웹 자동화 에이전트를 만들 때 흔한 접근은 “지금 화면을 보고 다음 클릭 하나를 고른다”는 루프다.
Webwright는 그 반대로 간다.
브라우저는 오래 붙잡고 있는 상태가 아니라, 코딩 에이전트가 필요할 때 띄우고 버릴 수 있는 실행 환경이다.
오래 남는 것은 브라우저 세션이 아니라 Python 코드, 실행 로그, 스크린샷, 재실행 가능한 결과물이다.
microsoft/Webwright는 Microsoft Research가 공개한 작은 Python 기반 브라우저 에이전트 harness다.
README의 표현을 빌리면 “terminal is all you need for web agents”에 가깝다.
모델은 터미널에서 bash command를 내고, 그 command가 Playwright 스크립트를 작성·실행하며, 실패하면 파일과 스크린샷을 보고 고쳐 나간다.
조사 시점 기준 저장소는 MIT 라이선스의 공개 repo이고, GitHub API 기준 주 언어는 Python이다.
별도 GitHub Release나 tag는 아직 없으며, pyproject.toml과 Claude/Codex plugin manifest의 버전은 0.1.0이다.
빠르게 주목받는 프로젝트지만 패키지로 안정 배포된 도구라기보다는 연구 코드 + 에이전트 skill/plugin bundle에 가깝게 보는 편이 맞다.
![]()
Webwright 개요
Webwright의 핵심은 “브라우저를 직접 조작하는 에이전트”보다 “브라우저 작업을 코드로 개발하는 에이전트”에 있다.
기본 실행 흐름은 대략 이렇다.
- 사용자가 자연어 task와 시작 URL을 준다.
- Webwright runner가 모델에게 현재 workspace와 최근 observation을 전달한다.
- 모델은 bash command 하나를 내고, 그 안에서 Playwright 기반 탐색/실행 스크립트를 만든다.
- 실행 결과, 로그, 스크린샷, 최근 파일 목록이 다음 observation으로 돌아간다.
- 마지막에는
final_script.py와final_runs/run_<id>/아래의 스크린샷·로그로 결과를 검증한다.
이 구조가 재미있는 이유는 웹 작업의 “행동 단위”가 클릭 하나가 아니라 코드 조각이 된다는 점이다.
날짜 선택, 검색 조건 적용, 페이지네이션, 표 추출, 여러 사이트 비교 같은 작업을 함수·루프·재시도 로직으로 묶을 수 있고, 성공한 스크립트는 나중에 같은 유형의 작업에 다시 쓸 수 있다.
설치와 첫 실행
README가 제시하는 직접 실행 경로는 아직 PyPI 패키지 설치가 아니라 source checkout 후 editable install이다.
git clone https://github.com/microsoft/Webwright
cd Webwright
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
playwright install chromium
그다음 선택한 backend credential을 환경변수로 넣고 CLI를 실행한다.
export OPENAI_API_KEY="..."
python -m webwright.run.cli \
-c base.yaml -c model_openai.yaml \
-t "Search for flights from SEA to JFK on 2026-08-15 to 2026-08-20" \
--start-url https://www.google.com/flights \
--task-id demo_openai \
-o outputs/default
pyproject.toml에는 console script webwright = webwright.run.cli:app도 정의되어 있지만, README 예시는 python -m webwright.run.cli를 기준으로 설명한다.
직접 실행 모드의 기본 dependency는 Python >=3.10, httpx, pydantic, pyyaml, rich, typer, playwright, python-dotenv, platformdirs 등이다.
중요한 함정도 있다.
PyPI의 webwright 패키지명은 이미 다른 프로젝트가 쓰고 있고, 그 패키지는 MittaAI/webwright로 연결된다.
Microsoft Research의 Webwright를 기대한다면 pip install webwright가 아니라 저장소를 clone해서 pip install -e .로 설치해야 한다.
코딩 에이전트 plugin/skill로 쓰기
Webwright가 단순 Python CLI보다 흥미로운 지점은 저장소 안에 agent plugin/skill 표면이 같이 들어 있다는 점이다.
Claude Code 쪽은 repo를 plugin marketplace로 추가한 뒤 설치하는 흐름이다.
/plugin marketplace add microsoft/Webwright
/plugin install webwright@webwright
Codex CLI도 같은 repo를 marketplace로 읽는 방식이 README에 정리되어 있다.
codex plugin marketplace add microsoft/Webwright
codex
/plugins
또 skills/webwright/ 폴더는 Claude Code, Codex, OpenClaw, Hermes Agent 같은 skills-compatible agent에서 읽을 수 있게 작성되어 있다.
