긴 문서를 다루는 RAG 시스템은 대개 비슷한 병목에서 막힌다. PDF를 잘게 청킹하고, 임베딩을 만들고, 벡터 DB에서 유사한 조각을 꺼내는 파이프라인은 익숙하지만, 실제로 중요한 질문은 늘 더 까다롭다. 사용자가 찾는 것은 의미상 비슷한 문장이 아니라 문서 전체 맥락 속에서 정말 관련 있는 섹션이며, 그 판단은 종종 다단계 추론과 문서 구조 이해를 필요로 한다.
VectifyAI/PageIndex가 흥미로운 이유는 바로 이 지점을 정면으로 건드리기 때문이다. 이 저장소는 자신을 vectorless, reasoning-based RAG라고 설명한다. 핵심 메시지는 명확하다. 검색을 임베딩 유사도 문제로 고정하지 말고, 문서의 계층 구조를 만든 뒤 LLM이 그 구조를 따라가며 다음에 어디를 봐야 할지 추론하게 하자는 것이다. 즉 PageIndex는 “더 좋은 벡터 검색기”라기보다 문서 검색 자체를 사람처럼 탐색하는 절차로 재정의하려는 시도에 가깝다.
또 하나 봐야 할 점은 이 프로젝트가 단순 연구 아이디어에 머물지 않는다는 것이다. GitHub 저장소에는 오픈소스 Python 구현이 있고, 공식 사이트에는 Chat, Developer, Enterprise 표면이 분리돼 있으며, 개발자용 페이지에서는 MCP와 API를 전면에 내세운다. 다시 말해 PageIndex는 RAG 이론을 설명하는 README만 있는 프로젝트가 아니라, 오픈소스 인덱싱 엔진 + 에이전트용 retrieval 인터페이스 + 호스팅 서비스를 함께 밀고 있는 제품형 리포지터리다.
무엇을 해결하려는가
기존 vector-based RAG의 핵심 가정은 비교적 단순하다. 문서를 잘게 나눈 뒤 각 조각을 임베딩 공간에 놓고, 질의와 가장 비슷한 조각을 찾으면 충분하다는 것이다. 하지만 긴 재무 보고서, 법률 문서, 기술 매뉴얼처럼 구조가 깊고 맥락 의존적인 문서에서는 이 가정이 자주 흔들린다. 사용자의 질문은 특정 문장을 찾는 문제가 아니라, 여러 절의 관계를 따라가며 어디를 읽어야 하는지 결정하는 문제에 더 가깝기 때문이다.
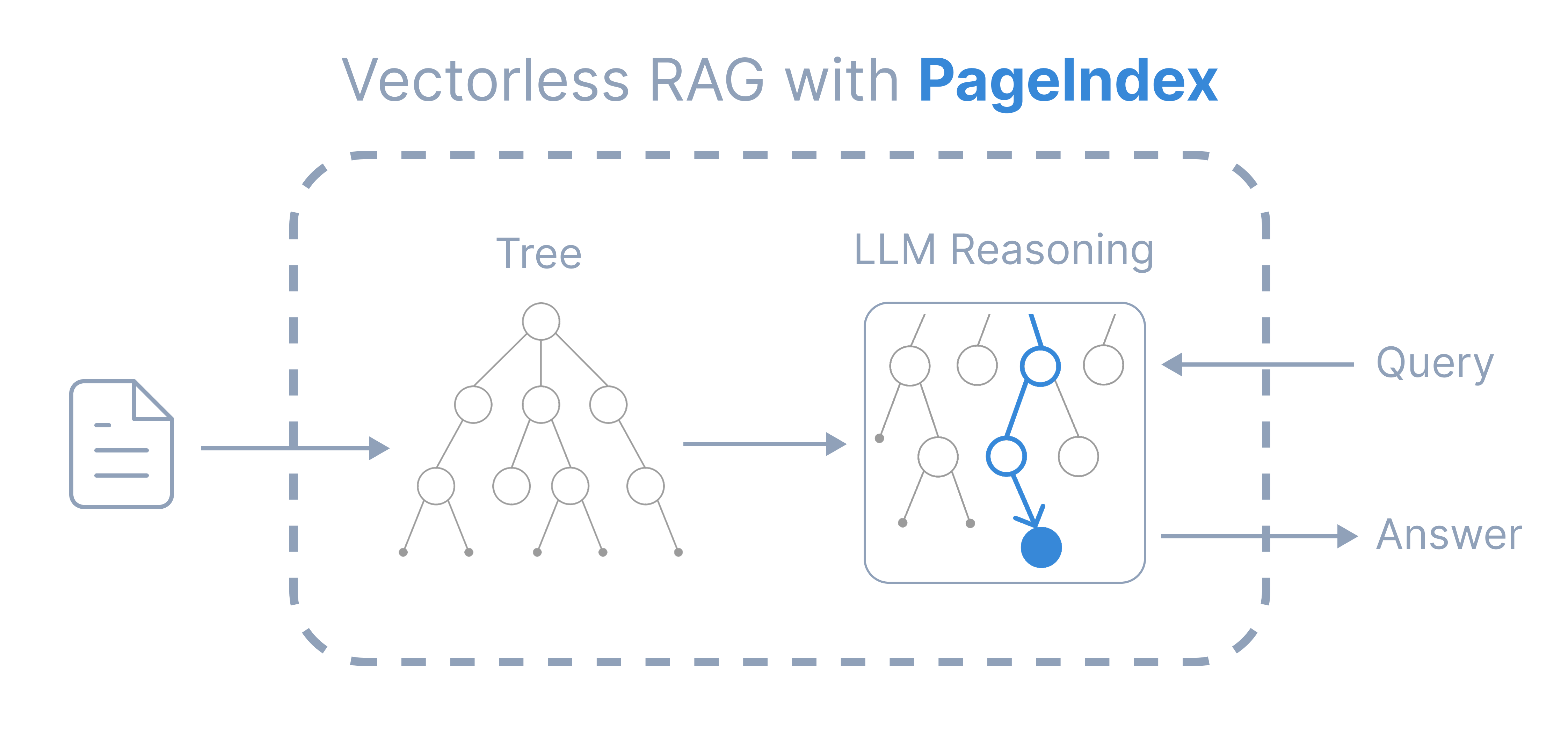
