로컬 LLM을 돌릴 때 가장 먼저 막히는 질문은 “이 모델이 좋은가?”
보다 내 GPU에 일단 들어가는가일 때가 많다.
7B 모델은 대충 감으로 잡을 수 있지만, 32B/70B급 모델, 긴 컨텍스트, 여러 동시 사용자, MoE 모델, LoRA/QLoRA 파인튜닝까지 들어가면 단순히 파라미터 수 × bytes만으로는 금방 빗나간다.
APXML VRAM Calculator는 이 초기 의사결정을 빠르게 줄여 주는 웹 도구다.
모델, 양자화, KV 캐시 정밀도, GPU 또는 커스텀 VRAM, GPU 수, 배치 크기, 시퀀스 길이, 동시 사용자 수를 넣으면 예상 VRAM 사용량, 생성 속도, TTFT, throughput을 한 화면에서 보여준다.
설치나 계정 없이 브라우저에서 바로 열 수 있다는 점이 장점이다.
조사 시점 기준 이 도구는 ApX Machine Learning 웹사이트의 일부로 제공되며, ApX의 공개 GitHub 조직에는 kerb, jton-evolve 같은 저장소는 있지만 VRAM Calculator 자체의 공개 소스 저장소는 확인되지 않았다.
따라서 오픈소스 라이브러리 리뷰라기보다, 하드웨어·모델 선택 전에 써볼 만한 무료 웹 계산기로 보는 편이 맞다.
무엇을 계산해 주나
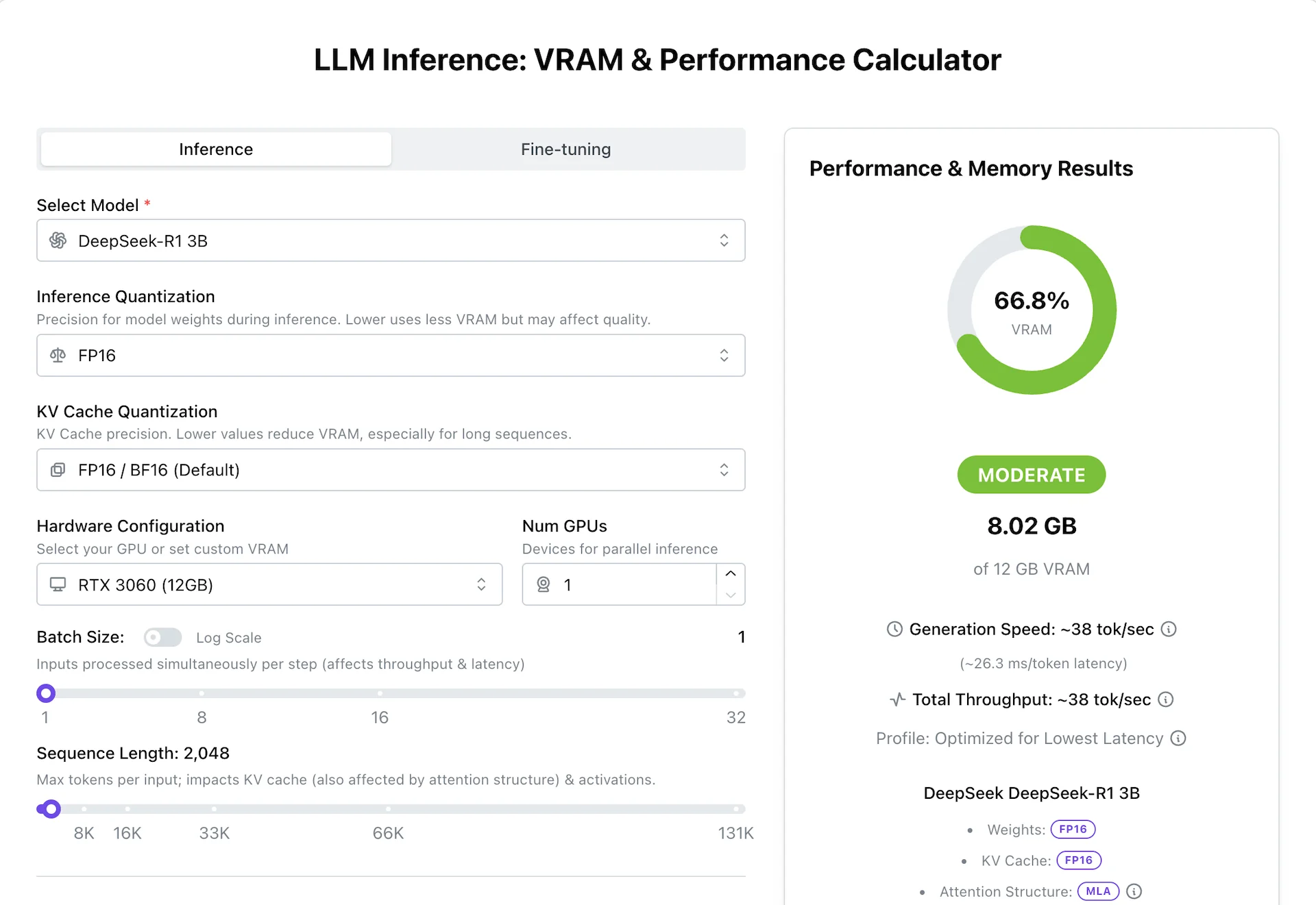
APXML 계산기의 핵심 화면은 왼쪽 입력 패널과 오른쪽 결과 패널로 나뉜다.
입력 쪽에서는 먼저 Inference와 Fine-tuning 중 하나를 고른다.
추론 모드에서는 모델, weight quantization, KV cache quantization, GPU/VRAM, GPU 수, batch size, sequence length, concurrent users, CPU/RAM 또는 NVMe offloading 여부를 조합한다.
결과 쪽에서는 다음 값들을 한 번에 보여준다.
- 예상 VRAM 사용량과 전체 VRAM 대비 비율
- Ready / Moderate 같은 적합도 상태
- generation speed, ms/token latency, total throughput
- time to first token 추정
