멀티모달 모델이 이미지를 “이해”하는 것과 실제로 픽셀 단위 마스크를 안정적으로 뽑아내는 것은 전혀 다른 문제다.
지금까지의 흐름을 보면 SAM 계열은 분할 품질은 뛰어나지만 대화형 텍스트 지시를 자연스럽게 해석하지 못했고, 반대로 segmentation MLLM들은 언어 지시를 받을 수 있어도 이미지 전용이거나 비디오 전용인 경우가 많았다.
결국 실무에서 남는 빈칸은 하나였다.
텍스트와 시각 프롬프트를 둘 다 받으면서, 이미지와 비디오를 같은 인터페이스로 다루는 범용 분할 모델이 있느냐는 질문이다.
X2SAM: Any Segmentation in Images and Videos는 바로 그 빈칸을 메우려는 시도다.
저자들은 X2SAM을 단순한 “SAM + LLM 접합”이 아니라, 이미지용 any-segmentation을 비디오까지 확장하는 통합 segmentation MLLM으로 제시한다.
핵심은 세 가지다.
첫째, 텍스트 프롬프트와 시각 프롬프트를 모두 받는다.
둘째, generic/open-vocabulary/referring/reasoning/interactive/grounded conversation generation/visual grounded segmentation을 하나의 모델 안에서 처리한다.
셋째, 비디오에서 시간축 일관성을 유지하기 위해 Mask Memory를 붙였다.
내가 보기엔 이 논문의 진짜 의미는 “또 하나의 segmentation 모델”이 아니라, 이미지와 비디오를 따로 쪼개서 발전해 온 segmentation MLLM 계보를 하나의 제품형 표면으로 통합하려 한다는 데 있다.

무엇을 해결하려는가
X2SAM이 겨냥하는 문제는 기존 segmentation 스택의 이중 단절이다.
하나는 프롬프트 단절이다.
SAM/SAM2 같은 foundation segmentation 모델은 point, box 같은 저수준 visual prompt에는 강하지만, “오른쪽 사람의 모자만 골라 달라”나 “다른 사람과 연락할 수 있는 물체를 찾아 달라” 같은 언어 지시를 네이티브하게 처리하지 못한다.
다른 하나는 모달리티 단절이다.
LISA, X-SAM 같은 이미지 segmentation MLLM은 정지 이미지에서는 꽤 강하지만 비디오 추적까지 자연스럽게 이어지지 않고, VISA나 VideoLISA 같은 비디오 계열은 이미지와 visual prompt를 하나의 통합 인터페이스로 가져오지 못했다.
논문은 이 문제를 꽤 명확하게 정의한다.
좋은 segmentation MLLM이라면 이제 단순히 “이미지에서 mask를 뽑는다”가 아니라 다음을 동시에 만족해야 한다.
- 이미지와 비디오를 함께 다룰 것
- 텍스트 프롬프트와 시각 프롬프트를 함께 받을 것
- referring / reasoning / open-vocabulary / interactive segmentation을 같은 인터페이스로 묶을 것
- 분할만 잘하는 모델이 아니라 기본적인 image/video chat 능력도 유지할 것
특히 흥미로운 점은 저자들이 새로 제안한 V-VGD(Video Visual Grounded) segmentation benchmark다.
이 벤치마크는 사용자가 시각적으로 지정한 region을 비디오 전체에서 추적·분할할 수 있는지를 본다.
즉 “픽셀 분할”과 “비디오 grounding” 사이의 실제 제품형 과제를 더 직접적으로 측정한다.
이 설정 덕분에 X2SAM은 단순히 기존 이미지 벤치마크를 비디오로 옮겨온 수준이 아니라, 비디오 인터랙션 관점의 새 평가 축까지 만들었다.
핵심 아이디어 / 구조 / 동작 방식
X2SAM의 구조는 크게 네 조각으로 읽는 편이 이해가 쉽다.
Vision Encoder가 전역 시각 표현을 뽑고, Mask Encoder가 더 세밀한 분할용 feature를 잡고, LLM이 언어 응답과 latent condition embedding을 만들고, Mask Decoder가 최종 segmentation mask를 생성한다.
여기에 비디오용 확장으로 들어가는 것이 Mask Memory다.
이전 프레임의 guided vision feature를 저장해 두고 현재 프레임의 분할 생성에 참조시키는 방식이라, 프레임마다 새로 segmentation을 하는 대신 시간적 일관성을 확보하려는 설계다.

이 구조에서 중요한 포인트는 단순히 메모리를 “붙였다”는 사실보다, 언어 조건과 분할 feature를 비디오 시간축 위에서 함께 다룬다는 점이다.
논문 설명대로라면 LLM은 language response뿐 아니라 segmentation을 유도하는 latent condition embedding도 만들고, Mask Decoder는 이를 바탕으로 현재 프레임 마스크를 생성한다.
