멀티모달 모델 경쟁은 두 방향으로 동시에 갈라지고 있다.
한쪽에서는 초대형 폐쇄 모델이 이미지, 비디오, 문서, 브라우징, 도구 호출을 한꺼번에 품으려 한다.
다른 한쪽에서는 공개 가중치 모델이 “충분히 작은 활성 파라미터로 어디까지 reasoning과 grounding을 끌어낼 수 있는가”를 묻는다.
ERNIE-4.5-VL-28B-A3B-Thinking은 후자에 가까운 릴리스다.
Baidu의 모델 카드는 이 모델을 ERNIE-4.5-VL-28B-A3B 아키텍처 위에 reasoning 중심 mid-training과 multimodal reinforcement learning을 얹은 Thinking 변형으로 소개한다.
이름의 28B-A3B가 말하듯 전체 모델은 28B급 VLM이지만, MoE 경로에서 활성화되는 파라미터는 약 3B 규모다.
Hugging Face API가 노출하는 safetensors 총량은 약 29.66B parameters이고, repo는 image-text-to-text pipeline, custom_code, 영어·중국어 태그, Apache-2.0 라이선스를 함께 공개한다.
이 릴리스의 흥미로운 점은 단순히 “작은 활성 파라미터로 높은 점수를 냈다”가 아니다.
모델 카드, config, tokenizer template, vLLM/FastDeploy 사용 예제를 함께 보면 이 모델은 이미지와 비디오를 읽고, <think> reasoning 블록을 만들고, tool call parser와 reasoning parser를 통해 멀티모달 agent surface로 이어지는 방향을 명확히 잡고 있다.
즉 ERNIE-4.5-VL-Thinking은 VLM 벤치마크 모델이면서 동시에 시각 도구 사용형 agent의 공개 부품으로 읽어야 한다.
무엇을 해결하려는가
ERNIE-4.5-VL-Thinking이 겨냥하는 병목은 고난도 시각 reasoning을 무조건 더 큰 dense VLM으로만 푸는 방식이다.
이미지 기반 수학·과학 문제, 차트·문서 이해, grounding, 비디오 이벤트 파악은 단순 captioning보다 훨씬 비싸다.
입력 자체가 크고, 모델은 시각 detail을 잃지 않으면서도 여러 단계의 추론을 해야 하며, 실제 agent workflow에서는 필요하면 특정 영역을 확대하거나 외부 검색 도구를 불러야 한다.
Baidu는 ERNIE 4.5 technical report와 공개 블로그에서 이 문제를 heterogeneous multimodal MoE로 접근한다.
텍스트와 비전 토큰을 같은 self-attention 흐름에서 다루되, expert는 modality별로 분리하고 shared expert를 함께 둔다.
목표는 한 modality가 다른 modality를 망가뜨리는 cross-modal interference를 줄이면서도, 텍스트·이미지·비디오가 같은 모델 family 안에서 reasoning 능력을 공유하게 만드는 것이다.
Thinking 변형은 그 위에 한 단계 더 얹힌다.
모델 카드에 따르면 이 버전은 대규모 visual-language reasoning 데이터로 mid-training을 거쳤고, verifiable task 기반 multimodal RL, GSPO와 IcePop 전략, dynamic difficulty sampling을 사용해 MoE training을 안정화했다고 설명된다.
공개 카드만으로 각 기법의 ablation을 검증할 수는 없지만, 릴리스가 강조하는 방향은 분명하다.
작은 활성 파라미터의 VLM을 단순 질의응답 모델이 아니라, 시각 추론·grounding·도구 사용이 가능한 reasoning model로 끌어올리려는 시도다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 이 모델은 ERNIE 4.5 계열의 3B-active VLM이다. config.json은 Ernie4_5_VLMoeForConditionalGeneration 아키텍처와 ernie4_5_moe_vl model type을 노출한다.
텍스트 쪽은 hidden size 2560, 28 layers, attention heads 20, KV heads 4, 131,072 max position embeddings를 가진다.
MoE 설정은 64개 expert 그룹 두 축, top-k 6 routing, shared experts 2개를 포함한다. technical report의 설명과 맞춰 보면 text expert와 vision expert를 나누고 shared expert를 더하는 heterogeneous MoE 구조로 읽힌다.
