Kubernetes를 전사에 도입한다는 말은 종종 “클러스터를 얼마나 쉽게 만들 수 있는가”로 축약된다.
하지만 엔터프라이즈 환경에서는 그 다음 질문이 더 어렵다.
누가 어떤 리소스를 쓰고 있는가, 장애와 변경 이벤트는 어디로 흘러가는가, CMDB와 보안·재무·운영 프로세스는 새로운 컨테이너 레이어를 어떻게 이해해야 하는가.
kakao tech 채널의 if(kakao)2020 세션 **엔터프라이즈 환경에서의 ITSM을 고려한 Kubernetes 도입**은 이 문제를 꽤 현실적으로 보여준다.
발표는 Kubernetes 자체의 기능 소개보다, 카카오가 DKOS와 D2Hub를 통해 컨테이너 기반 서비스를 확장하면서 전사 ITSM 관점에서 무엇을 연결해야 했는지를 설명한다.
흥미로운 점은 발표가 2020년의 사례임에도 지금의 platform engineering 논의와 거의 같은 질문을 던진다는 것이다.
내부 개발자가 셀프서비스로 클러스터를 만들 수 있게 되었을 때, 플랫폼 팀의 일은 끝나는 것이 아니라 그 클러스터에서 발생하는 자원·토폴로지·배포·이벤트 데이터를 조직 전체가 쓸 수 있는 운영 언어로 바꾸는 일로 이동한다.
무엇을 다루는 영상인가
이 영상은 kakao tech 채널의 약 14분짜리 발표다.
YouTube metadata 기준 업로드일은 2026-06-10으로 잡히지만, 제목과 설명은 세션을 if(kakao)2020 발표로 명시한다.
발표자는 카카오 Cloud Platform Developer 홍석용 Dennis이며, 설명란은 카카오에서의 Kubernetes 활용 사례와 엔터프라이즈 환경에서 Kubernetes를 도입할 때 ITSM 관점에서 고려해야 하는 사항을 공유한다고 정리한다.
공식 chapter는 제공되지 않았다.
이 글은 YouTube metadata, 설명란, 자동 생성 한국어 자막, 영상에서 추출한 주요 프레임을 기준으로 정리했다.