Memory Attention은 과거 프레임의 guided feature를 참조하고, Memory Bank는 FIFO 방식으로 이를 관리한다.
즉 텍스트-시각 정렬과 비디오 추적을 별도 파이프라인으로 나누지 않고 하나의 통합 모델 내부에서 처리하려는 셈이다.
또 하나 주목할 점은 joint training 전략이다.
X2SAM은 이미지와 비디오, 그리고 여러 segmentation task를 따로따로 specialist로 학습시키는 대신 하나의 unified training 전략으로 엮는다.
논문 부록의 데이터셋 표를 보면 image chat, generic segmentation, open-vocabulary segmentation, referring segmentation, reasoning segmentation, GCG, interactive segmentation, visual grounded segmentation, 그리고 비디오 쪽 대응 task까지 아주 넓게 커버한다.
이 때문에 X2SAM의 가치는 어느 한 벤치마크의 SOTA보다, 한 모델로 얼마나 넓은 task surface를 커버하느냐에서 읽는 편이 더 정확하다.
| 구성 요소 | 논문/프로젝트에서 확인되는 역할 | 실무적 의미 |
|---|---|---|
| Vision Encoder | 전역 visual representation 추출 | chat 능력과 segmentation 전반의 공통 시각 백본 |
| Mask Encoder | 더 세밀한 분할용 visual feature 인코딩 | pixel-level mask 품질 유지 |
| LLM | 언어 응답 + latent condition embedding 생성 | 대화형 텍스트 지시를 segmentation 조건으로 변환 |
| Mask Decoder | 최종 segmentation mask 생성 | 다양한 task를 동일 출력 형식으로 수렴 |
| Mask Memory | 과거 프레임 guided feature 저장 및 참조 | 비디오 분할의 시간적 일관성 확보 |
| Unified joint training | 이미지/비디오/여러 segmentation task 동시 학습 | specialist를 여러 개 붙이지 않고 제품 표면 단순화 |
프로젝트 공개 상태도 꽤 괜찮다.
GitHub 저장소에는 training, evaluation, visualization, demo 코드가 함께 올라와 있고, README는 전체 폴더 구조, conda 환경, Deformable-Attention 컴파일, 분산 학습, evaluation, visualization, model conversion, demo까지 비교적 자세히 적어 두었다.
프로젝트 페이지, Hugging Face 체크포인트, 데모 링크까지 연결돼 있어 단순한 논문 저장소보다는 “바로 만져 볼 수 있는 연구 코드 패키지”에 가깝다.
공개된 근거에서 확인되는 점
가장 먼저 눈에 띄는 건 task coverage다.
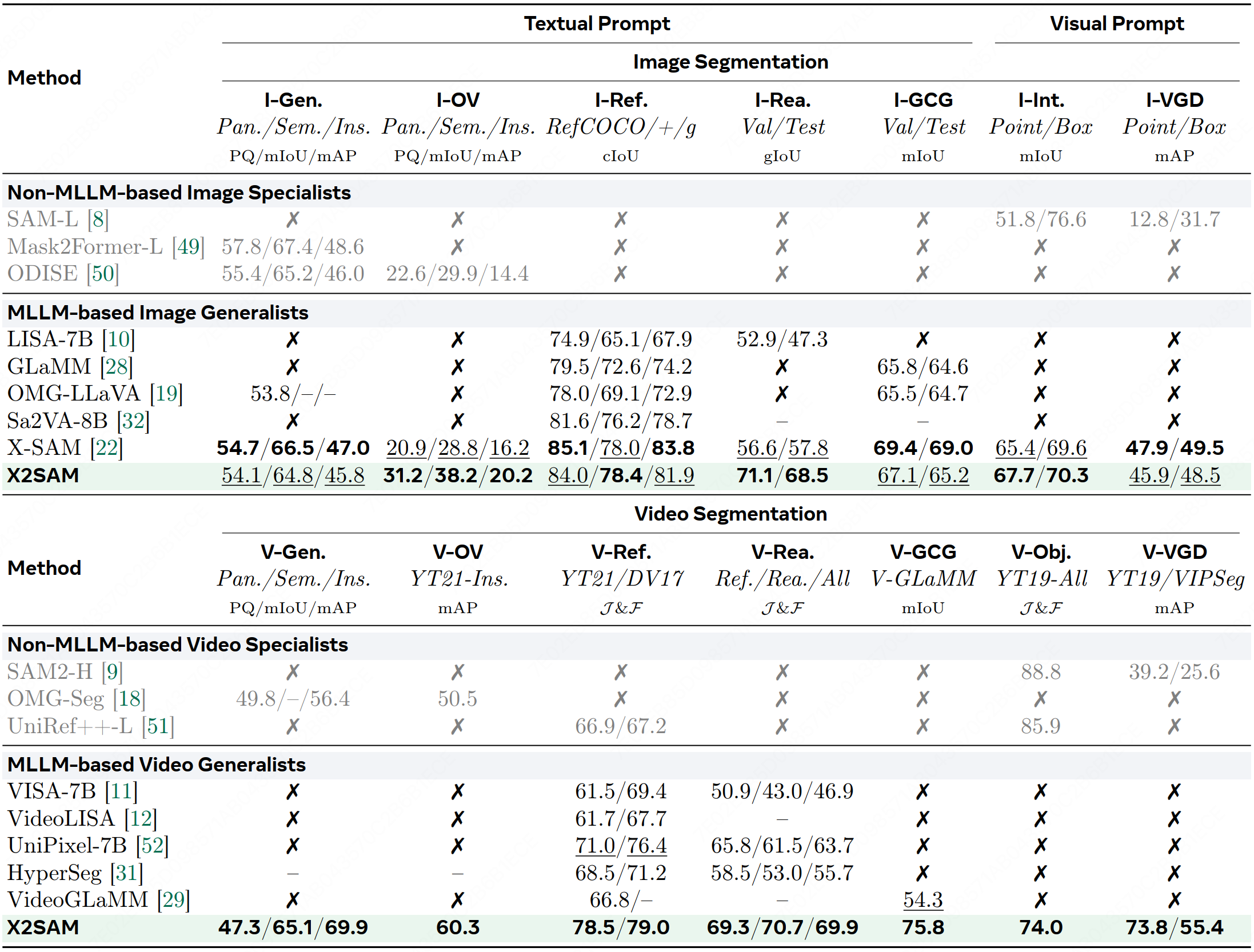