- 현재 계산에 쓰인 모델, weight precision, KV cache precision, attention structure 요약
공식 설명에 따르면 메모리 추정은 모델의 파라미터 수뿐 아니라 layer 수, hidden dimension, active experts, attention 구조, 양자화, 시퀀스 길이, 배치 크기를 함께 고려한다.
성능 추정은 모델·하드웨어 분석과 벤치마크 기반 scaling을 섞지만, 페이지 자체도 “approximate”라고 못박는다.
왜 유용한가
이 도구가 특히 좋은 지점은 KV cache와 운영 파라미터를 눈에 보이게 만든다는 점이다.
로컬 LLM 입문자에게 VRAM은 보통 모델 weight 크기로만 설명되지만, 실제로는 긴 컨텍스트와 동시 사용자 수가 KV cache를 키우고, batch size가 throughput과 latency를 동시에 흔든다.
계산기에서 sequence length를 2K에서 32K, 128K로 올려 보면 어떤 모델이 갑자기 GPU 밖으로 밀려나는지 바로 보인다.
또 하나는 weight quantization과 KV cache quantization을 분리한 점이다.
모델 weight를 Q4로 낮춰도 KV cache를 FP16으로 유지하면 긴 컨텍스트에서 메모리가 다시 커질 수 있다.
반대로 KV cache를 낮추면 긴 문맥에서는 효과가 크지만 품질·속도·런타임 지원 여부가 따라붙는다.
이런 trade-off를 표나 글로만 읽는 것보다 슬라이더로 바꿔 보는 쪽이 빠르다.
Fine-tuning 탭도 실용적이다.
Full fine-tuning, LoRA, QLoRA는 필요한 메모리의 스케일이 다르다.
APXML의 업데이트 로그에는 fine-tuning batch size scaling, gradient accumulation, training cost estimation 관련 수정이 이어지고 있어, 단순 추론 계산기보다는 “이 모델을 내 장비에서 조정까지 해볼 수 있나?”
를 빠르게 가늠하는 용도로도 쓸 수 있다.
첫 사용 흐름
가장 안전한 사용 순서는 다음과 같다.