PageIndex는 이 문제를 README와 공식 블로그에서 일관되게 similarity와 relevance의 차이로 설명한다. 비슷해 보이는 텍스트가 꼭 답이 되는 것은 아니며, 관련성은 종종 추론을 통해서만 드러난다는 주장이다. 그래서 이 프로젝트는 chunking과 vector DB를 기본 전제로 삼지 않는다. 대신 문서에서 사람이 목차를 훑듯 따라갈 수 있는 트리형 인덱스를 만들고, 모델이 그 위에서 점진적으로 범위를 좁히게 한다.
이 접근이 겨냥하는 대상도 분명하다. README와 examples에는 annual report, earnings 문서, 규제 문서, PRML 같은 장문 PDF가 등장한다. 즉 PageIndex는 짧은 FAQ보다 길고 전문적이며 섹션 구조가 중요한 문서를 우선 문제로 삼는다. LLM context window가 길어져도 성능 저하와 비용 문제가 사라지지 않는 상황에서, 이 프로젝트는 문서 전체를 한 번에 넣는 대신 문서 구조를 더 잘 다루는 retrieval 계층을 제안하는 셈이다.
핵심 아이디어 / 구조 / 동작 방식
PageIndex의 구조는 크게 세 단계로 이해하면 된다.
1) 문서를 계층적 인덱스로 바꾼다
run_pageindex.py와 pageindex/page_index.py가 보여 주는 첫 단계는 문서를 JSON 기반 트리 구조로 변환하는 것이다. README는 이 결과를 LLM용 Table-of-Contents index로 설명한다. 각 노드는 제목, 범위, 요약, 선택적으로 node id와 텍스트를 담을 수 있고, 자식 노드를 통해 더 세밀한 문서 계층으로 내려간다. 전통적인 fixed-size chunk 리스트와 달리, 여기서는 문서의 자연스러운 섹션 경계를 retrieval의 기본 단위로 삼는다.
2) retrieval을 유사도 검색이 아니라 탐색 루프로 다룬다
공식 블로그 소개 글과 예제 설명을 종합하면, PageIndex의 retrieval은 한 번의 top-k 검색보다 iterative reasoning loop에 가깝다. 모델은 먼저 문서 메타데이터와 구조를 보고, 어떤 상위 섹션이 관련 있을지 추정한 뒤, 필요한 페이지 범위를 더 좁혀 실제 내용을 읽는다. 이 흐름은 get_document(), get_document_structure(), get_page_content() 같은 도구형 API에도 그대로 반영된다. 즉 시스템은 문서 전체 본문을 매번 던져 주지 않고, 에이전트가 좁은 범위의 페이지를 순차적으로 호출하도록 설계돼 있다.
