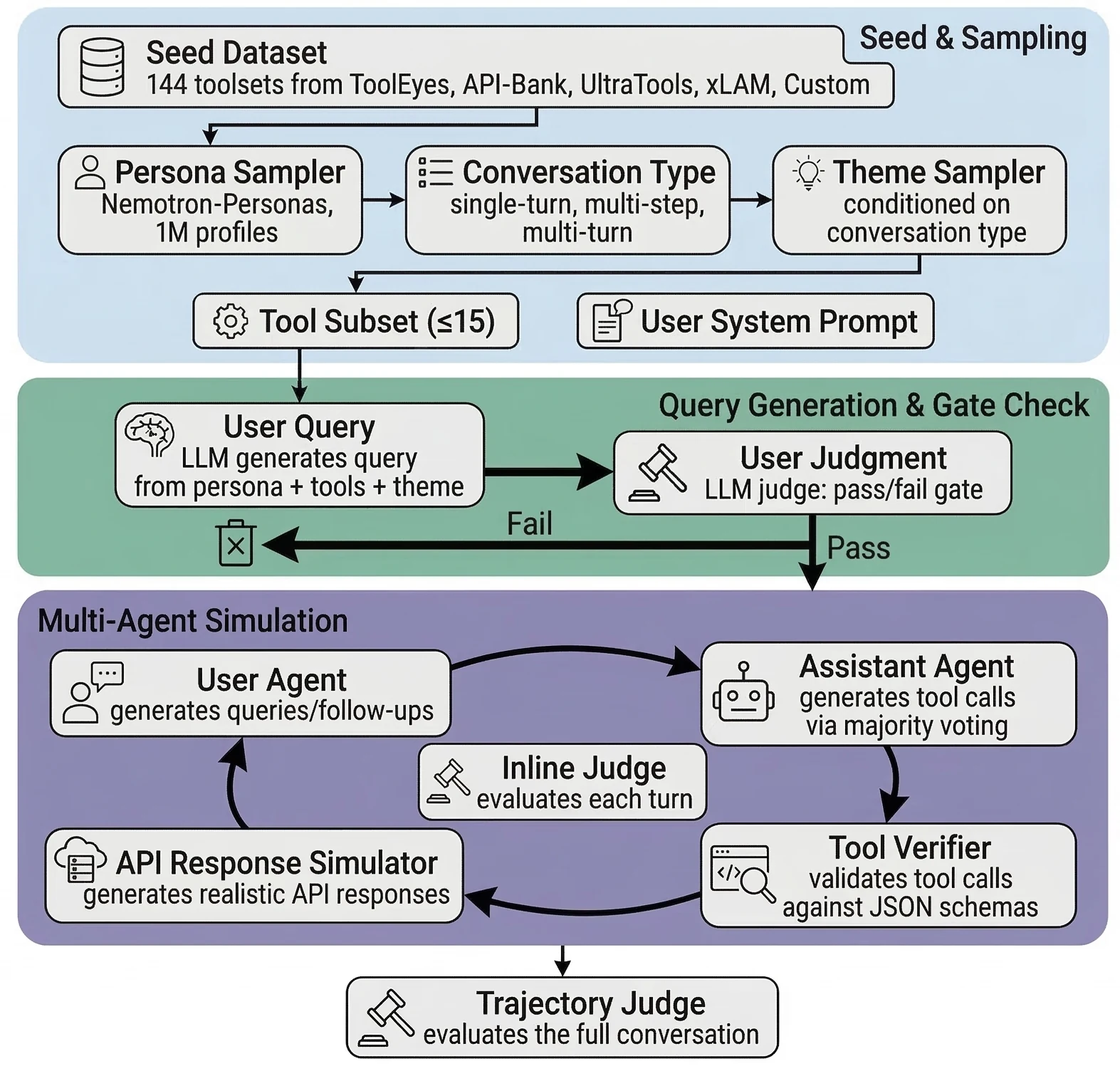
오픈 모델 경쟁에서 이제 중요한 질문은 “얼마나 큰 모델인가”에서 조금씩 벗어나고 있다.
실제 제품 환경에서는 동일한 품질을 더 낮은 활성 계산량과 더 높은 처리량으로 제공할 수 있는가, 그리고 그 모델을 바로 서빙 가능한 정밀도와 런타임까지 함께 내놓을 수 있는가가 훨씬 중요해진다.
