LLM 에이전트가 “기억한다”고 말할 때 실제로 궁금한 것은 단순히 과거 대화를 다시 불러오는지가 아니다.
더 중요한 질문은 과거 interaction을 통해 다음 instance에서 더 잘하는가다.
같은 코드베이스를 여러 번 고치며 구조를 파악하고, 같은 데이터베이스를 반복 질의하며 schema convention을 익히고, 같은 상대와 게임을 하며 전략을 찾아내는 능력은 단일 문제 풀이 능력과 다르다.
Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments는 이 질문을 벤치마크로 만든다.
논문은 CL-Bench를 “LLM 기반 시스템이 순차 경험으로 실제로 개선되는지” 평가하기 위한 어렵고 expert-validated된 continual learning benchmark로 제안한다.
핵심은 strong base model의 prior capability와 online learning의 기여를 분리하는 것이다.
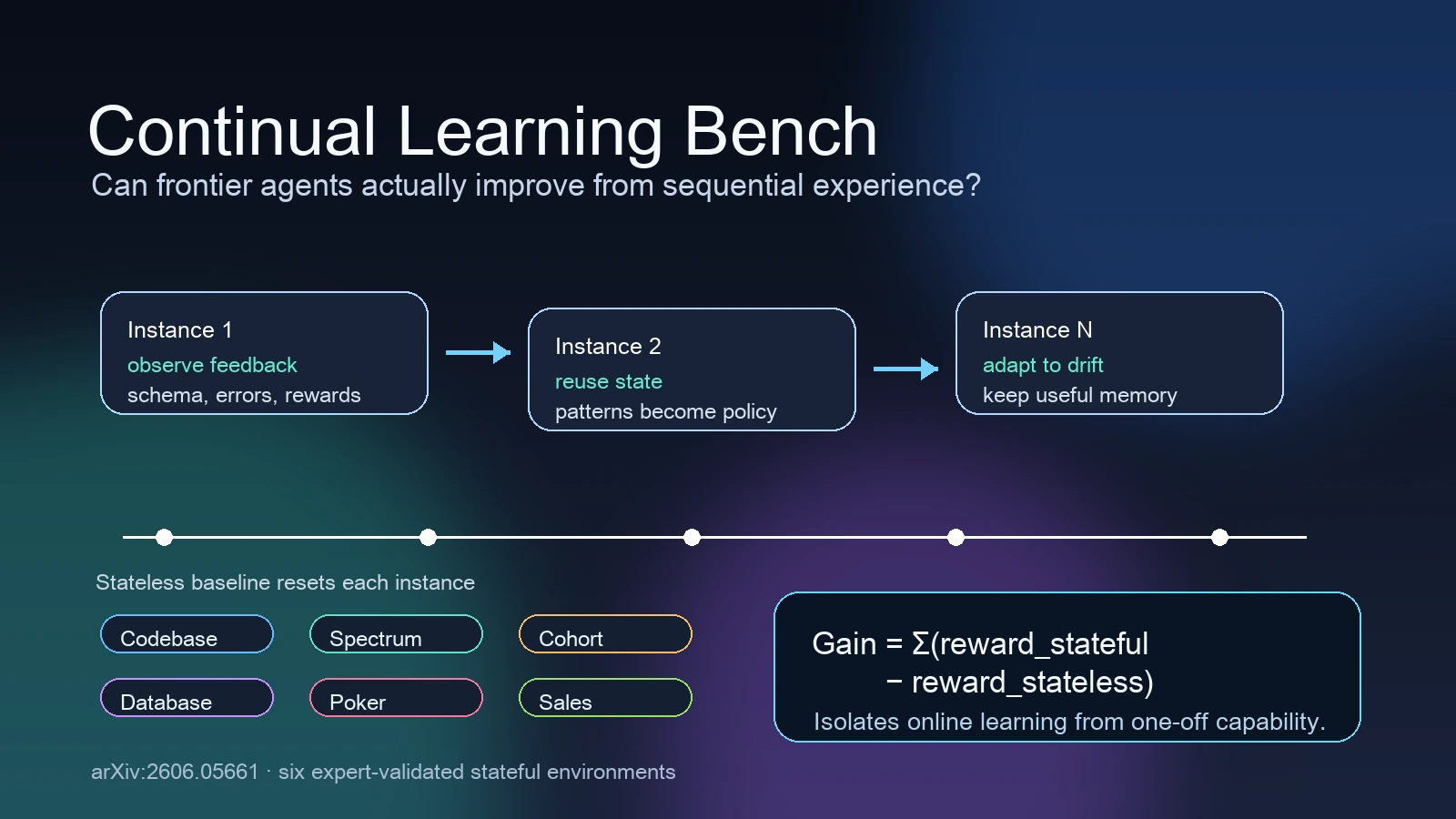
무엇을 해결하려는가
기존 benchmark는 대체로 한 번의 문제 풀이, 짧은 trajectory, 최종 정답률에 집중한다.