3) 오픈소스 구현과 호스팅 제품을 분리한다
여기서 중요한 운영상 신호가 하나 더 있다. README는 self-hosted 오픈소스 경로를 제공하면서도, 복잡한 PDF의 경우 cloud service가 enhanced OCR, tree building, retrieval을 제공한다고 별도로 강조한다. 오픈소스 저장소의 requirements.txt는 litellm, pymupdf, PyPDF2, python-dotenv, pyyaml 정도로 비교적 얇고, run_pageindex.py는 로컬 PDF 또는 Markdown에서 구조 JSON을 생성하는 데 집중한다. 반면 공식 사이트는 Chat, MCP/API, Enterprise 배포를 별도 표면으로 내세운다. 즉 이 저장소는 제품 전체를 완전히 재현하는 풀스택이라기보다, 핵심 인덱싱/탐색 개념을 셀프호스트 가능한 형태로 공개한 OSS 코어에 가깝다.
공개 자료를 바탕으로 핵심 표면을 정리하면 다음과 같다.
| 레이어 | 공개 자료에서 확인되는 구성 | 역할 |
|---|---|---|
| 인덱싱 계층 | run_pageindex.py, page_index.py, PDF/Markdown 입력 지원 |
문서를 JSON 트리 구조로 변환 |
| retrieval 계층 | get_document, get_document_structure, get_page_content |
에이전트가 구조를 보고 관련 범위를 점진적으로 탐색 |
| 에이전트 계층 | examples/agentic_vectorless_rag_demo.py, OpenAI Agents SDK 예제 |
문서 QA 에이전트가 도구 호출로 retrieval 수행 |
| 실습 계층 | pageindex_RAG_simple.ipynb, vision_RAG_pageindex.ipynb, agentic_retrieval.ipynb |
기본형, vision 기반, agentic retrieval 패턴 제공 |
| 제품 계층 | 공식 사이트의 Chat / Developer(MCP & API) / Enterprise | 호스팅 서비스와 개발자 통합 표면 제공 |
이 구조가 재미있는 이유는 RAG를 벡터 인프라 중심이 아니라 문서 구조 + 도구 호출 + 추론 정책 중심으로 다시 짜고 있기 때문이다. 특히 agentic_vectorless_rag_demo.py는 PageIndex를 단순 라이브러리 호출이 아니라, 문서 구조 확인 → 좁은 페이지 범위 조회 → 답변 생성이라는 agent loop로 보여 준다. 최근 에이전트 시스템이 retrieval을 점점 도구 사용 문제로 흡수하는 흐름과도 잘 맞는다.
공개된 근거에서 확인되는 점
GitHub API 기준으로 이 저장소는 작성 시점에 약 30.2k stars, 2.6k forks를 기록하고 있다. 생성일은 2025년 4월 1일, 기본 브랜치는 main, 라이선스는 MIT다. topics에는 agentic-ai, rag, reasoning, retrieval, vector-database 등이 붙어 있어, 프로젝트가 자신을 에이전트 친화적 retrieval 인프라로 포지셔닝하고 있음을 알 수 있다.
흥미로운 점은 릴리스 신호다. GitHub의 /releases/latest는 404를 반환했고 /tags도 비어 있었다. 즉 적어도 공개 저장소 수준에서는 semantic release나 버전 태깅보다 main 브랜치와 README 중심의 빠른 업데이트가 우선인 상태로 보인다. 실제 최근 커밋 5개도 대부분 README와 문서 메시지 조정에 가까웠다. 실험이 완전히 멈춘 프로젝트는 아니지만, 패키지 버전 규율이 강한 라이브러리형 OSS와는 성격이 다르다.
구현 범위도 생각보다 선명하다. 루트에는 pageindex/, examples/, cookbook/, run_pageindex.py, requirements.txt가 있고, pageindex/client.py는 workspace에 문서 메타와 구조를 저장한 뒤 retrieval 도구로 재활용하는 흐름을 제공한다. retrieve.py를 보면 페이지 범위를 '5-7', '3,8' 같은 형식으로 받아 필요한 부분만 읽어 오는 식이라, retrieval granularity를 좁게 유지하려는 철학이 드러난다. examples에는 annual report, earnings, 규제 문서, Attention Residuals 논문 등 실제 장문 문서 샘플이 포함돼 있다.