Table 1 기준으로 X2SAM은 이미지/비디오 입력, 텍스트/시각 프롬프트, text/mask 출력, image/video chat, image segmentation 7종, video segmentation 7종을 모두 지원하는 유일한 항목으로 제시된다.
HyperSeg는 video segmentation task 수가 4개, X-SAM은 0개, 기존 chat-based MLLM은 segmentation task가 0개다.
이 논문의 1차 메시지는 점수 이전에 바로 여기 있다.
모든 task를 한 모델로 묶었다는 것이다.
성능 쪽에서는 특히 비디오 관련 항목이 강하다.
Table 9의 visual grounded segmentation에서 X2SAM은 새로 제안한 V-VGD 계열에서 높은 수치를 낸다.
예를 들어 YT-VIS19 기준 point/box prompt에서 각각 73.8/93.5, 74.4/93.9를 기록했고, VIPSeg 기준 point/box에서는 55.5/75.4, 57.8/78.3을 보인다.
이는 SAM2-H가 같은 비디오 VGD 축에서 39.2/53.5, 54.0/73.3, 25.6/36.3, 40.4/54.7 수준인 것과 비교하면 상당히 큰 차이다.
다시 말해 X2SAM은 단순히 “텍스트도 이해하는 SAM”이 아니라, visual prompt 기반 비디오 grounding/segmentation을 실제 강점 축으로 가져간다.
Reasoning segmentation에서도 수치가 눈에 띈다.
Table 7 기준 X2SAM은 image reasoning segmentation에서 64.5/71.1, 53.5/60.0, 66.7/68.9, 65.6/68.5를 기록하고, video reasoning segmentation에서는 66.2/72.4/69.3, 67.5/74.0/70.3, 66.7/73.0/69.9를 보인다.
비교군인 HyperSeg의 video reasoning overall 55.7, VISA의 46.9, LISA의 40.9보다 확실히 높다.
즉 X2SAM은 단순한 object mask 생성보다, 언어 지시가 조금 더 추론적일 때 얻는 이점이 큰 편으로 읽힌다.
Out-of-domain과 open-vocabulary 항목도 흥미롭다.
Table 8에서 X2SAM은 gRefCOCO 기준 63.1/68.1, 67.3/71.2, 63.4/66.7을 기록하고, A150 open-vocabulary segmentation에서 31.2 PQ, 38.2 mIoU, 20.2 mAP, 그리고 YT-VIS-21 video open-vocabulary 인스턴스 분할에서 60.3/78.0을 보인다.
X-SAM이 강한 image referring/generalized referring 능력을 유지하는 반면 비디오 open-vocabulary 쪽은 비어 있는 것과 달리, X2SAM은 image-video 통합성을 더 중요하게 가져간 설계라고 볼 수 있다.
한편 image-only specialist와 비교하면 절대 최고는 아니다.
예를 들어 generic image segmentation이나 일부 referring segmentation에서는 X-SAM이나 HyperSeg가 더 높은 항목이 있다.