자동 자막에는 Kubernetes, D2Hub, ITSM, Node Problem Detector 같은 기술명이 일부 오인식되어 있어, 설명란과 문맥으로 명칭을 보정했다.
설명란에는 별도 companion 문서나 발표 자료 링크가 없어서, 구현 세부는 영상에서 확인되는 범위로만 다룬다.
핵심 아이디어: Kubernetes를 ITSM의 데이터 소스로 만든다
발표 초반부의 출발점은 카카오 내부 플랫폼이다.
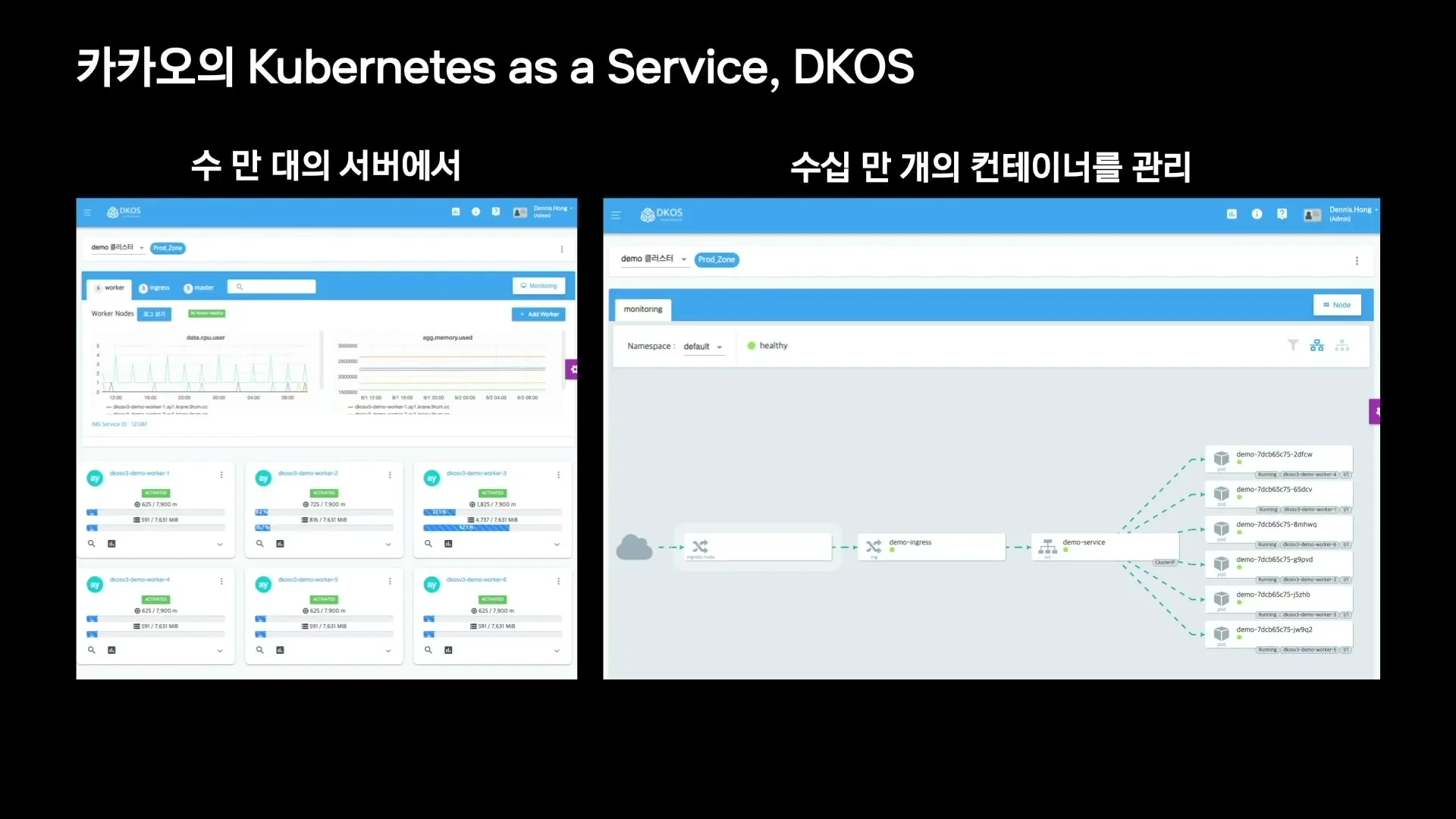
발표에 따르면 카카오는 클릭 몇 번으로 인프라와 Kubernetes 클러스터를 생성할 수 있는 DKOS를 갖고 있으며, 크루들이 학습·테스트·실서비스 용도로 클러스터를 만들 수 있다.
발표 당시 DKOS는 수만 대 서버와 수십만 개 컨테이너를 관리하는 규모로 설명된다.
또 하나의 축은 D2Hub다.
D2Hub는 코드 변경 이벤트를 감지해 컨테이너 이미지를 자동 빌드하고, 빌드된 이미지를 배포 정책에 따라 여러 클러스터로 자동 배포하는 플랫폼으로 소개된다.
즉 카카오의 Kubernetes 도입은 “클러스터 생성”과 “이미지 빌드·배포”가 함께 묶인 내부 플랫폼 흐름 위에서 진행된다.
여기서 발표자가 던지는 질문은 단순하다.
이런 환경에서 Kubernetes가 전사에 자연스럽게 녹아들려면 어떻게 해야 하는가.
답은 “기존 ITSM 활동을 Kubernetes 기반으로 다시 연결해야 한다”에 가깝다.
ITSM은 IT 서비스를 계획, 제공, 운영, 제어하는 활동 전체를 뜻한다.
전사 서비스가 Kubernetes로 이동하면 기존 서버·네트워크·보안·기획·재무·운영 부서가 다뤄야 할 대상에 컨테이너라는 새 레이어가 추가된다.
따라서 플랫폼 팀은 Kubernetes 리소스를 클러스터 내부의 객체로만 두지 않고, 전사 운영 시스템이 이해할 수 있는 정보로 공유해야 한다.