비전 경로도 config에 직접 드러난다. vision encoder는 hidden size 1280, depth 32, 16 heads, patch size 14를 사용하고, image/video start/end token ID와 placeholder token을 별도로 둔다. tokenizer template은 이미지 입력을 Picture N:<|IMAGE_START|><|image@placeholder|><|IMAGE_END|> 형태로, 비디오 입력을 Video N:<|VIDEO_START|><|video@placeholder|><|VIDEO_END|> 형태로 렌더링한다.
비디오 subtitle이 들어오면 ASR time span도 template에 포함할 수 있게 되어 있다.
Thinking 모드는 chat template에서 더 명시적이다.
기본 thinking_mode는 true로 설정되어 있고, assistant 메시지는 <think>...</think> 블록을 포함할 수 있다.
도구가 주어지면 <tool_list>, <tool_call>, <tool_output> 포맷도 template 안에 들어간다.
FastDeploy 문서는 image_zoom_in_tool 예제를 통해 특정 bbox를 확대하는 도구 호출을 설명하고, model card의 vLLM 예제도 --reasoning-parser ernie45, --tool-call-parser ernie45, --enable-auto-tool-choice 옵션을 함께 제시한다.
이 구조는 “이미지를 보고 답한다”보다 “이미지를 보며 생각하고, 필요한 경우 시각 도구를 부른다”는 사용 패턴에 가깝다.
| 축 | 공개 자료에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| 모델 규모 | 이름상 28B total / 3B active, HF safetensors API 기준 약 29.66B parameters | dense 30B급 비용을 매 토큰 전부 쓰지 않는 MoE VLM |
| 컨텍스트 | max_position_embeddings 131,072 |
긴 문서·비디오 metadata·도구 trace를 함께 넣을 수 있는 128K급 surface |
| 비전 경로 | 32-layer vision encoder, hidden size 1280, patch size 14 | 이미지·비디오 입력을 전용 token과 processor로 다룸 |
| 추론 포맷 | <think>, image/video placeholder, tool call/output template |
reasoning trace와 multimodal tool-use를 전제로 한 chat format |
| 배포 표면 | Transformers, vLLM, FastDeploy, ERNIEKit SFT/function-call training | 단일 model card가 아니라 inference와 fine-tuning toolkit까지 연결 |
| 라이선스 | HF card/API와 GitHub repo 모두 Apache-2.0 | 상업 사용 가능성이 높은 공개 가중치 릴리스이지만 license terms 확인은 필요 |
공개된 근거에서 확인되는 점
첫째, Hugging Face repo는 모델의 실제 packaging surface를 꽤 많이 노출한다.
확인 시점의 API 기준 repo는 2025-11-07 생성, 2026-03-06 마지막 수정, gated false, downloads 1,426, likes 539로 표시된다.
파일은 29개 safetensors shard와 index, config.json, generation_config.json, preprocessor_config.json, tokenizer 파일, custom modeling/configuration/processing Python 파일, 그리고 benchmark.jpg를 포함한다. usedStorage는 약 59.35GB로, “3B active”라고 해도 다운로드·배포 관점에서는 여전히 대형 모델에 속한다.
둘째, ERNIE 4.5 family 자체는 technical report와 GitHub repo에서 더 넓게 설명된다.
ERNIE 4.5는 language-only와 vision-language 모델 10종을 포함하고, 47B active와 3B active MoE 축, 0.3B dense 축을 함께 둔다. technical report는 multimodal heterogeneous MoE, modality-isolated routing, shared attention, text/vision-specific experts를 핵심으로 설명하며, 가장 큰 언어 모델 pretraining에서 2016 NVIDIA H800 GPU 기준 47% MFU를 보고한다.
이 수치는 Thinking 모델만의 성능이 아니라 ERNIE 4.5 family 설계의 배경 근거다.
셋째, 성능 figure는 강한 marketing signal이지만 조심해서 읽어야 한다.