하지만 장기 실행 에이전트에서는 환경이 완전히 매번 새롭지 않다.
초기 instance에서 발견한 구조가 뒤의 instance에도 통하고, 중간 feedback이 다음 행동을 바꾸며, 때로는 환경 drift 때문에 오래된 기억을 버려야 한다.
CL-Bench는 이런 상황을 위해 각 task가 세 조건을 만족해야 한다고 둔다.
| 조건 | 의미 | 왜 중요한가 |
|---|---|---|
| Headroom | 처음 성능이 최대치보다 충분히 낮아야 함 | 단순히 더 강한 base model과 learning system을 구분하기 위해 |
| Shared latent structure | instance 사이에 발견 가능한 공통 구조가 있어야 함 | 코드 구조, schema convention, opponent strategy처럼 재사용 가능한 지식을 만들기 위해 |
| Learning mechanism | 앞선 instance의 관찰과 reward가 뒤 instance에 도움이 되어야 함 | 기억이 실제 행동 개선으로 이어지는 feedback loop를 만들기 위해 |
논문이 반복해서 강조하는 포인트는 “state가 있다”와 “학습한다”가 다르다는 점이다. vector memory, scratchpad, compaction, persistent conversation이 모두 state를 제공할 수 있지만, 그 state가 reward 개선으로 이어지는지는 별도로 측정해야 한다.

핵심 아이디어 / 구조 / 동작 방식
CL-Bench의 기본 단위는 task → instance → step이다.
하나의 task는 여러 problem instance의 순서열이고, instance는 reward가 정의되는 개별 문제이며, step은 agent가 instance 안에서 수행하는 개별 action이다.
평가 대상인 system은 model과 memory/learning mechanism을 합친 end-to-end unit이다.
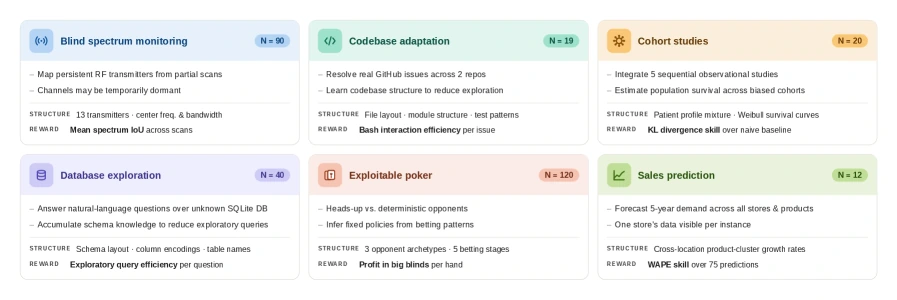
논문은 여섯 개 task를 제시한다.