관리 대상은 서버에서 토폴로지와 이벤트로 확장된다
발표에서 가장 중요한 전환은 CMDB 관점이다.
기존 ITSM에서는 인프라와 애플리케이션 CMDB가 각각 관리되는 구조가 많았다.
Kubernetes 기반 서비스에서는 애플리케이션 정의, 필요한 리소스, 서버, 스토리지, 로드밸런서, 도메인, 배포 상태가 오케스트레이터 안에서 연결된다.
발표자는 이 토폴로지 정보를 전사에서 활용할 수 있게 해야 한다고 말한다.
예를 들어 어떤 애플리케이션이 어떤 로드밸런스와 연결되어 있는지, 어떤 도메인으로 서비스되는지, 배포로 인해 형상이 바뀌었는지를 실시간으로 공유할 수 있다.
Kubernetes 이벤트를 중앙 데이터 허브로 모으면 애플리케이션 설정 변경, 인프라 구성 변경, 가용성, 용량, 보안 관리에 사용할 수 있다.
이 관점에서 Kubernetes는 단순한 배포 엔진이 아니다.
Kubernetes는 조직의 운영 데이터 모델을 새로 만드는 소스가 된다.
정리하면 발표가 요구하는 공유 데이터는 대략 다섯 가지다.
| 공유해야 할 정보 | ITSM 관점에서의 의미 |
|---|---|
| 컨테이너 자원 정보 | 물리 서버 외에 컨테이너 레이어의 사용량·상태·소유권을 관리 |
| 애플리케이션-리소스 토폴로지 | 앱, 도메인, 로드밸런서, 노드, 스토리지 연결 관계를 실시간 CMDB로 사용 |
| 오케스트레이터 이벤트 | 장애, 변경, 배포, 용량 이벤트를 알림·자동화·보안 관리로 연결 |
| CI/CD와 앱 설치 정보 | 어떤 클러스터에 어떤 앱·차트·버전이 설치됐는지 추적 |
| 외부 물리 자원 통합 | 스토리지·로드밸런서 같은 데이터센터 자원을 Custom Resource와 Controller로 연결 |
특히 마지막 항목이 중요하다.
발표자는 Kubernetes가 모든 것을 제공하지 않는다고 강조한다.
실제 서비스에는 스토리지와 로드밸런서 같은 기존 데이터센터 자원이 있으며, 이를 Kubernetes가 인식하고 관리할 수 있도록 Custom Resource와 Custom Controller로 통합해야 한다.
엔터프라이즈 Kubernetes 도입의 난점은 바로 이 경계면에 있다.
SLA는 인프라 생존율이 아니라 서비스 지속성으로 잡아야 한다
발표 중반부는 ITIL 관점에서 서비스 설계와 운영을 다룬다.
여기서 핵심은 SLA를 어디에 둘 것인가다.
비용과 가용성은 트레이드오프 관계이고, Kubernetes의 분산 환경은 Pod나 Node가 언제든 내려갈 수 있다는 가정을 전제로 설계된다.
따라서 발표자는 인프라 관점의 SLA보다 서비스 관점의 SLA를 세우는 편이 낫다고 말한다.
즉 목표는 서버가 절대 죽지 않는 것이 아니다.
인프라나 애플리케이션 문제가 생겨도 서비스가 얼마나 빠르고 안정적으로 제공되는지를 기준으로 삼아야 한다.

그 다음에는 control plane, worker node, pod 가용성을 나눠 본다. control plane은 kubectl get componentstatus 응답을 통해 kube-apiserver, scheduler, controller-manager, etcd 상태를 확인하는 흐름으로 설명된다. worker node 쪽에서는 기본 Node condition만으로 충분하지 않은 경우가 있으므로, Node Problem Detector를 통해 더 상세한 node condition과 event를 확장할 수 있다고 말한다.
Node Problem Detector는 Kubernetes 공식 GitHub 조직의 오픈소스 프로젝트이며, 실제 README도 문제를 NodeCondition과 Event로 apiserver에 보고한다고 설명한다.