이 모드에서는 Webwright의 원래 OpenAI/Anthropic 모델 루프를 그대로 돌린다기보다, host 코딩 에이전트가 Playwright 작업공간 계약을 따라 직접 계획·탐색·스크립트 작성·스크린샷 검증을 수행한다.
README도 이 경로에서는 “host subscription 외 추가 LLM API key가 필요 없다”고 설명한다.
즉 Webwright를 보는 관점은 두 가지다.
- 독립 Python harness: OpenAI, Anthropic, OpenRouter 설정으로 Webwright 자체 agent loop를 실행한다.
- 에이전트 능력 확장 skill/plugin: Claude Code나 Codex 같은 코딩 에이전트에 “브라우저 작업을 코드로 풀고 검증하는 작업방식”을 주입한다.
왜 유용한가
Webwright가 잘 맞는 상황은 “한 번 클릭하고 끝나는 웹 browsing”보다 긴 흐름을 재현 가능한 자동화로 바꾸고 싶은 경우다.
예를 들면 다음 같은 작업이다.
- 항공권·숙소·채용공고·상품 목록처럼 조건과 정렬이 많은 웹 검색
- 여러 페이지를 돌며 표나 카드 형태의 결과를 수집하는 작업
- 매번 값만 바꿔 다시 실행하고 싶은 RPA 스타일 workflow
- 실패 시 어느 selector, 어느 screenshot, 어느 command에서 깨졌는지 추적해야 하는 웹 에이전트 실험