특히 코딩 에이전트, 긴 컨텍스트 RAG, 터미널/도구 사용, 대량 업무 자동화처럼 입력도 길고 출력도 긴 워크로드에서는 모델 아키텍처와 추론 시스템을 따로 볼 수 없다.
NVIDIA가 공개한 Nemotron 3 Super 기술 보고서는 이 흐름을 아주 노골적으로 보여 준다.
논문 기준으로 Nemotron 3 Super는 120B total / 12B active 규모의 hybrid Mamba-Attention Mixture-of-Experts 모델이다.
하지만 핵심은 단순히 120B라는 숫자보다, LatentMoE, NVFP4 pretraining, shared-weight MTP, 1M context, agentic post-training, FP8/NVFP4 quantized checkpoint, TensorRT-LLM/vLLM/NIM 배포 경로를 한 묶음으로 설계했다는 데 있다.
내가 보기에 이 릴리스의 진짜 메시지는 “NVIDIA도 큰 오픈 모델을 냈다”가 아니다.
더 정확히는 Blackwell 세대에서 학습·후처리·양자화·서빙까지 이어지는 에이전트용 LLM 제품 스택을 어떻게 구성할 것인가에 대한 레퍼런스 구현에 가깝다.
무엇을 해결하려는가
Nemotron 3 Super가 겨냥하는 문제는 세 가지로 요약된다.
첫째, 큰 모델의 품질과 작은 활성 계산량 사이의 긴장이다.
일반적인 dense 100B급 모델은 품질은 좋지만 서빙 비용과 메모리 대역폭 부담이 크다.
MoE는 이 문제를 일부 풀지만, expert weight loading과 all-to-all 통신이 다시 병목이 된다.
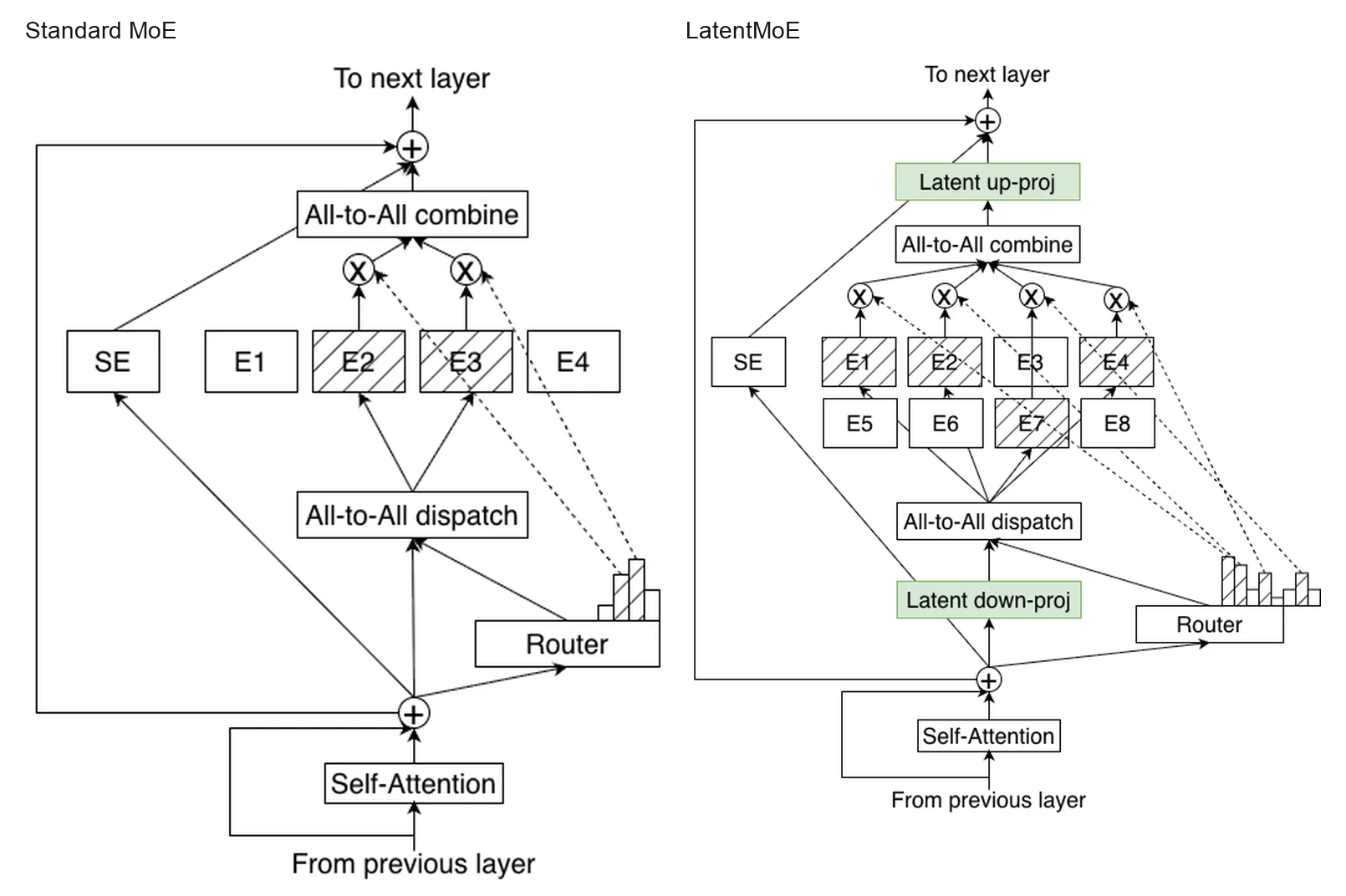
NVIDIA는 여기서 standard MoE 대신 LatentMoE를 도입한다.
