대부분의 AI agent는 아직 반응형이다.
사용자가 “이 파일 요약해줘”, “이 테스트 고쳐줘”, “이 일정 잡아줘”라고 말하면 움직인다.
그런데 실제 업무 환경에서는 사용자가 이미 알아차린 문제만 요청으로 올라온다.
이메일, 문서, 캘린더, 코드베이스 안에는 서로 다른 병목과 버그가 동시에 숨어 있을 수 있고, 사용자는 그 개수조차 모를 수 있다.
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration는 이 지점을 정면으로 다룬다.
논문은 proactive assistance를 “사용자에게 다음에 필요할 것 같은 하나의 행동을 추천하는 문제”가 아니라, 넓은 context에서 여러 hidden problem을 발견하고, 각각을 evidence와 resolution action으로 묶는 문제로 재정의한다.
이름 그대로 TIDE는 Template-guided Iterative Discovery and rEsolution이다.
흥미로운 점은 “에이전트를 여러 개 병렬로 돌리면 더 많은 문제가 나오겠지”라는 직관을 그대로 받아들이지 않는다는 것이다.
논문 실험에서 독립적인 multi-agent baseline은 같은 salient signal에 반복적으로 anchoring되는 경향을 보인다.
TIDE의 핵심은 병렬화보다 누적 발견 상태를 다음 round의 조건으로 넣어, 이미 찾은 문제 바깥으로 모델의 주의를 밀어내는 것이다.
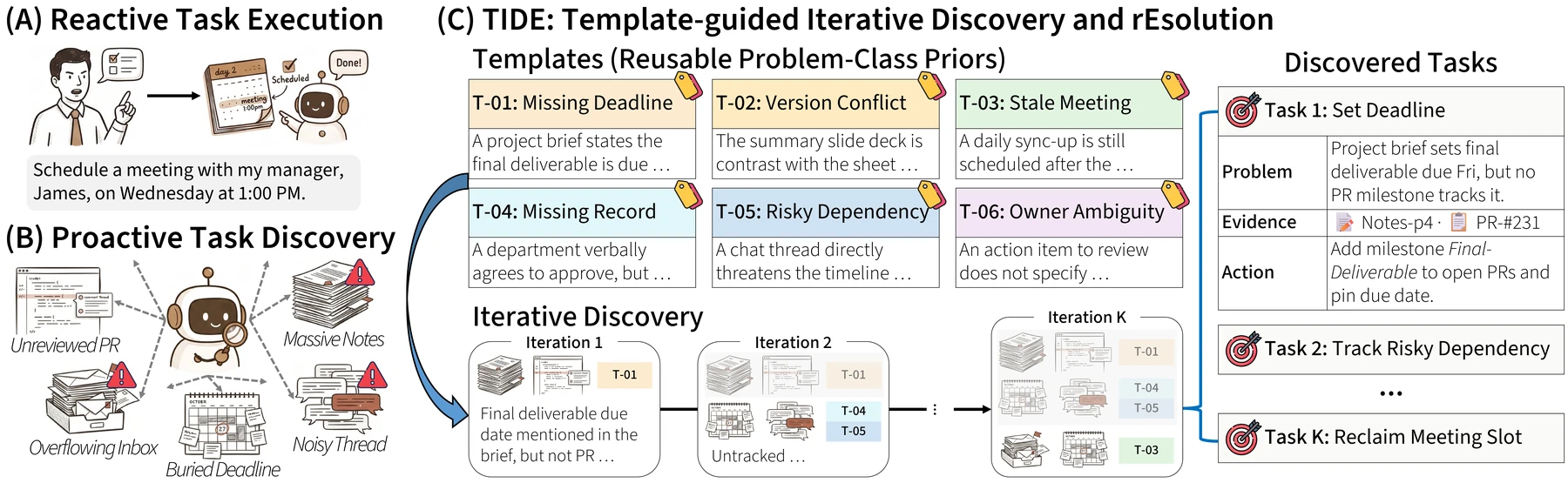
무엇을 해결하려는가
논문이 정의하는 hidden-problem discovery의 입력은 문서·이메일·캘린더·코드 함수 같은 artifact collection D다.