| Task | 도메인 | instance 수 | agent가 배울 수 있는 latent structure | reward 축 |
|---|---|---|---|---|
| Blind Spectrum Monitoring | RF/signal processing | 90 | unknown channel map과 signal pattern | signal quality / monitoring 성능 |
| Codebase Adaptation | software engineering | 19 | codebase layout, test failure pattern | task success와 효율 |
| Cohort Studies | disease outbreak forecasting | 20 | study-specific confounder와 outbreak dynamics | forecasting / inference quality |
| Database Exploration | database querying | 40 | obfuscated schema convention과 data idiosyncrasy | query budget efficiency |
| Exploitable Poker | strategic game-playing | 120 | opponent strategy와 exploitable pattern | game profit |
| Sales Prediction | demand forecasting | 12 | product/category demand pattern | prediction accuracy |
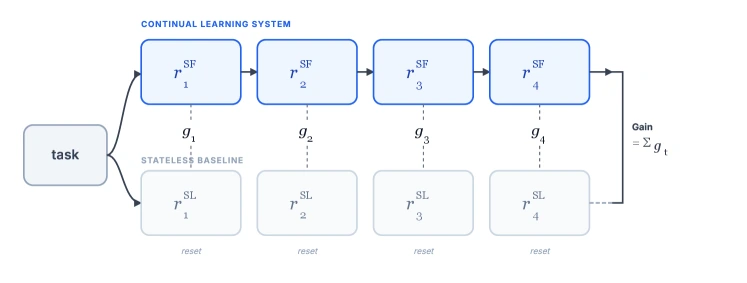
가장 중요한 측정값은 gain이다.
같은 system을 두 방식으로 돌린다.
하나는 history를 유지하는 stateful run이고, 다른 하나는 각 instance마다 초기화되는 stateless run이다. instance t의 gain은 다음처럼 정의된다.
gain_t = reward_t(stateful) - reward_t(stateless)
이 차이는 특정 instance가 원래 쉽거나 어려운 효과를 줄인다.
같은 system이 같은 instance를 history 없이 풀었을 때와 history를 가지고 풀었을 때의 차이를 보기 때문이다.
그래서 CL-Bench의 gain은 “모델이 원래 똑똑해서 잘함”보다 “누적 경험이 실제로 도움이 됨”에 더 가까운 신호가 된다.
공개된 근거에서 확인되는 점
이번 글은 arXiv abstract/HTML/PDF, 공식 사이트, 공식 leaderboard JSON, GitHub 저장소를 함께 확인해 정리했다.
공개 표면은 꽤 잘 갖춰져 있다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv | 2606.05661, v1, 2026-06-04 제출, cs.AI/cs.CL, CC BY 4.0 |
논문 identity와 figure/table의 기준 |
| 공식 사이트 | continual-learning-bench.com, task gallery, metrics/docs, leaderboard 제공 |
benchmark를 paper-only가 아니라 웹 문서와 함께 공개 |
| GitHub | pgasawa/continual-learning-bench, Apache-2.0, public repo |
코드·task artifact·viewer·benchmark runner가 공개되어 있음 |
| 설치 표면 | README 기준 Python 3.13+, uv, Docker 필요, clbench setup --all |
일반 pip package보다 연구용 benchmark harness에 가까움 |
| release 상태 | 조회 시점 기준 tags 0개, /releases/latest 404 |
versioned release보다는 초기 공개 연구 아티팩트로 보는 편이 안전 |
GitHub API 조회 시점의 저장소 상태는 stars 127, forks 14, open issues 3, default branch main이었다.
README는 clbench list, clbench run exploitable_poker --schedule quick_test --system icl 같은 quickstart를 제공한다.
즉 “논문에만 있는 benchmark”는 아니지만, 실제 재현은 Python 3.13, Docker, 모델 provider key, task별 dependency와 API 비용까지 포함한 운영 작업이다.
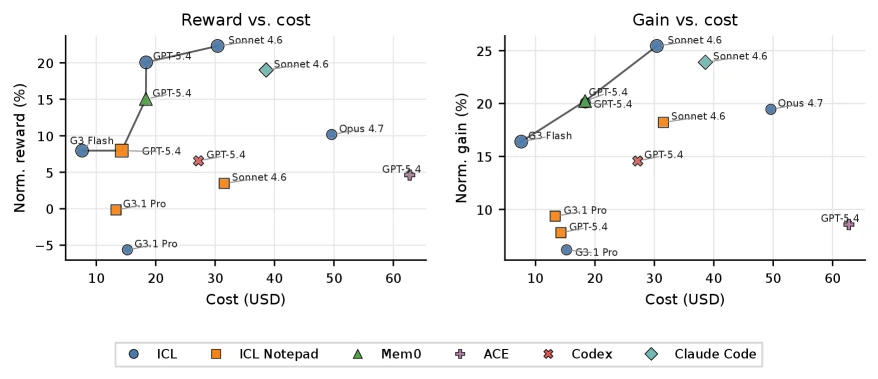
결과: 단순 memory system보다 full-context ICL이 강했다
논문의 aggregate leaderboard에서 가장 눈에 띄는 결과는 단순하다.