토큰을 hidden dimension 그대로 expert에 보내지 않고 더 작은 latent dimension으로 projection한 뒤 routing/expert computation을 수행해, 같은 추론 비용 안에서 더 많은 expert와 더 큰 top-k를 사용할 수 있게 하려는 설계다.
둘째, agentic workload의 긴 입력·긴 출력·도구 루프다.
단순 채팅보다 SWE-Bench, Terminal-Bench, tool use, search, SQL, long-context QA 같은 작업은 입력 컨텍스트가 길고, 여러 단계의 reasoning과 tool call이 섞인다.
논문은 Super 모델을 25T token pretraining 이후 SFT와 RL로 후처리하면서, 에이전트 CLI, 소프트웨어 엔지니어링, CUDA, 검색, 터미널 사용, SQL, long context, tool calling 데이터를 대규모로 확장했다고 설명한다.
셋째, 논문 점수와 실제 throughput 사이의 간극이다.
Nemotron 3 Super는 BF16 체크포인트만 내놓지 않는다.
Hopper용 FP8, Blackwell용 NVFP4 checkpoint를 함께 제공하고, MTP를 통해 native speculative decoding을 지원한다.
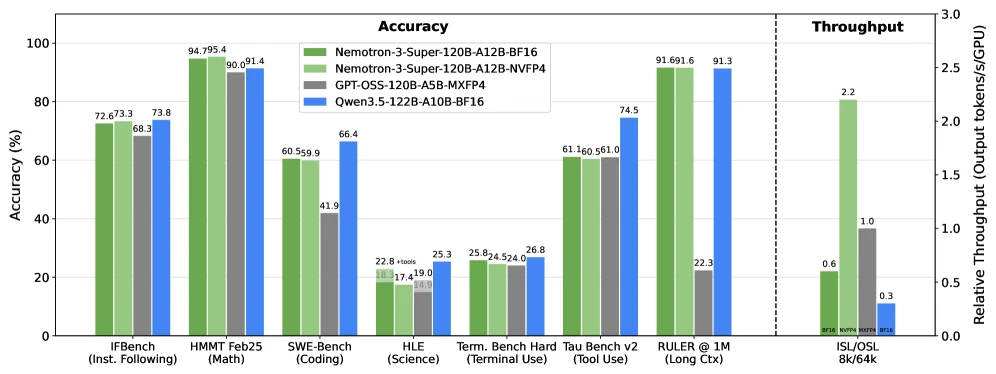
논문 초록은 이 조합으로 GPT-OSS-120B 대비 최대 2.2배, Qwen3.5-122B 대비 최대 7.5배 높은 inference throughput을 보고한다.
즉 이 모델은 leaderboard용 checkpoint라기보다, 처음부터 추론 제품화를 염두에 둔 릴리스다.
핵심 아이디어 / 구조 / 동작 방식
Nemotron 3 Super의 구조를 한 문장으로 줄이면 Hybrid Mamba-Transformer + LatentMoE + MTP + 저정밀 학습/서빙이다.