이 안에는 사용자가 직접 요청하지 않은 잠재 문제 집합 P*가 있고, 그 개수 n은 미리 알려져 있지 않다.
에이전트의 출력은 단순한 문제 목록이 아니라 각 문제마다 (problem description, supporting evidence, resolution action)을 포함하는 triple이다.
이 정의가 중요한 이유는 proactive agent의 실패 모드를 더 정확히 드러내기 때문이다.
사용자가 명시한 intent를 조금 더 잘 예측하는 문제와, 아직 사용자가 모르는 여러 병목을 context에서 찾아내는 문제는 다르다.
후자는 coverage와 fidelity를 동시에 요구한다.
많이 찾되, 아무 말이나 늘어놓으면 안 되고, 각 문제는 실제 artifact evidence에 grounded되어야 하며, 실행 가능한 조치까지 붙어야 한다.
논문은 single-shot discovery가 두 가지 이유로 약하다고 본다.
첫째, 가장 눈에 띄는 문제에 모델의 attention이 고정되어 subtler issue가 묻힌다.
둘째, 어떤 evidence pattern이 어떤 문제 class를 시사하는지에 대한 재사용 가능한 prior가 없으면 prediction이 generic하거나 speculative해진다.
TIDE는 이 둘을 각각 iterative discovery와 thought template로 처리한다.
핵심 아이디어 / 구조 / 동작 방식
TIDE의 첫 번째 구성 요소는 thought template다.
각 template는 recurring hidden problem class를 나타내는 이름, structural pattern, evidence flow를 가진다.
예를 들어 workspace setting에서는 “마감 직전 source-of-truth가 충돌해 sign-off가 막히는 문제” 같은 template가 있을 수 있다.
이 template는 “deliverable과 cited source를 찾고, channel별 conflicting copy를 확인하고, 시간 제한이 있는 review와 owner에 연결하라”는 식의 evidence flow를 제공한다.
Template는 inference 때 새로 즉흥 생성되는 것이 아니라, solved training case에서 한 번 뽑아 둔 library로 유지된다.
논문은 개인 workspace setting에서 40개, software repository setting에서 108개의 template를 구성했다고 보고한다. inference 때 에이전트는 전체 context D, template set T, 그리고 이전 round까지의 누적 발견 상태를 함께 본다.
두 번째 구성 요소는 iterative discovery다.
한 번에 모든 문제를 내라고 하지 않고, 각 round에서 작은 batch의 candidate problem을 찾는다.
이후 P^(t) = P^(t-1) ∪ ΔP^(t)처럼 누적 상태를 업데이트하고, 다음 round는 이미 찾은 bottleneck을 조건으로 받는다.
그래서 모델은 같은 obvious issue를 반복하기보다 아직 발견되지 않은 다른 문제로 이동할 압력을 받는다.
| 구성 요소 | 역할 | 실무적 해석 |
|---|---|---|
| Thought Template | solved case에서 추출한 문제 class와 evidence flow를 재사용 | “무엇을 단서로 봐야 하는가”를 모델에게 알려주는 discovery schema |
| Iterative Discovery | 여러 round에 걸쳐 소수의 문제를 찾고 누적 상태를 다음 round에 전달 | 같은 salient issue 재발견을 줄이고 long-tail 문제로 attention을 이동 |
| Triple Output | description, evidence subset, action을 함께 출력 | 단순 알림이 아니라 검증 가능한 task plan으로 surface |
이 구조는 agent orchestration 관점에서 꽤 실용적이다.
병렬 agent를 늘리는 방식은 compute를 늘려도 서로가 무엇을 찾았는지 모른다.