전용 memory system이 자동으로 continual learning을 해결하지 못했다.
오히려 full-context in-context learning(ICL)이 가장 강한 baseline이었다.
| 순위 | System | Model | Normalized reward | Normalized gain | Cost |
|---|---|---|---|---|---|
| 1 | ICL | Claude Sonnet 4.6 | 22.3 ± 4.1 | 25.4 ± 3.6 | $30.4 |
| 2 | ICL | GPT-5.4 | 20.1 ± 9.1 | 20.1 ± 9.1 | $18.4 |
| 3 | Claude Code | Sonnet 4.6 | 19.0 ± 7.1 | 23.9 ± 5.7 | $38.6 |
| 4 | Mem0 | GPT-5.4 | 15.1 ± 6.4 | 20.2 ± 5.9 | $18.3 |
| 5 | ICL | Claude Opus 4.7 | 10.2 ± 4.4 | 19.5 ± 4.1 | $49.6 |
| 7 | ICL | Gemini 3 Flash | 8.0 ± 4.7 | 16.4 ± 3.8 | $7.6 |
| 9 | ACE | GPT-5.4 | 4.6 ± 2.7 | 8.6 ± 2.5 | $62.8 |
| 10 | ICL Notepad | Claude Sonnet 4.6 | 3.5 ± 5.7 | 18.2 ± 3.4 | $31.5 |
ICL + Claude Sonnet 4.6은 normalized reward 22.3%, normalized gain 25.4%로 전체 1위다.
Claude Code + Sonnet 4.6도 gain 23.9%로 강하지만 비용은 더 높다.
Mem0는 GPT-5.4와 결합했을 때 gain 20.2%를 보였지만, 같은 GPT-5.4의 단순 ICL과 큰 격차를 만들지는 못했다.
ACE는 가장 높은 비용 축에 속하지만 aggregate gain은 낮았다.
이 결과를 “memory는 필요 없다”로 읽으면 너무 단순하다.
더 정확한 해석은 memory medium과 update policy가 성능을 좌우한다는 것이다.
같은 Sonnet 4.6을 써도 full-context ICL은 전체 1위지만, ICL Notepad는 gain은 어느 정도 만들면서 absolute reward는 낮다.
즉 agent가 스스로 요약·정리한 memory가 항상 원문 interaction history보다 좋은 것은 아니다.
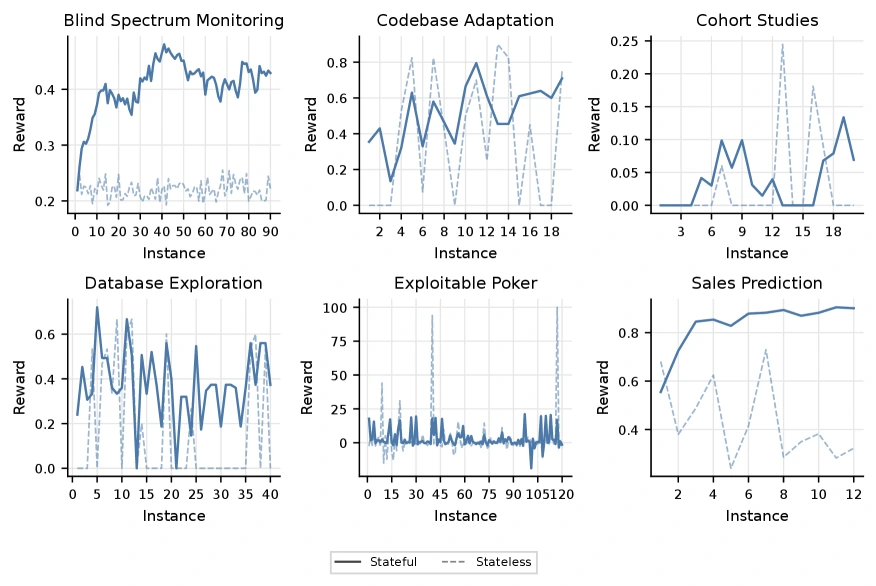
Task별 양상도 다르다.