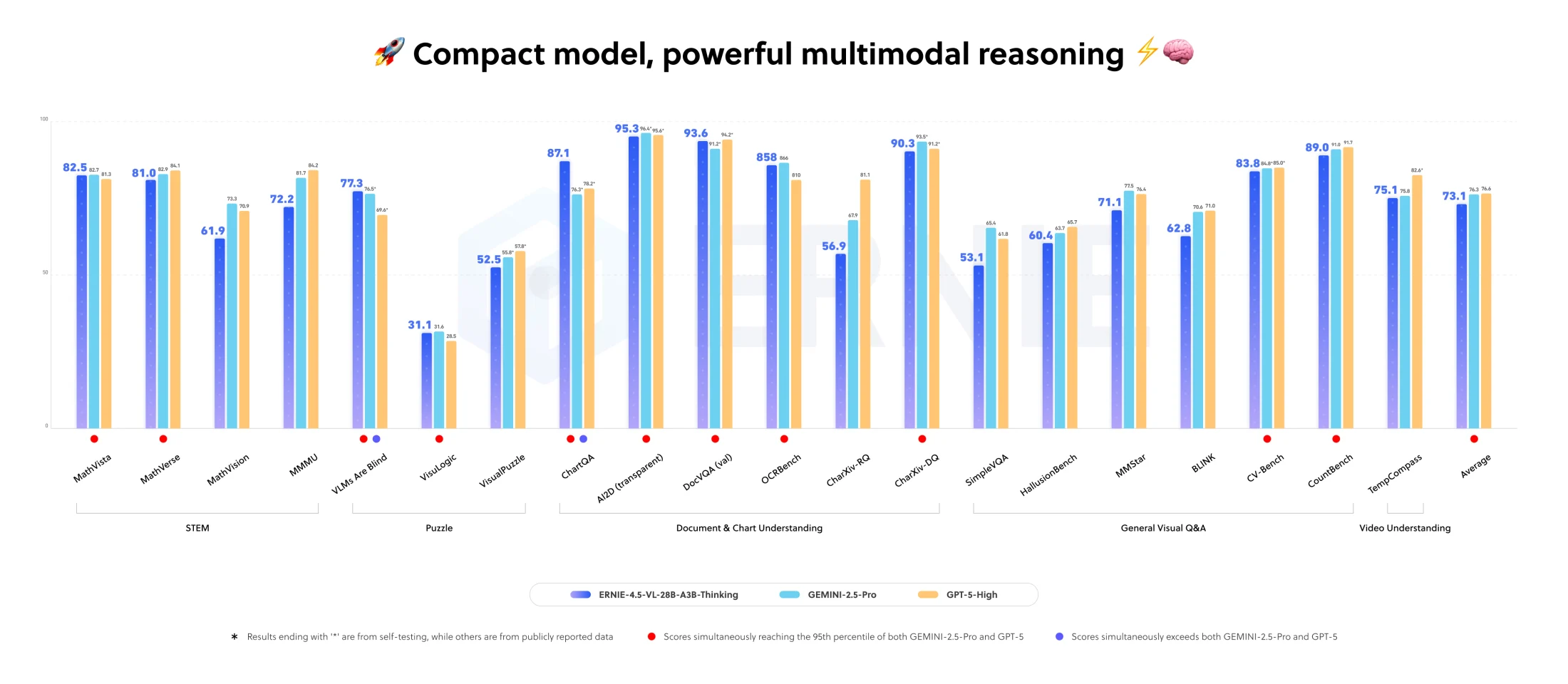
모델 카드의 benchmark 이미지는 ERNIE-4.5-VL-28B-A3B-Thinking을 Gemini 2.5 Pro와 GPT-5 High와 나란히 놓고 STEM puzzle, document & chart understanding, general visual Q&A, video understanding 항목을 비교한다.
OCR로 확인되는 figure 구조상 ERNIE는 여러 항목에서 90%대 또는 80%대 수치를 제시하고, 하단 주석은 *가 붙은 값이 self-testing 결과임을 밝힌다.
따라서 블로그 관점에서 안전한 해석은 “공식 figure가 frontier closed model과의 근접성을 주장한다”이지, 독립 leaderboard에서 검증된 절대 우위라고 말하는 것은 아니다.
넷째, 배포 경로는 넓지만 가볍지는 않다.