공개된 paper, Hugging Face README, NVIDIA Nemotron developer repo의 training recipe를 종합하면 주요 사양은 다음과 같다.
| 구성 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| 규모 | 120.6B total, 약 12.7B active per forward pass | 100B급 capacity를 유지하되 실제 활성 계산량은 훨씬 작게 제한 |
| 아키텍처 | 88 layers, Mamba-2와 MoE를 주기적으로 interleave, 일부 attention layer를 global anchor로 삽입 | 긴 시퀀스 효율과 전역 token interaction을 동시에 노림 |
| MoE | 512 routed experts, top-k 22, latent size 1024, shared expert 1개 | standard MoE보다 expert 수와 active expert 수를 키우면서 통신/메모리 비용을 줄이려는 설계 |
| MTP | shared-weight 2-layer Multi-Token Prediction | 품질 개선과 native speculative decoding을 동시에 겨냥 |
| 컨텍스트 | base config는 최대 1,048,576 tokens, post-trained/quantized config는 262,144 max position으로 배포 | 1M long-context capability를 논문에서 평가하되 실제 배포 config는 checkpoint별 차이가 있음 |
| 정밀도 | NVFP4 pretraining, BF16/FP8/NVFP4 checkpoints | 학습과 추론 모두를 저정밀·고처리량 스택에 맞춤 |

1) LatentMoE: expert를 줄이는 게 아니라 expert 통신 비용을 줄인다
Standard MoE는 token hidden state를 그대로 expert로 보내고, expert 결과를 다시 모은다.
이때 병목은 FLOPs만이 아니다.
실제로는 routed parameter load, all-to-all traffic, expert communication이 큰 비용이 된다.
Nemotron 3 Super의 LatentMoE는 입력 token을 먼저 더 작은 latent dimension으로 down-projection한 뒤, 그 latent representation에서 routing과 expert computation을 수행한다.
논문 설명에 따르면 이렇게 얻은 절감분은 단순히 비용을 줄이는 데만 쓰이지 않는다. hidden dimension d 대비 latent dimension ℓ만큼 줄어든 routed parameter load와 all-to-all traffic을 바탕으로, expert 개수와 active top-k를 늘려 대략 같은 inference cost에서 accuracy per parameter와 accuracy per FLOP를 높이는 방향으로 재투자한다.
Super 모델의 설정은 512 routed experts, top-k 22, latent size 1024로, 전형적인 작은 top-k MoE와 다른 방향을 택한다.
2) Mamba-Attention hybrid: 긴 문맥은 Mamba, 전역 연결은 attention anchor
Super 모델은 pure Transformer가 아니다.
88-layer stack에서 Mamba-2와 MoE layer를 주기적으로 배치하고, 일부 self-attention layer를 global anchor처럼 넣는다.
의도는 명확하다.
Mamba 계열의 linear-time sequence modeling으로 긴 문맥 처리 비용을 낮추면서도, attention anchor를 통해 전체 token 간 상호작용을 완전히 포기하지 않는 것이다.
이 구조는 agentic workload와 잘 맞는다.
코드베이스, 문서 묶음, 로그, 티켓, 터미널 history처럼 긴 입력을 다루려면 긴 시퀀스 효율이 중요하다.
동시에 tool call이나 multi-hop reasoning에서는 멀리 떨어진 정보 간 결합이 필요하므로 전역 attention을 일부 남겨야 한다.
Nemotron 3 Super는 이 절충을 모델 구조의 중심에 둔다.