반면 TIDE는 “이미 발견된 것”을 다음 호출의 context policy로 사용한다.
즉 proactivity를 one-shot suggestion이 아니라 stateful search process로 만든다.
공개된 근거에서 확인되는 점
논문은 두 종류의 realistic setting을 만든다.
첫째는 개인 workspace다.
각 instance는 사용자 profile, 문서, 이메일, 캘린더 항목으로 구성되고, 문제 하나는 여러 artifact를 엮어야 드러난다.
이 setting은 30개 workspace, 150개 problem으로 구성되며 workspace당 46개 problem과 88113개 candidate artifact가 들어간다.
둘째는 software repository다.
SWE-bench와 TestExplora 기반 Python repository에서 같은 snapshot에 여러 unresolved bug가 공존하는 case를 만든다.
각 problem은 실제 GitHub issue와 이를 고친 PR patch에 대응한다.
최종적으로 11개 project에서 나온 20개 multi-bug instance, 146개 problem이며 instance당 241개 problem, 6646개 candidate function을 가진다.
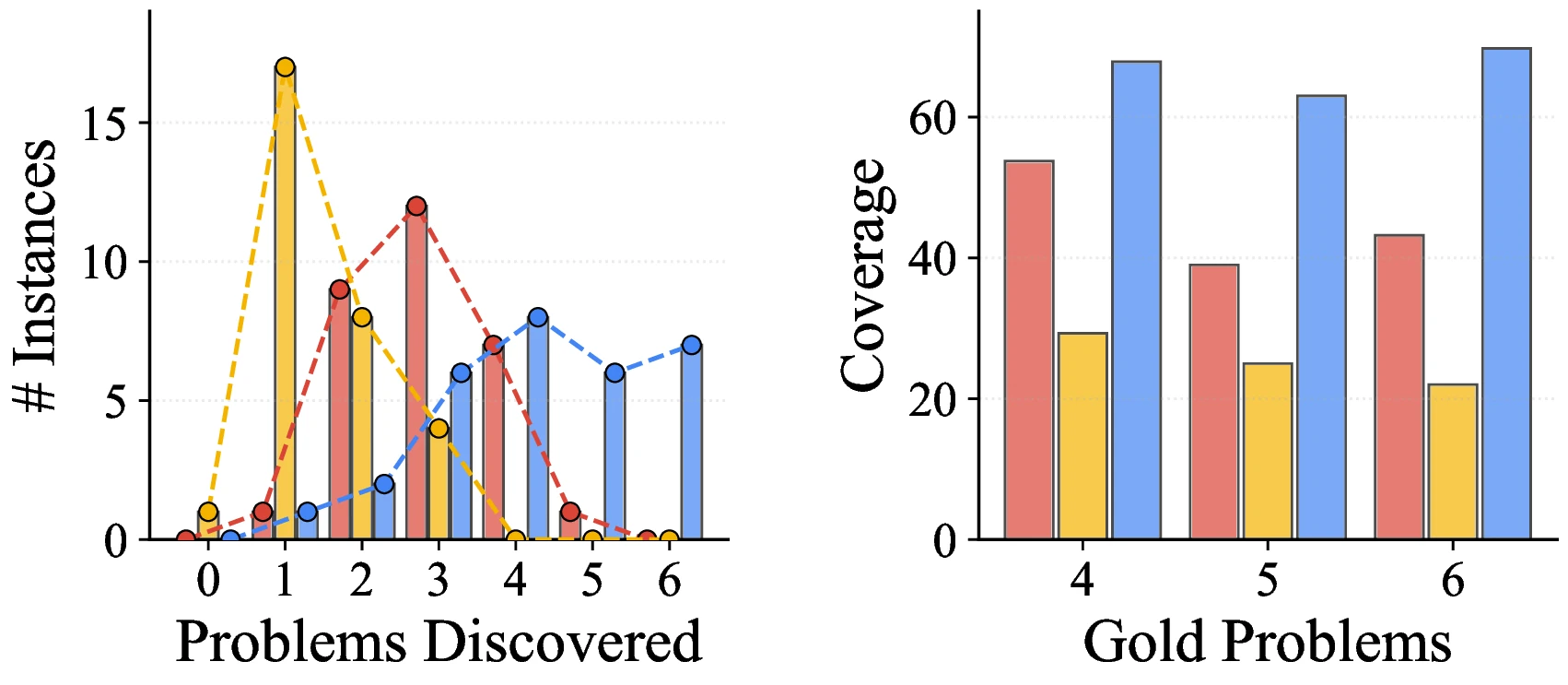
평가는 retrieval, identification, resolution 세 축으로 나뉜다. retrieval은 predicted evidence ID와 gold evidence ID의 overlap으로 측정하고, identification과 resolution은 gold description/action 대비 LLM judge가 Likert-style rubric으로 채점한다. aggregate metric은 gold problem을 얼마나 회수했는지 보는 coverage와, 중복·spurious prediction까지 벌점화하는 F1이다.