모델 카드의 Transformers 예제는 trust_remote_code=True, BF16, transformers <= 4.57.6 요구사항을 적는다. vLLM 예제는 vllm==0.11.2, 80GB GPU 1장을 기준으로 서버를 띄우며, video understanding에는 timestamp rendering 관련 vLLM PR 포함 버전을 요구한다.
FastDeploy 문서는 Linux x86_64, CUDA 12.3 이상, CUDNN 9.5 이상, Python 3.10 이상, 80G A/H 1 GPU를 hardware requirement로 적고, model card에는 single-card deployment에 최소 48GB GPU memory가 필요하다는 별도 주석도 있다.
즉 3B active는 추론 compute를 줄이는 신호지만, 이 모델을 노트북급 로컬 VLM처럼 읽으면 안 된다.
다섯째, 훈련·튜닝 도구와도 연결되어 있다.
PaddlePaddle/ERNIE GitHub repo는 default branch가 release/v1.5이고, 확인 시점 기준 stars 7,717, forks 1,446, Apache-2.0 license를 가진다.
README의 2025-11 업데이트는 ERNIEKit v1.5가 ERNIE-4.5-VL-28B-A3B-Thinking의 SFT training과 function call training을 지원한다고 밝힌다.
FastDeploy 문서는 OpenAI-compatible API server, image/video input, tool call 입력 예제를 제공한다.
따라서 이 모델은 “가중치만 공개된 연구 산출물”이라기보다 PaddlePaddle 생태계의 training·serving stack으로 묶어 내보낸 release에 가깝다.
실무 관점에서의 해석
내가 보기에 ERNIE-4.5-VL-Thinking의 핵심은 활성 파라미터 효율과 multimodal agent interface를 같은 모델 카드에서 만난다는 점이다.
오픈 VLM 릴리스는 흔히 두 부류로 나뉜다.
하나는 benchmark table 중심의 모델이고, 다른 하나는 demo/app 중심의 모델이다.
ERNIE-4.5-VL-Thinking은 양쪽을 모두 의식한다.
공식 figure는 frontier model과의 성능 근접성을 말하고, tokenizer/FastDeploy/vLLM 예제는 reasoning parser, tool-call parser, image zoom tool까지 이어지는 agent surface를 보여 준다.
실무적으로는 문서·차트 분석, 공장/현장 이미지 QA, 스크린샷 기반 업무 자동화, 동영상 구간 이해, 시각 grounding이 필요한 internal tool에 매력적인 후보가 될 수 있다.
특히 Apache-2.0 공개 가중치와 128K context, SFT/function-call training 지원은 조직 내부 데이터로 맞춤형 VLM을 만들려는 팀에게 중요한 요소다.
“이미지로 생각하고 도구를 부른다”는 방향은 단순 OCR pipeline보다 복잡한 작업 자동화에 더 잘 맞는다.
하지만 adoption decision에서는 비용과 검증을 분리해야 한다.
첫째, repo storage가 59GB 이상이고 vLLM/FastDeploy 예제가 고메모리 GPU를 요구하므로, 실제 운영 비용은 small active parameter라는 이름만큼 작지 않다.
둘째, model card의 Thinking-specific training 설명은 흥미롭지만, 각 기법이 어느 benchmark에 얼마만큼 기여했는지 공개 ablation은 제한적이다.
셋째, 공식 benchmark figure에는 self-testing 값이 포함되어 있으므로, 도메인별 문서·영상·grounding task에서는 별도 holdout 평가가 필요하다.
그럼에도 이 릴리스는 볼 가치가 크다.
ERNIE 4.5는 heterogeneous multimodal MoE라는 구조적 방향을 제시했고, Thinking variant는 그 위에 reasoning, grounding, tool use를 얹어 공개 VLM의 사용 범위를 agent workflow 쪽으로 넓힌다.
앞으로 오픈 멀티모달 모델 경쟁의 중요한 축은 단순히 “몇 B 모델이 몇 점을 받았는가”가 아니라, 활성 파라미터 예산, 긴 컨텍스트, 시각 도구 사용, 배포 프레임워크, fine-tuning surface가 한 패키지로 얼마나 잘 맞물리는가가 될 것이다.
ERNIE-4.5-VL-28B-A3B-Thinking은 그 질문에 대한 Baidu의 꽤 공격적인 답안이다.