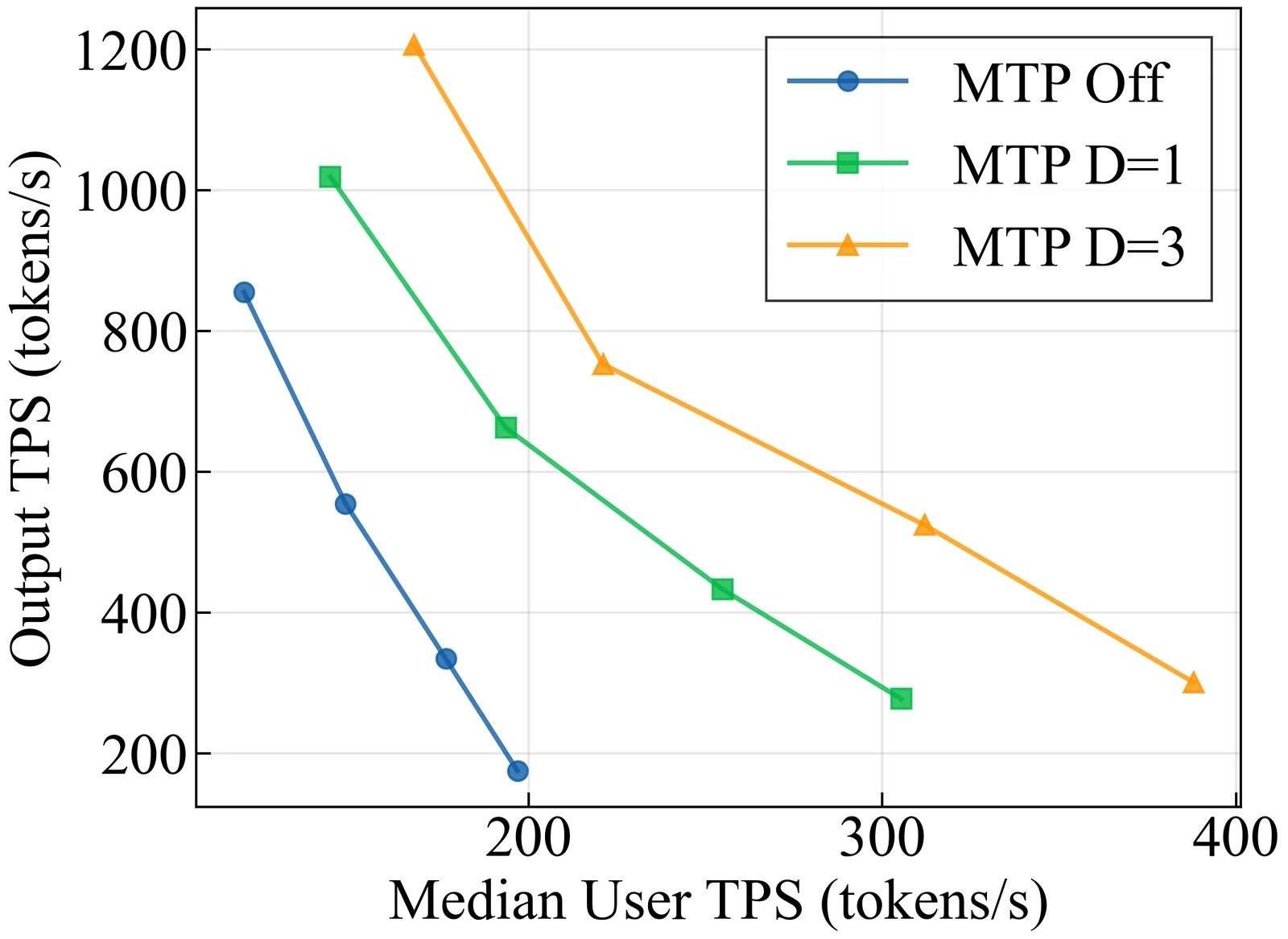
3) MTP: speculative decoding을 외부 draft model이 아니라 내부 능력으로 만든다
Multi-Token Prediction은 단순한 부가 loss가 아니다.
Nemotron 3 Super에서는 shared-weight MTP head가 여러 offset의 future token을 예측하도록 학습되고, inference에서는 이 head가 내부 draft model처럼 동작한다.
즉 별도의 small draft model을 붙이지 않고도 native speculative decoding을 수행할 수 있다.
논문은 SPEED-Bench 기준으로 draft token index가 깊어질수록 acceptance rate가 내려가지만, Nemotron 3 Super가 DeepSeek-R1이나 Qwen3-Next보다 더 높은 acceptance를 유지한다고 보고한다.
또 NVFP4 checkpoint를 TRT-LLM, TP=1, B300 GPU에서 측정했을 때 MTP draft length를 늘리면 total throughput과 user throughput 모두 개선되는 그래프를 제시한다.
4) NVFP4 pretraining과 FP8/NVFP4 배포 checkpoint
가장 NVIDIA다운 부분은 정밀도 설계다.
논문 초록은 Super가 Nemotron 3 family에서 처음으로 NVFP4로 pretraining된 모델이라고 설명한다.
