill을 선택한다”가 다르다는 것이다.
많은 agent runtime은 skill library를 retrieval problem으로 본다.
하지만 실제 사용에서는 기능적으로 비슷한 skill이 여러 개일 때 사용자의 암묵적 선호가 들어간다.
이때 retrieval score만 높다고 좋은 skill은 아니다.
Local Harness는 skill selection을 semantic relevance + personal preference + explicit override의 합성 문제로 다시 정의한다.
다만 공개 구현 상태는 조심해서 봐야 한다.
논문 초록은 https://github.com/ZyGan1999/Personalized-Skill-Selection을 코드 링크로 제시하지만, 확인 시점에는 해당 GitHub repository와 GitHub repository search가 공개 결과를 반환하지 않았다.
따라서 현재 이 글은 논문과 arXiv HTML figure를 근거로 한 구조·실험 해석이며, 공개 코드 재현성은 아직 확인되지 않은 상태로 보는 편이 안전하다.
한계와 caveat
가장 큰 한계는 benchmark가 합성 환경이라는 점이다.ToolBench-60은 preference-driven skill selection을 보기 위한 첫 sandbox로 의미가 있지만, 실제 개인 에이전트의 도구 생태계, 권한 승인, 실패 비용, noisy feedback, non-stationary preference를 모두 대표하지는 않는다.
논문도 stationary user profile, 즉시 binary reward, deterministic feature hashing을 한계로 든다.
또한 Local Harness가 remote LLM을 완전히 제거하는 것은 아니다. domain classifier와 override probe에는 여전히 LLM이 쓰인다.
따라서 “모든 것이 로컬”이라기보다, 고빈도 preference credit assignment를 로컬화하고 LLM의 역할을 좁히는 구조로 이해해야 한다.
마지막으로 explicit override ratio가 10%인 sandbox에서의 최적 구조가 모든 제품에 그대로 맞지는 않을 수 있다.
어떤 에이전트는 explicit tool naming이 드물고, 어떤 환경은 사용자가 자주 특정 provider를 지명한다. λ가 커질수록 LLM override channel의 품질과 비용이 더 중요해진다.
그럼에도 이 논문의 핵심 메시지는 강하다.
개인 에이전트가 사용자의 습관을 배워야 한다면, 그 습관을 장문의 메모리 문장으로만 다루지 말고, 로컬에서 업데이트되는 통계적 상태로 다루는 편이 더 안정적인 설계일 수 있다.