주요 결과는 네 backbone 모두에서 TIDE가 Single-Agent와 Multi-Agent보다 높은 평균 점수를 보인다는 것이다.
특히 Gemini backbone에서는 평균 47.04로 Single-Agent 31.83, Multi-Agent 30.62보다 높다.
GPT backbone에서도 TIDE 44.56, Single-Agent 31.56, Multi-Agent 23.59로 차이가 크다.
| Backbone | Single-Agent Avg. | Multi-Agent Avg. | TIDE Avg. | 읽을 포인트 |
|---|---|---|---|---|
| GPT | 31.56 | 23.59 | 44.56 | 병렬 agent보다 누적 상태를 쓰는 iteration이 더 효과적 |
| Gemini | 31.83 | 30.62 | 47.04 | 네 backbone 중 가장 높은 TIDE 평균 |
| Claude | 16.39 | 19.65 | 32.86 | baseline이 낮은 조건에서도 template+iteration의 이득이 유지 |
| Qwen | 20.90 | 22.04 | 30.46 | smaller/fast model 계열에서도 동일한 방향의 개선 |
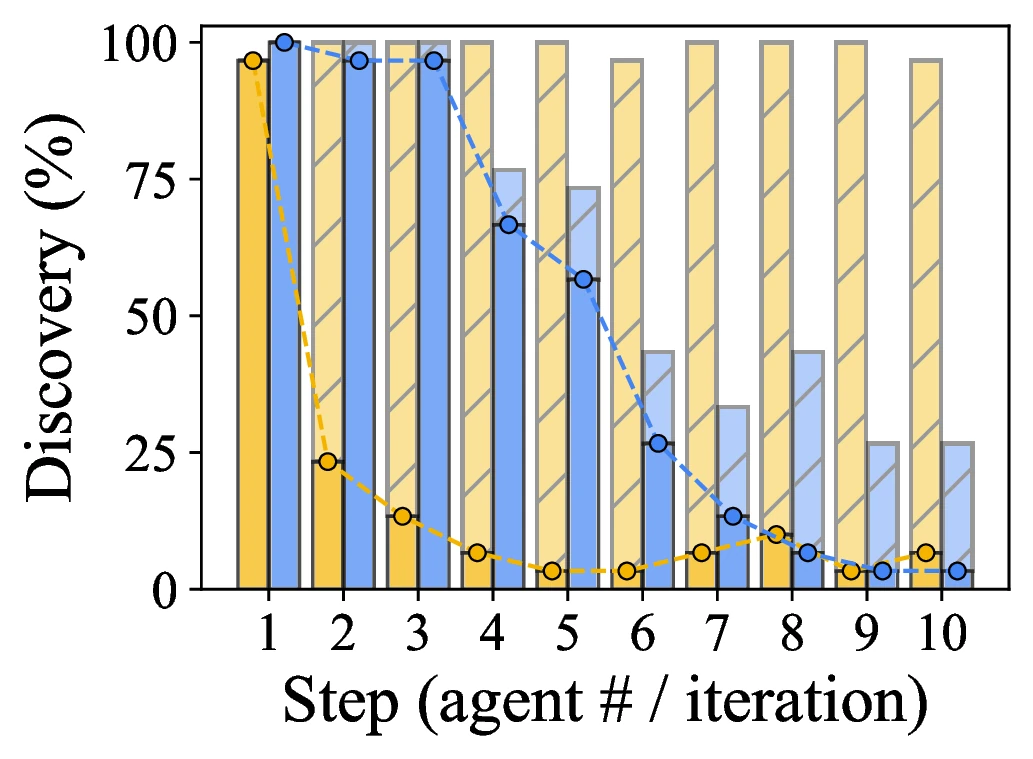
논문이 특히 잘 보여 주는 부분은 multi-agent baseline의 한계다.