단, 모든 것을 무작정 FP4로 밀어붙인 것은 아니다. pretraining에서는 대부분의 linear layer를 NVFP4로 두되, 마지막 15% network, latent projections, MTP layers, QKV/attention projections, embeddings 등은 BF16으로 유지하고, Mamba output projection은 MXFP8을 사용한다.
추론 배포도 계층화되어 있다.
| 체크포인트 | 목적 | 공개 자료에서 확인되는 포인트 |
|---|---|---|
| BF16 post-trained | 기준 품질 및 일반 배포 | Hugging Face README 기준 최소 8× H100-80GB |
| FP8 | Hopper 계열 고효율 배포 | MoE/Mamba GEMM을 FP8로 양자화, KV cache FP8, Mamba SSM cache FP16 |
| NVFP4 | Blackwell 계열 단일 GPU/고처리량 배포 | README 기준 1× B200 또는 1× DGX Spark, sparse expert GEMM 중심으로 NVFP4 사용 |
흥미로운 점은 NVFP4 PTQ가 단순 post-training quantization이 아니라는 것이다.
논문은 weight per-block scale은 MSE를 최소화하는 방식으로 offline calibration하고, activation scale은 runtime 비용 때문에 max-based scaling을 사용한다고 설명한다.
여기에 Model-Optimizer AutoQuantize로 민감한 layer를 FP8/BF16으로 선택 승격한다.
최종적으로 논문은 512개 calibration samples, sequence length 4096, single B200 node 8 GPUs에서 2시간 미만으로 mixed-precision PTQ를 완료했고, BF16 대비 median accuracy 99.8%를 유지했다고 보고한다.
공개된 근거에서 확인되는 성능
Post-trained evaluation에서 Nemotron 3 Super는 Qwen3.5-122B-A10B, GPT-OSS-120B와 비교된다.
표 전체를 한 줄로 요약하면, Qwen3.5-122B를 전 영역에서 이기는 모델은 아니지만, GPT-OSS-120B 대비는 상당히 넓은 영역에서 경쟁력 있고, 특히 long-context와 throughput 쪽 메시지가 강하다.
| 축 | Nemotron 3 Super | 비교 관찰 |
|---|---|---|
| MMLU-Pro | 83.73 | Qwen3.5-122B 86.70보다는 낮고 GPT-OSS-120B 81.00보다는 높음 |
| AIME25 no tools | 90.21 | Qwen3.5 90.36, GPT-OSS 92.50과 비슷한 고점권 |
| HMMT Feb25 with tools | 94.73 | Qwen3.5 89.55보다 높게 보고 |
| GPQA no tools | 79.23 | Qwen3.5 86.60, GPT-OSS 80.10보다 낮음 |
| SWE-Bench OpenHands | 60.47 | Qwen3.5 66.40보다는 낮고 GPT-OSS 41.9보다는 높음 |
| Terminal Bench Core 2.0 | 31.00 | Qwen3.5 37.50보다 낮지만 GPT-OSS 18.70보다 높음 |
| IFBench prompt | 72.56 | Qwen3.5 73.77과 비슷하고 GPT-OSS 68.32보다 높음 |
| RULER 1M | 91.64 | Qwen3.5 91.33과 비슷하고 GPT-OSS 22.30보다 크게 높음 |
| WMT24++ en→xx | 86.67 | GPT-OSS 88.89, Qwen3.5 87.84보다 약간 낮음 |
이 수치를 읽을 때는 두 가지를 분리해야 한다.
품질만 보면 Nemotron 3 Super가 Qwen3.5-122B-A10B를 전방위로 압도한다고 말하기는 어렵다.
GPQA, SWE-Bench, Terminal Bench, Arena-Hard-V2, multilingual translation 등에서는 Qwen 또는 GPT-OSS가 더 높은 항목이 있다.
반대로 HMMT with tools, RULER 1M, 일부 long-context 항목에서는 Super가 매우 강하다.
하지만 throughput까지 포함하면 그림이 달라진다.
논문 Figure 1은 8k input / 64k output 조건에서 Nemotron 3 Super가 GPT-OSS-120B 대비 최대 2.2배, Qwen3.5-122B 대비 최대 7.5배 높은 throughput을 보인다고 주장한다.
즉 NVIDIA의 주장은 “모든 벤치마크에서 절대 1등”이 아니라, 비슷한 품질대의 agentic 모델을 훨씬 높은 처리량으로 제공한다에 더 가깝다.