- 실행하려는 모델을 선택한다. 목록형 도구이므로 임의 Hugging Face ID를 넣는 범용 importer라기보다는, APXML이 수집한 모델 메타데이터 안에서 고르는 방식에 가깝다.
- 먼저 weight quantization을 실제 런타임 계획에 맞춘다. Ollama에서 흔히 쓰는 Q4 계열과 FP16 benchmark 기준은 VRAM 차이가 크다.
- 긴 문맥을 쓸 계획이면 KV cache quantization과 sequence length를 먼저 바꿔 본다.
- GPU preset이 있으면 선택하고, 없으면 custom VRAM으로 대략적인 fit 여부만 확인한다.
- batch size와 concurrent users를 운영 목표에 맞춘다. 1인 로컬 채팅인지, 여러 요청을 받는 inference endpoint인지에 따라 결과가 달라진다.
Enable Offloading to CPU/RAM or NVMe는 “돌아가게 만들 수 있는가”를 볼 때만 켜고, latency가 중요하면 실제 런타임에서 별도로 측정한다.
설치 명령은 없다.
브라우저에서 바로 연다.
https://apxml.com/tools/vram-calculator
해석할 때 주의할 점
첫째, 결과를 구매 결정의 최종 숫자로 보지는 않는 편이 좋다.
APXML FAQ도 드라이버 오버헤드, CUDA kernel 구현, framework별 memory-saving 최적화, 세부 아키텍처 차이 때문에 GB 단위로 딱 맞는 계산기는 아니라고 설명한다.
하드웨어 후보를 좁히는 ballpark로 쓰고, 최종 결정 전에는 실제 런타임에서 cold start, prefill, long-context, multi-user 부하를 확인해야 한다.
둘째, 기본값과 내가 실제로 쓸 runtime 기본값이 다를 수 있다.
APXML은 FAQ에서 Ollama가 많은 모델에 기본적으로 Q4 계열 양자화를 쓰는 반면, 계산기 기본은 FP16 기준이라 VRAM 요구량이 더 높게 보일 수 있다고 설명한다.
“왜 내 Ollama에서는 돌아가는데 계산기는 안 된다고 하지?”
라는 상황에서는 quantization 설정부터 맞춰야 한다.
셋째, MoE 모델은 compute와 memory를 헷갈리기 쉽다.
FAQ는 MoE가 토큰당 활성 expert를 줄여 compute 효율을 얻을 수 있지만, 빠른 expert switching을 위해 전체 expert weight는 메모리에 올라와야 한다고 설명한다.
따라서 MoE라고 해서 무조건 VRAM이 적게 든다고 가정하면 안 된다.
넷째, 웹 도구라는 점도 기억해야 한다.
Terms는 사이트와 콘텐츠를 APX MACHINE LEARNING TECHNOLOGIES 또는 그 라이선서의 지식재산으로 설명하고, Privacy Policy는 IP, 브라우저, 방문 페이지 같은 derivative data 및 Google Analytics 등 service provider 사용을 언급한다.
모델명·GPU 구성 자체가 대개 민감 정보는 아니지만, 사내 하드웨어 계획이나 고객 프로젝트 정보를 URL 공유 링크나 페이지 내 챗봇에 그대로 넣는 것은 피하는 편이 안전하다.
내 판단
APXML VRAM Calculator는 로컬 LLM을 자주 만지는 사람에게 “즐겨찾기 해둘 만한 계산기”에 가깝다.
특히 GPU를 사기 전, 24GB 단일 카드와 48GB/80GB 카드 사이에서 고민할 때, 또는 Q4/Q8/FP16과 context length를 바꿔 보며 후보 모델을 줄일 때 유용하다.
다만 이 도구 하나로 production capacity planning을 끝내면 안 된다.
실제 throughput은 runtime, prompt 길이 분포, CUDA/Metal/ROCm backend, offloading, batching scheduler, speculative decoding, memory fragmentation에 크게 좌우된다.
내 추천은 APXML로 1차 fit 여부와 위험 구간을 찾고, 최종 후보 2~3개는 실제 스택에서 benchmark하는 방식이다.