같은 LLM-call budget에서 여러 agent를 독립적으로 돌리면, 두 번째 step 이후부터 새 문제보다 이미 발견한 문제를 다시 찾는 비중이 커진다.
반면 TIDE는 이전 발견 상태를 조건으로 받기 때문에 이후 step에서도 새 문제를 계속 더한다.
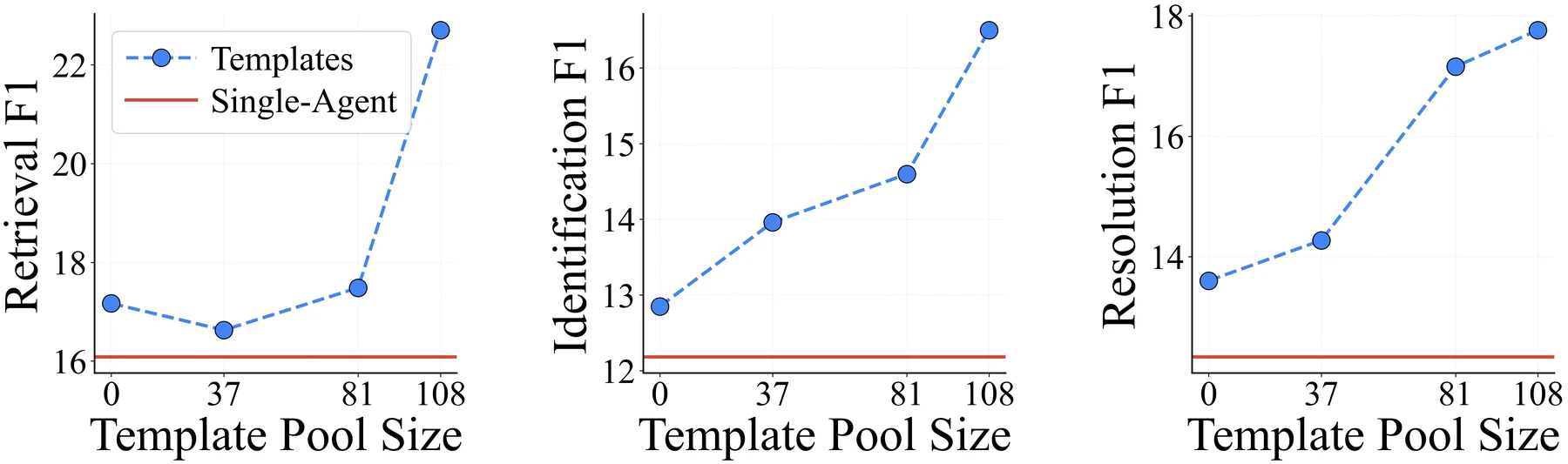
Template가 단순 few-shot example의 대체물인지도 따로 비교한다.
Repository setting의 GPT 실험에서 raw demonstration을 넣은 Iter. + Demos는 retrieval F1 11.43, identification F1 12.80, resolution F1 12.80에 그친다.