Post-training: agentic 모델을 위한 데이터 공장
Nemotron 3 Super의 post-training 섹션은 꽤 중요하다.
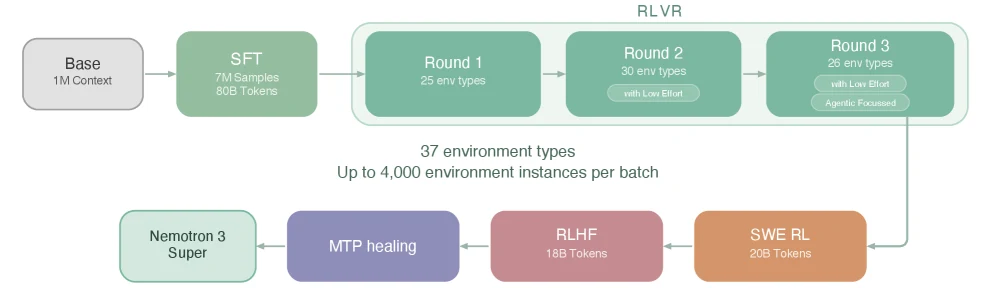
이 모델은 pretraining만으로 끝나는 base model이 아니라, agentic workload에 맞춰 SFT와 RL을 대규모로 다시 설계한다.
논문은 SFT에서 agentic datasets 비중을 키우고, single-stage SFT가 long-input-short-output 성능을 망가뜨리는 문제를 발견해 two-stage loss를 사용했다고 설명한다.
1단계는 output token 전체 평균 loss로 reasoning behavior를 강하게 만들고, 2단계는 conversation 단위 normalization으로 긴 출력이 loss를 지배하지 않게 한다.
데이터 측면에서는 훨씬 더 노골적이다.
Software engineering 데이터는 SWE-Gym, R2E-Gym, SWE-rebench 기반 GitHub issue와 containerized environment를 활용하고, OpenHands trajectory를 teacher model로 distill한다.
Agentic CLI 데이터는 Codex, OpenCode, Qwen Code CLI, Stirrup 같은 CLI 환경에서 interaction trace를 기록해 OpenAI message format으로 정규화한다.
Tool use 데이터는 specialized conversational tool-use 279,116 conversations / 838 domains까지 확장되며, general-purpose tool-calling은 1.5M trajectories 규모로 제시된다.
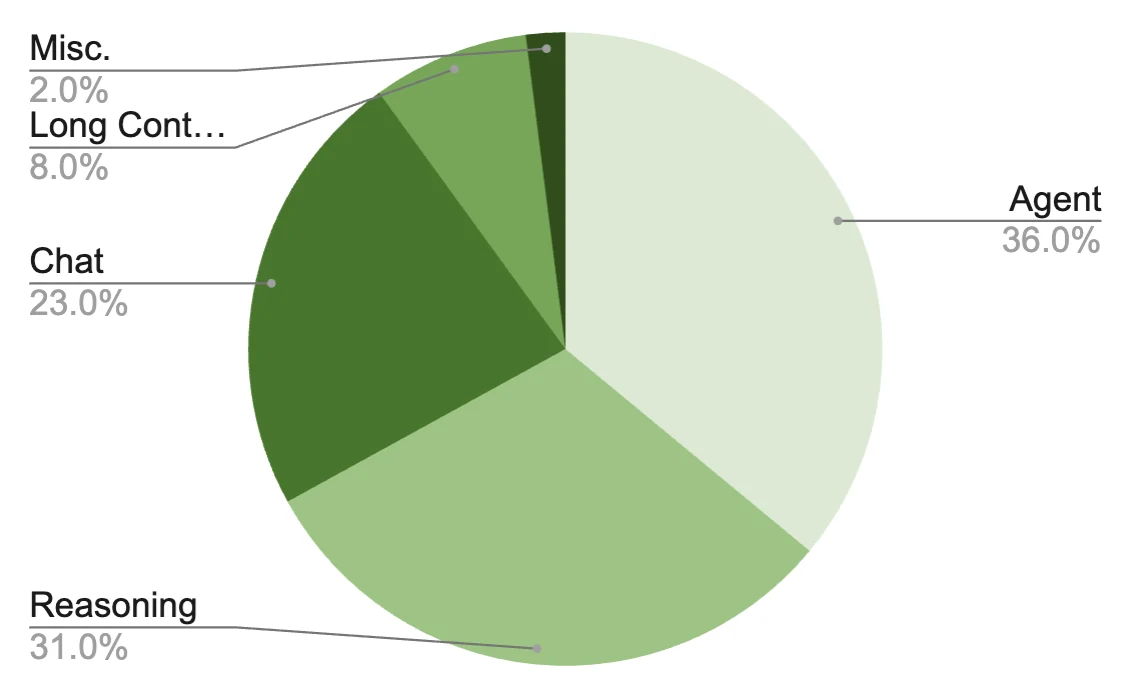
SFT data blend도 이 방향을 잘 보여 준다.