발표 내용과 맞물려 보면, 카카오 사례에서 중요한 것은 단순히 특정 도구를 썼다는 점이 아니라 노드의 숨어 있는 장애 신호를 Kubernetes 이벤트 모델로 끌어올리는 방식이다.
Pod 가용성에서는 더 흥미로운 문제가 나온다.
Kubernetes는 Pod를 너무 잘 살려준다.
Pod가 죽어도 다른 노드에서 다시 살아나고, CronJob이 한 번 실패해도 다음 작업이 정상 동작할 수 있으며, Rolling Update의 중간 상태를 놓치기 쉽다.
코드 오류나 OOM으로 Pod가 반복 재시작되어도 겉으로는 서비스가 돌아가는 것처럼 보일 수 있다.
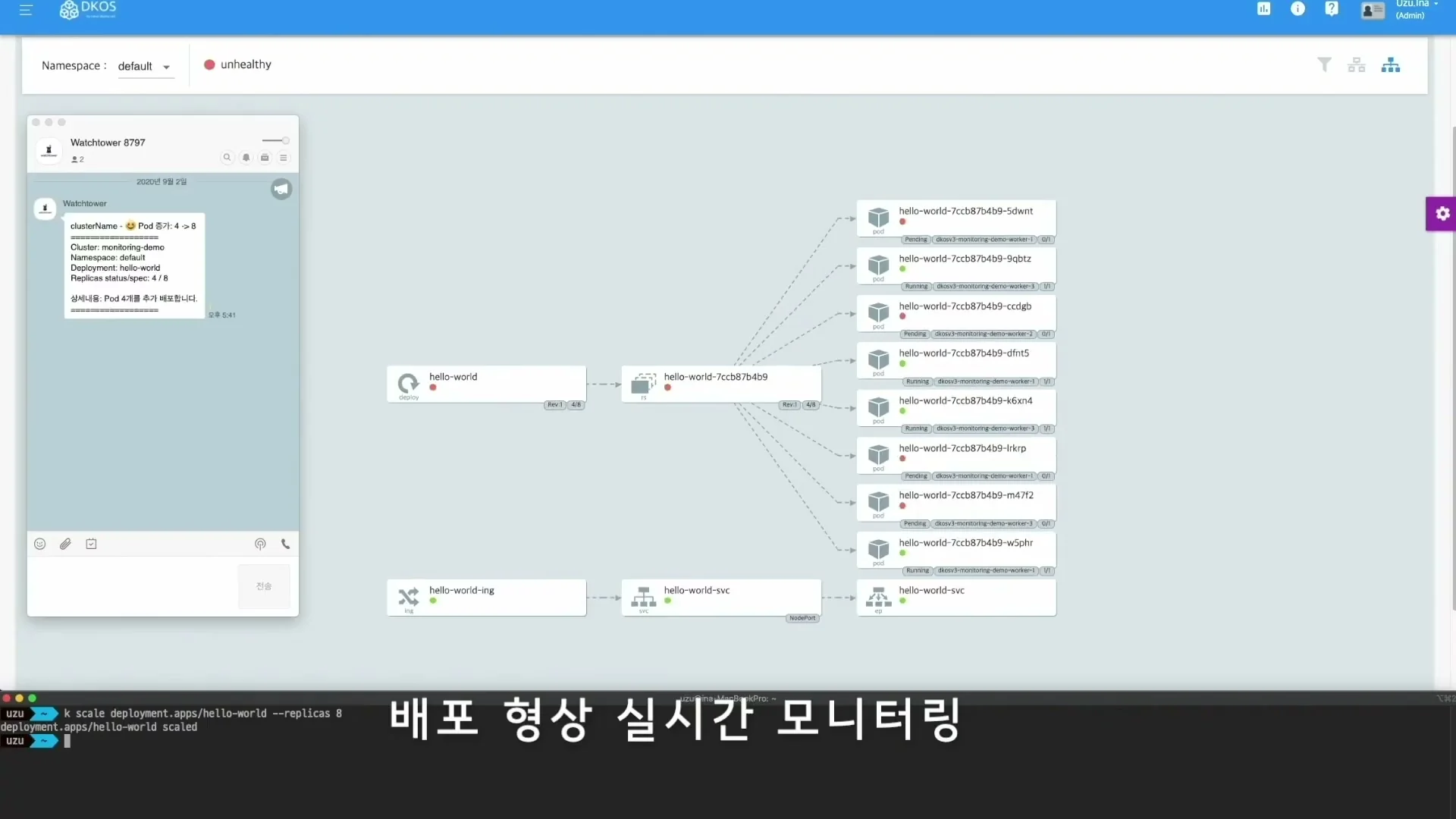
그래서 발표자는 Kubernetes 이벤트를 감지해 카카오톡이나 Slack으로 알림을 주는 Kube Event Watcher를 개발했다고 설명한다.