TIDE는 같은 축에서 각각 18.61, 19.73, 17.39를 기록한다.
즉 solved case를 그대로 보여주는 것보다, 문제 class와 evidence flow를 추상화한 template가 더 잘 작동한다는 주장이다.
또 하나 흥미로운 결과는 template transferability다.
Repository setting에서 GPT inference에 Gemini template를 넣거나, Gemini inference에 GPT template를 넣어도 성능이 크게 무너지지 않는다.
논문은 이를 template가 특정 model의 surface wording보다 problem pattern 자체를 어느 정도 담고 있다는 근거로 해석한다.
공개 표면도 구분해서 봐야 한다. arXiv abstract, HTML, TeX source를 확인했을 때 별도 공식 GitHub repository나 project page 링크는 논문 자체에 명시되어 있지 않았다.
따라서 현재 근거의 중심은 공개 구현 성숙도나 재현 패키지라기보다, arXiv 논문 안의 task formulation, benchmark construction, table/figure 결과다.
실무 관점에서의 해석
TIDE의 가장 좋은 메시지는 proactive agent를 “먼저 말을 거는 assistant” 정도로 낮추지 않는다는 점이다.
실제 조직의 context에는 미처 티켓으로 올라오지 않은 일, 서로 충돌하는 문서, 일정·승인·권한 병목, 여러 함수에 흩어진 같은 버그가 동시에 존재한다.
이런 상황에서는 다음 action 하나를 추천하는 것보다 문제 공간 자체를 반복적으로 탐색하는 agent loop가 더 중요하다.
Hermes나 사내 agent runtime 관점에서 보면, 이 논문은 heartbeat나 background monitor의 설계에도 힌트를 준다.
단순히 “새 이메일 있나?”
를 한 번 요약하는 것이 아니라, 이미 발견한 병목을 state로 유지하고 다음 scan에서는 다른 class의 문제를 찾게 만들 수 있다. template는 여기서 domain-specific checklist와 비슷한 역할을 한다.
예를 들어 “승인 대기 때문에 외부 일정이 막힘”, “두 문서의 숫자가 충돌함”, “여러 코드 경로에 같은 invariant violation이 있음” 같은 pattern을 재사용할 수 있다.
다만 도입에는 조심할 점이 있다.
첫째, template library가 고정되어 있으면 새로운 조직·도메인의 문제 class를 놓칠 수 있다.
논문도 online update나 automatically constructed case를 향후 방향으로 적는다.
둘째, workspace context는 민감한 문서와 관계 정보를 포함하므로, template construction과 deployment 모두에서 filtering, bias detection, human-in-the-loop review가 필요하다.
셋째, evaluation에서 identification과 resolution을 LLM judge가 채점하기 때문에 실제 운영 품질은 사람 검토와 downstream execution success로 다시 확인해야 한다.
또 하나의 현실적 caveat는 비용이다.
TIDE는 multiple round를 쓰기 때문에 one-shot보다 호출 수가 늘어난다.
논문은 workspace에서 T=10, repository에서 T=3 round를 사용하고 empty batch가 나오면 조기 종료한다.
따라서 모든 context scan에 무조건 적용하기보다, 높은 가치의 workspace review, release 전 codebase sweep, 장기 프로젝트 health check처럼 “숨은 문제를 더 많이 찾는 것” 자체가 가치 있는 상황에 먼저 쓰는 편이 자연스럽다.
내 해석으로 TIDE는 “proactive agent가 무엇을 해야 하는가”에 대한 꽤 선명한 답을 준다.
사용자를 대신해 막무가내로 행동하는 것이 아니라, 사용자가 아직 질문하지 않은 문제 후보를 evidence와 action plan으로 표면화하고, 사람이 승인하거나 우선순위를 정할 수 있게 만드는 것이다.
이 프레임은 자율성을 키우면서도 인간 검토 경계를 유지하기 좋은 설계다.