Sales Prediction과 Blind Spectrum Monitoring은 learning gap이 비교적 뚜렷하다.
Database Exploration은 stateless reward가 자주 0으로 무너지는 반면 stateful run이 floor를 유지하면서 gain이 생긴다.
반대로 Cohort Studies는 두 curve 모두 낮게 머물러, 전문가가 learnable하다고 검증한 구조를 현재 system들이 충분히 추출하지 못한 사례로 해석된다.
안정성과 가소성: 기억을 유지하는 것과 새로 적응하는 것은 다르다
CL-Bench가 흥미로운 또 다른 이유는 gain을 stability와 plasticity로 나누어 보려 한다는 점이다.
Stability는 variant가 바뀌는 첫 instance에서 과거에 얻은 구조를 얼마나 잘 유지·전이하는지에 가깝다.
Plasticity는 같은 variant 안에서 새 feedback을 얼마나 빠르게 흡수하는지에 가깝다.
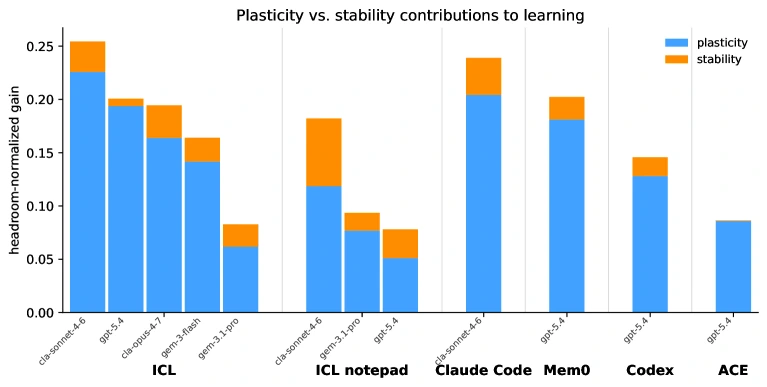
이 구분은 실제 agent runtime 설계에도 중요하다.
검색 기반 memory는 과거 정보를 많이 가져올 수 있지만, 오래된 정보가 drift 이후에도 계속 들어오면 해가 된다.
반대로 compaction-heavy agent는 새 정보에는 빠르게 반응하지만, 이전 variant에서 배운 유용한 구조를 잃을 수 있다.
CL-Bench는 이 두 실패를 “기억 품질”이라는 한 단어로 뭉개지 않고, 어디서 gain이 생기고 어디서 무너지는지 나눠 보려 한다.
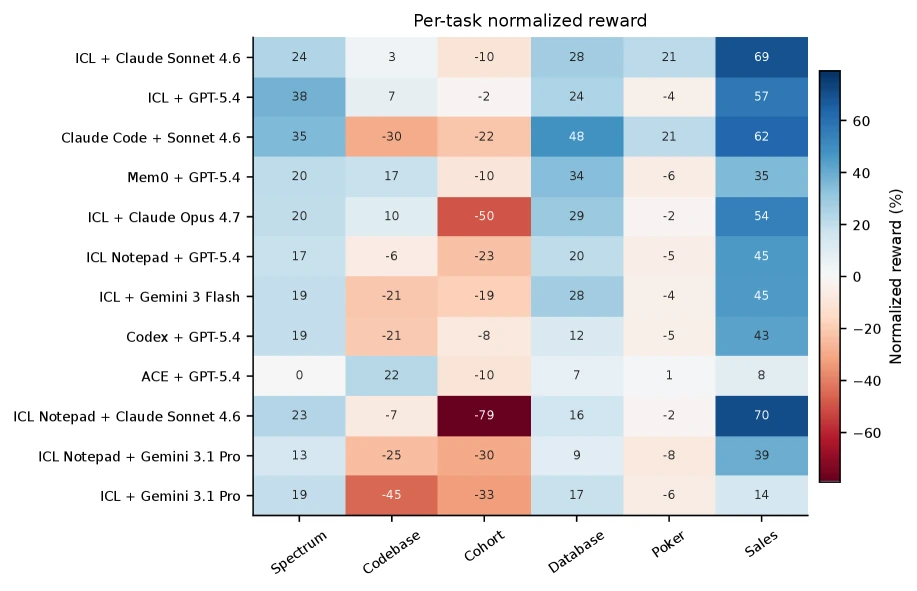
Per-task heatmap을 보면 system ranking이 한 줄로 정리되지 않는 것도 보인다.