신규 배포 시작·진행·완료, 컨테이너 이미지 변경, 헬스체크 실패 같은 이벤트를 실시간으로 받아 운영자가 놓치지 않게 하는 흐름이다.

운영 문화는 DevOps, 온콜, 자동화로 닫힌다
발표 후반부는 서비스 운영으로 넘어간다.
여기서 발표자는 서비스데스크의 세부 프로세스보다 팀의 조직, 문화, 프로세스 철학이 더 중요하다고 말한다.
카카오의 해당 조직은 DevOps 조직으로 구성되어 있고, “우리가 짠 코드는 우리가 운영한다”는 모토 아래 개발자들이 주간 온콜에 참여한다고 설명한다.
이 대목은 Kubernetes 도입이 기술 프로젝트로만 끝나지 않는다는 점을 보여준다.
운영 이슈는 다시 개발 요구사항으로 들어가고, 개발·배포·운영에서 발생한 문제가 다시 백로그로 돌아간다.
플랫폼 팀의 품질 개선 루프가 조직 문화와 붙어 있어야 한다는 뜻이다.
운영 활동의 철학은 자동화로 정리된다.
발표는 온콜 업무를 QA, Service Request, Incident, Problem 등으로 분류하고, QA·서비스 요청·인시던트는 최대한 자동화하며, Problem은 지식 공유와 품질 향상을 통해 줄이려 한다고 설명한다.

예시는 클러스터 리소스 quota 증설 요청이다.
요청이 들어오면 자동으로 Jira 티켓이 등록되고 서비스 담당자가 지정된다.
담당자는 확인 후 댓글을 달거나 채팅 메시지를 입력하고, 관련 API 호출을 통해 처리가 자동화되며 결과도 자동으로 기록된다.
지금의 ChatOps나 platform self-service workflow와 매우 닮은 구조다.
타임라인으로 보는 핵심 구간
| 구간 | 핵심 장면 | 의미 |
|---|---|---|
| 00:11~02:14 | 발표자·주제 소개, DKOS와 D2Hub, 카카오의 Kubernetes 전환 계획 | Kubernetes 도입을 내부 플랫폼과 전사 전환 맥락에서 위치시킴 |
| 02:14~04:43 | ITSM 정의, 컨테이너 레이어, 토폴로지와 이벤트 공유 | Kubernetes 리소스를 전사 CMDB·운영 데이터로 연결해야 한다는 문제 제기 |
| 04:43~05:59 | 토폴로지·로그·성능 데모, Helm 기반 설치 정보와 CMDB 연계 | 실시간 운영 가시성과 버전·라이선스·보안 관리의 연결 가능성 제시 |
| 05:59~07:03 | 스토리지·로드밸런서 같은 외부 물리 자원 통합 | Custom Resource와 Controller로 데이터센터 자원을 Kubernetes 자원 모델에 통합해야 함 |
| 07:03~08:31 | ITIL 관점, SLA와 가용성 관리 | 인프라 uptime보다 서비스 관점 SLA가 중요하다는 설계 기준 제시 |
| 08:31~10:36 | Control plane, worker node, Node Problem Detector | 기본 상태값만으로 부족한 장애 신호를 NodeCondition과 Event로 확장 |
| 10:36~11:40 | Pod 가용성과 Kube Event Watcher | 자동 복구 때문에 숨겨지는 Pod·배포·헬스체크 이벤트를 알림으로 끌어냄 |
| 11:40~13:25 | DevOps 조직, 온콜, Agile, 자동화 철학 | 운영 이슈를 개발 요구사항으로 환류하고 반복 업무를 자동화하는 문화 설명 |
| 13:25~13:59 | 종합 정리 | 컨테이너 자원 관리, 토폴로지 공유, 이벤트 공유, CI/CD 정보, 외부 자원 통합, 운영 문화가 핵심이라고 요약 |
영상에서 확인되는 점과 한계
확인 가능한 사실은 비교적 선명하다.