공개 figure 기준으로 Super SFT blend는 Agent 36%, Reasoning 31%, Chat 23%, Long Context 8%, Misc 2%로 구성된다.
즉 이 모델은 일반 chat model이라기보다, 에이전트·추론·장문 워크로드를 우선순위에 둔 모델이다.
RL도 세 단계다.
첫째는 21개 environment와 37개 dataset을 아우르는 RLVR, 둘째는 OpenHands와 Apptainer container를 사용하는 end-to-end SWE-RL, 셋째는 Qwen3-235B initialization 기반 principle-following GenRM을 사용하는 RLHF다.
이 구성은 최근 frontier reasoning 모델들이 단순 SFT보다 환경 기반 feedback loop와 verifiable reward를 더 강하게 쓰는 흐름과 맞닿아 있다.
실무 관점에서의 해석
내가 보기에 Nemotron 3 Super의 가장 큰 의미는 모델 자체보다 모델 릴리스의 단위가 바뀌고 있다는 점이다.
여기서 공개되는 것은 checkpoint 하나가 아니다.
- arXiv 기술 보고서와 HTML/PDF
- Hugging Face의 base, post-trained BF16, FP8, NVFP4 checkpoints
- 공개 pretraining dataset
Nemotron-Pretraining-Specialized-v1.1 - NVIDIA Nemotron developer repository의 Super training recipe
- NeMo Evaluator / NeMo Skills 기반 evaluation configs
- Model-Optimizer 기반 quantization workflow
- NIM, TensorRT-LLM, vLLM, SGLang 등 NVIDIA 생태계 배포 경로
이 묶음은 오픈 모델을 연구 산출물로만 보지 않고, 하드웨어-런타임-데이터-평가-배포를 통합한 제품형 foundation model package로 다루는 방식에 가깝다.
특히 NVFP4와 Blackwell을 전면에 둔 점은 중요하다.
NVIDIA가 가장 잘할 수 있는 부분은 모델 파라미터 숫자 경쟁이 아니라, 모델이 특정 하드웨어에서 실제로 빠르게 돈다는 end-to-end narrative이기 때문이다.
물론 한계도 분명하다.
첫째, 라이선스는 Apache 2.0이 아니라 NVIDIA Nemotron Open Model License다.
논문은 CC BY 4.0으로 공개되어 있지만, model weights 사용 조건은 별도 라이선스를 확인해야 한다.
둘째, BF16 모델은 README 기준 최소 8× H100-80GB가 필요하고, NVFP4의 매력은 B200/DGX Spark 같은 Blackwell 환경에서 가장 크다.
즉 “오픈”이 곧 “아무 장비에서나 쉽게 self-host”를 의미하지는 않는다.
셋째, benchmark 해석도 조심해야 한다.
논문은 평가 설정과 Nemo Evaluator configs를 공개하지만, 일부 benchmark는 아직 open-source tool에 onboard되지 않았거나 내부 scaffolding을 사용했다고 밝힌다.
또한 Qwen3.5-122B-A10B 대비 항상 우세한 것도 아니다.
따라서 실무 도입에서는 paper table을 그대로 믿기보다, 자신의 agent harness, tool schema, context length, batch size, 하드웨어 조건에서 latency와 pass rate를 다시 측정해야 한다.
그럼에도 이 릴리스는 꽤 중요한 신호다.
앞으로의 오픈 모델 경쟁은 단순히 “더 큰 dense 모델”로 흘러가기보다, sparse active compute, hybrid sequence model, native speculative decoding, 저정밀 학습/양자화, agentic post-training, 재현 가능한 평가/배포 recipe를 얼마나 잘 묶느냐의 싸움이 될 가능성이 크다.
Nemotron 3 Super는 그 방향을 NVIDIA식으로 매우 선명하게 제시한 사례다.