Claude Code + Sonnet 4.6은 Database Exploration과 Poker/Sales에서 강하지만 Codebase Adaptation에서는 낮게 나온다.
Mem0는 Database Exploration에서 강한 축이지만 Poker에서는 약하다.
ICL Notepad + Claude Sonnet 4.6은 Sales Prediction에서는 매우 높지만 Cohort Studies에서는 크게 낮다.
실무 관점에서의 해석
CL-Bench의 가장 실용적인 메시지는 “memory feature를 붙였다”를 평가의 끝으로 보지 말라는 것이다.
많은 agent 제품은 vector store, episodic memory, scratchpad, summary compaction을 제공한다.
하지만 제품 관점에서 중요한 것은 memory object가 존재하는지가 아니라, 그 memory가 후속 task의 reward를 높이는지다.
Agent runtime을 평가한다면 최소한 다음 네 가지를 따로 봐야 한다.
- 같은 task sequence에서 stateful run과 stateless run을 비교한다.
- base model이 원래 잘해서 얻은 점수와 memory가 추가로 만든 gain을 분리한다.
- drift가 있을 때 오래된 기억을 버리거나 낮은 weight로 다루는지 본다.
- cost를 함께 본다. memory update, retrieval, compaction, tool trace 저장이 비싸면 gain이 좋아도 운영적으로 손해일 수 있다.
Hermes 같은 장기 실행 agent 관점에서도 이 논문은 좋은 기준선을 준다.
단순히 “메모리를 더 많이 저장하자”가 아니라, 어떤 memory가 다음 decision에 들어가야 하는지, 언제 삭제·요약·비활성화해야 하는지, 그리고 memory pipeline이 실제 task gain을 만드는지를 측정해야 한다.
특히 heartbeat, cron, 반복 연구 자동화처럼 긴 horizon을 갖는 시스템에서는 stability와 plasticity를 분리해서 보는 관점이 유용하다.
한계와 조심할 점
논문 스스로도 한계를 분명히 적는다.
CL-Bench는 여섯 도메인을 다루지만 실제 continual learning scenario 전체를 대표하지는 않는다. task horizon도 수십 instance 단위라, 실제 배포 환경의 몇 달짜리 memory lifecycle과는 거리가 있다.
이번 evaluation은 in-context retention, compaction, retrieval memory, structured notepad 같은 context 기반 memory paradigm에 집중하고, test-time training 같은 parametric adaptation은 평가하지 않는다.
또 하나는 비용과 재현성이다.
CL-Bench는 frontier-level model이 아니면 비영점 성능을 내기 어렵게 설계되어 있고, task에 따라 Docker, persistent terminal, provider API, benchmark viewer까지 필요하다.
공개 repo가 Apache-2.0이고 docs가 잘 마련되어 있다는 점은 장점이지만, tags/release가 아직 없는 초기 연구 아티팩트라는 점도 감안해야 한다.
따라서 CL-Bench 결과는 “ICL이 모든 memory system보다 항상 낫다”가 아니라, 현재 공개된 frontier agent memory 방식이 아직 online learning을 안정적으로 해결하지 못한다는 신호로 읽는 편이 정확하다.
특히 dedicated memory system이 단순 context carry-over를 이기지 못했다는 결과는 agent engineering에서 꽤 중요한 경고다.
결론적으로 CL-Bench는 에이전트 평가의 질문을 한 단계 옮긴다.
“이 모델이 답을 잘하는가”에서 “이 시스템이 경험을 성능으로 바꾸는가”로.
장기 실행 agent가 실제 제품이 되려면 memory는 feature list가 아니라 measurable learning gain으로 증명되어야 한다.
CL-Bench는 그 증명을 요구하는 첫 번째 강한 벤치마크 중 하나로 볼 만하다.