이건 오히려 논문의 메시지와 잘 맞는다.
X2SAM의 목적은 어느 한 이미지 벤치마크만 밀어 올리는 specialist가 아니라, 이미지와 비디오를 모두 받는 generalist segmentation MLLM이기 때문이다.
| 비교 축 | X2SAM에서 확인되는 수치 | 해석 |
|---|---|---|
| Task coverage | Image seg 7 / Video seg 7 | 논문 표 기준 가장 넓은 통합 범위 |
| Video VGD (YT-VIS19) | 73.8/93.5, 74.4/93.9 | visual prompt 기반 비디오 분할이 핵심 강점 |
| Video VGD (VIPSeg) | 55.5/75.4, 57.8/78.3 | 새로운 V-VGD 축에서도 강한 편 |
| Video reasoning overall | 69.3 / 70.3 / 69.9 | VISA, HyperSeg, LISA 대비 우위 |
| Video OV segmentation | 60.3/78.0 | 이미지 generalist를 넘어 비디오 OV까지 커버 |
| Image/Video chat | Table 20, 21 모두 보고 | segmentation 전용이 아니라 chat 능력도 유지 |
공개 자산 상태도 체크할 만하다.
GitHub API 기준 저장소 wanghao9610/X2SAM은 2026-03-20 생성, stars 22, forks 0, default branch main이며 2026-05-05에 최근 push가 있었다. releases/latest는 404이고 tags는 비어 있어 패키지 릴리스 관리 신호는 아직 약하다.
반면 README는 quickstart와 학습/평가/데모 경로를 꽤 충실하게 적어 두고, Hugging Face에는 체크포인트가 실제 업로드돼 있다.
다만 한 가지 흥미로운 지점은 GitHub repo 메타의 license는 null인데 Hugging Face 카드에는 MIT가 표기돼 있다는 점이다.
즉 법적 사용 조건을 그대로 제품에 반영하려면 LICENSE 파일 유무와 실제 라이선스 텍스트를 별도로 다시 확인하는 편이 안전하다.
실무 관점에서의 해석
내가 보기엔 X2SAM의 중요성은 segmentation 모델 하나가 더 늘었다는 데 있지 않다.
오히려 SAM/SAM2 계열, 이미지 segmentation MLLM, 비디오 segmentation MLLM이 각각 따로 진화해 오면서 생긴 인터페이스 파편화를 줄이려는 시도라는 점이 중요하다.
실제 제품에서는 이미지면 A 모델, 비디오면 B 모델, 텍스트 지시면 C 파이프라인, point/box prompt면 D 파이프라인처럼 갈라질수록 운영 복잡도가 빠르게 커진다.
X2SAM은 그 비용을 줄이는 방향으로 읽어야 한다.
이 모델이 특히 잘 맞는 곳은 대화형 비디오 segmentation이나 human-in-the-loop annotation/inspection 도구다.
사용자가 텍스트로 “오른쪽 사람의 헬멧”을 지정하거나, 첫 프레임에서 박스를 한번 주고 이후 전체 클립에서 객체 track을 마스크로 유지하고 싶을 때, X2SAM 같은 통합 모델이 갖는 이점이 크다.
영상 편집, 데이터 라벨링, 안전 감시, 로보틱스 perception, 산업 검사처럼 “객체를 찾는 것”과 “시간에 따라 일관되게 추적하는 것”이 동시에 필요한 곳에서 바로 상상 가능한 표면이다.
다만 배포 관점에서는 몇 가지를 냉정하게 봐야 한다.
우선 quickstart 설명상 학습은 4노드 32x H800(80GB) 분산 학습 설정까지 등장할 정도로 무겁다.
즉 모델 개념은 통합적이지만, 재학습 비용은 결코 가볍지 않다.
둘째, 릴리스 태그나 정식 배포 버전이 아직 없고 라이선스 메타도 GitHub/Hugging Face 사이에서 완전히 정리된 느낌은 아니다.
셋째, image specialist와의 절대 성능 비교에서는 일부 항목을 양보하고 있기 때문에, 제품 요구가 image-only high-end segmentation이라면 X-SAM이나 specialist 조합이 여전히 더 나을 수 있다.
그럼에도 방향성은 분명하다. segmentation도 이제 “어떤 mask 품질이 더 높은가”만이 아니라, 얼마나 넓은 instruction surface를 한 모델이 흡수할 수 있는가의 경쟁으로 이동하고 있다.
X2SAM은 그 흐름에서 꽤 설득력 있는 한 지점을 보여준다.
이미지에서만 잘 되던 any-segmentation을 비디오, 대화형 프롬프트, visual grounding까지 밀어붙인다면 어떤 형태가 되는지에 대한 현재 시점의 가장 직접적인 답안 중 하나다.