카카오 사례의 핵심은 DKOS로 클러스터 생성 셀프서비스를 제공하고, D2Hub로 이미지 빌드와 멀티클러스터 배포를 연결한 뒤, 그 위에서 ITSM이 필요로 하는 운영 데이터를 수집·공유·자동화하는 것이다.
발표는 단일 서비스에 Kubernetes를 붙이는 문제가 아니라, 전사 서비스 전환에서 발생하는 조직적 연결 문제를 다룬다.
다만 이 영상만으로 확인할 수 없는 부분도 있다.
설명란에는 발표 자료, 아키텍처 문서, DKOS/D2Hub 구현 세부 링크가 없다.
따라서 수만 대 서버, 수십만 컨테이너, 카카오톡 전체 시스템 전환, 내년까지 전사 전환 같은 숫자와 계획은 발표자가 영상에서 말한 당시 맥락으로 읽어야 한다.
현재 상태나 이후 결과까지 이 영상만으로 검증할 수는 없다.
또한 자동 자막 기반 분석이므로 일부 기술명은 문맥으로 보정했다.
예를 들어 D2Hub, Kubernetes, ITSM, Node Problem Detector, Custom Resource Definition, Custom Controller처럼 발표 흐름상 명확한 용어는 정정했지만, 내부 프로젝트의 정확한 표기나 화면의 세부 항목은 원 영상 확인이 필요하다.

실무 관점에서의 해석
이 발표의 메시지는 지금의 플랫폼 엔지니어링 팀에도 그대로 적용된다.
Kubernetes 도입의 성공 기준은 클러스터를 만들었는지가 아니라, 그 클러스터가 조직의 서비스 관리 체계 안으로 들어왔는지다.
개발자에게 셀프서비스를 제공하더라도, 보안팀·재무팀·운영팀·서비스 담당자가 필요한 정보를 얻지 못하면 전사 도입은 병목을 다른 곳으로 옮긴 것에 불과하다.
특히 중요한 것은 Kubernetes가 가진 선언적 상태와 이벤트를 ITSM의 공용 언어로 바꾸는 일이다.
Pod, Deployment, Service, Ingress, Node, Custom Resource는 클러스터 내부 객체이지만, 조직 입장에서는 소유권, 비용, SLA, 장애 영향, 변경 이력, 보안 노출면, 라이선스와 연결되어야 한다.
좋은 플랫폼은 이 번역을 자동화한다.
또 하나의 교훈은 가용성 관리다.
Kubernetes는 실패를 숨길 정도로 복구를 잘한다.
그래서 오히려 운영자는 더 정교한 이벤트 관찰과 알림이 필요하다.
노드의 커널·로그 기반 문제, Pod의 반복 재시작, 배포 중간 상태, CronJob 누락, 헬스체크 실패 같은 신호를 놓치면, 서비스가 “대체로 살아 있는” 동안 품질 문제가 누적될 수 있다.
마지막으로 운영 자동화는 도구가 아니라 루프다.
온콜에서 반복되는 요청을 분류하고, 서비스 요청과 인시던트를 자동화하고, Problem은 지식 공유와 품질 개선으로 줄이는 구조가 있어야 한다.
이 루프가 있어야 Kubernetes 도입은 인프라 현대화가 아니라 운영 체계의 개선으로 이어진다.
결국 이 if(kakao)2020 발표는 오래된 Kubernetes 성공담이라기보다, 엔터프라이즈 플랫폼 팀이 여전히 풀고 있는 질문을 선명하게 보여주는 사례다.
클러스터를 만드는 능력은 출발점일 뿐이다.
진짜 어려운 일은 Kubernetes에서 발생하는 동적 상태를 조직 전체가 신뢰할 수 있는 서비스 관리 데이터로 바꾸는 것이다.