또 다른 중요한 근거는 제품 분화다. 공식 사이트 메인 페이지는 “For Developers” 섹션에서 vectorless, reasoning-based retrieval — available as MCP and API를 직접 강조한다. 블로그 글의 schema metadata에는 feature list로 Vectorless RAG retrieval, Reasoning-based document understanding, Exact page reference citations, 98.7% accuracy on FinanceBench, MCP Protocol integration, REST API access가 들어 있다. README도 self-hosted OSS와 cloud service를 분리해 설명하고 있어, 이 프로젝트가 단순 연구 repo를 넘어서 호스팅 제품과 개발자 통합 채널을 함께 설계하고 있음을 보여 준다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| GitHub API | 약 30.2k stars, 2.6k forks, MIT, main 브랜치 |
빠르게 확산된 오픈소스 retrieval 프로젝트 |
| Releases / tags | latest release 404, tags 비어 있음 | 버전 패키징보다 main/README 중심의 빠른 전개 성격 |
requirements.txt |
LiteLLM + PDF 파싱 중심의 얇은 의존성 | OSS 코어는 비교적 단순한 인덱싱/탐색 엔진에 집중 |
| examples / cookbook | agentic demo, simple RAG notebook, vision RAG notebook | 단순 개념 소개보다 여러 retrieval 패턴을 직접 보여 줌 |
| 공식 사이트 | Chat, Developer(MCP & API), Enterprise 분리 | 오픈소스 코어 위에 제품/플랫폼 표면을 얹는 구조 |
실무 관점에서의 해석
내가 보기에 PageIndex의 가장 중요한 가치는 “벡터 DB 없이도 된다”는 자극적인 문구 자체보다, retrieval을 정적 검색에서 동적 탐색으로 옮긴다는 관점 전환에 있다. 많은 RAG 시스템은 chunking 방식, embedding 모델, reranker 튜닝에 많은 에너지를 쏟지만, 사실 긴 문서 QA에서 더 중요한 것은 질문을 읽고 어느 절을 먼저 봐야 하는지 판단하는 절차다. PageIndex는 그 판단 절차를 문서 구조 위의 추론으로 끌어올린다.
이 접근은 특히 에이전트와 잘 맞는다. 도구 사용이 가능한 모델에게는 벡터 검색 한 번으로 top-k를 던져 주는 방식보다, 목차를 보고 범위를 좁히고 필요한 페이지를 추가로 읽는 방식이 오히려 자연스러울 수 있다. agentic_vectorless_rag_demo.py가 문서 QA를 바로 그런 방식으로 설계한 것도 같은 맥락이다. 검색기가 하나의 블랙박스 함수가 아니라, 에이전트가 중간 판단을 남기며 따라갈 수 있는 과정이 되기 때문이다.
물론 한계도 분명하다. 첫째, README와 공식 블로그가 보여 주는 성능 서사는 설득력이 있지만, 공개 저장소만으로는 hosted service가 제공하는 향상된 OCR·tree building·retrieval 품질을 그대로 재현하기 어렵다. 둘째, 릴리스 태그가 비어 있다는 점은 도입 팀 입장에서 버전 고정과 변경 관리 전략을 따로 세워야 함을 뜻한다. 셋째, vectorless라는 메시지가 모든 문서 검색 문제에서 즉시 우월하다는 뜻은 아니다. 문서 구조가 흐릿하거나 질의가 광범위한 경우에는 여전히 다른 retrieval 방식과의 조합이 필요할 수 있다.
그럼에도 방향성은 꽤 설득력 있다. 최근 에이전트 시스템은 단순히 더 긴 컨텍스트를 넣는 것보다, 필요한 근거를 더 잘 찾아오고 그 과정을 설명 가능하게 만드는 것으로 이동하고 있다. 그런 흐름에서 PageIndex는 또 하나의 RAG 라이브러리라기보다, 문서 retrieval을 에이전트 네이티브하게 다시 설계하려는 레퍼런스 구현으로 읽는 편이 맞다. 특히 긴 전문 문서, 페이지 단위 근거 제시, MCP/API 기반 통합이 중요한 팀이라면 한 번쯤 진지하게 살펴볼 만한 프로젝트다.