- 기존 코딩 에이전트에게 “브라우저 task를 그냥 답하지 말고, 검증 가능한 스크립트로 남겨라”는 절차를 주고 싶은 경우
README와 project page는 Webwright가 Online-Mind2Web, Odysseys 같은 live-web benchmark에서 강한 결과를 냈다고 보고한다.
이 수치들은 모델, step budget, benchmark split, 평가 방식에 묶인 연구 결과이므로 그대로 제품 성능 보증처럼 받아들이기보다는, Webwright가 지향하는 code-as-action 패러다임의 근거로 보는 편이 좋다.
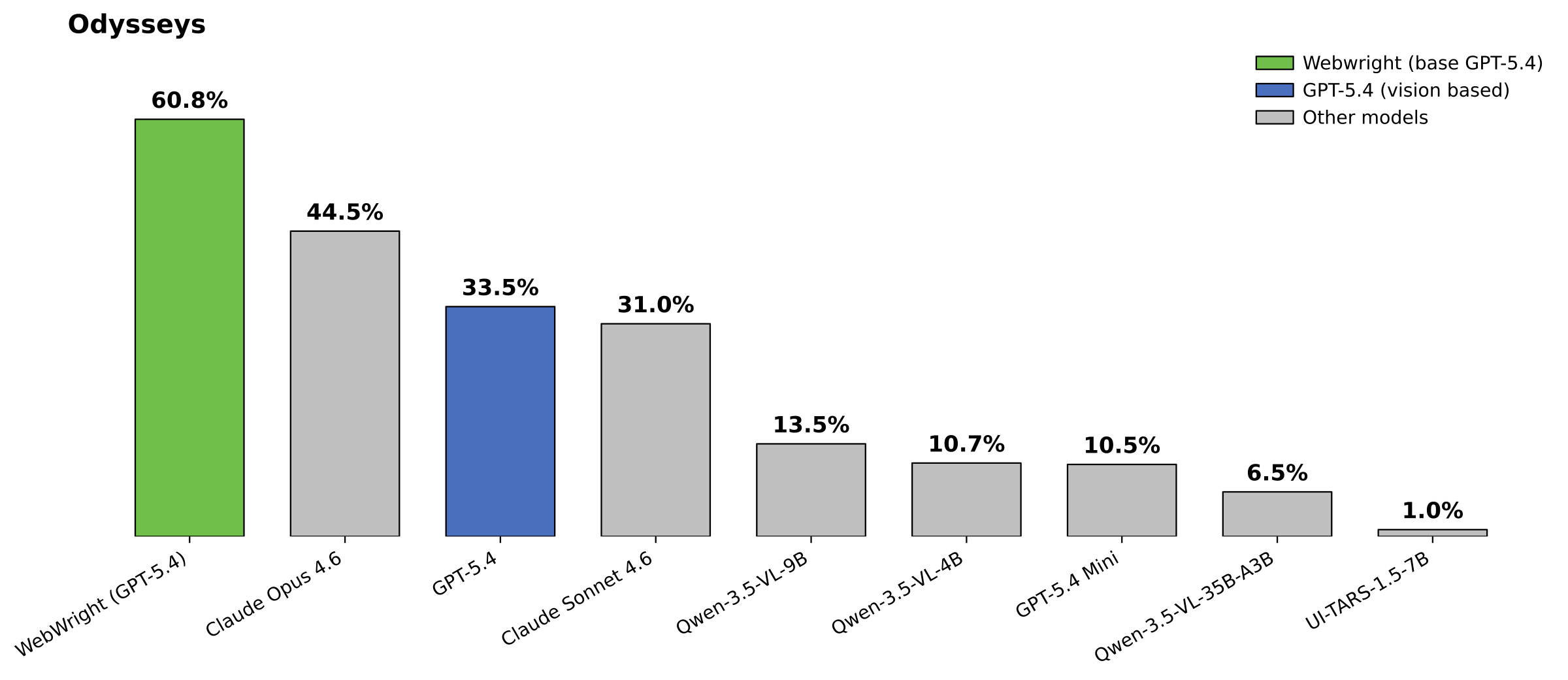
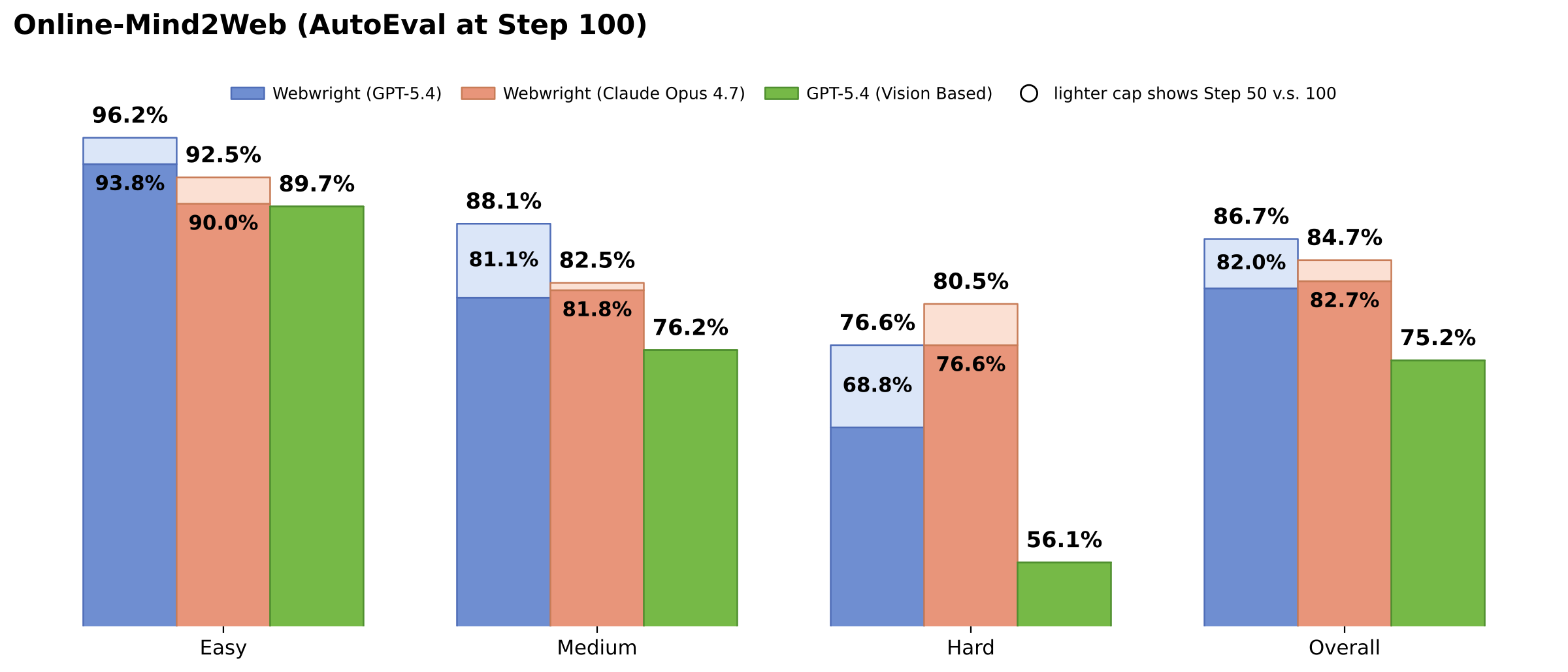
작업공간 산출물 중심 설계
Webwright의 기본 산출물은 답변 한 줄이 아니다.
실행 중에는 output directory 아래에 config snapshot, trajectory.json, runtime error log, command history, screenshot, final_script.py 같은 파일이 쌓인다.
Task Showcase overlay를 켜면 report.json과 task.json을 만들어 Flask dashboard로 렌더링하는 예시도 포함되어 있다.
이 점은 디버깅과 재사용에 유리하다.
“에이전트가 왜 그렇게 클릭했는지”를 묻는 대신, 실제로 어떤 command가 실행됐고 어떤 스크린샷을 근거로 성공 판단을 했는지를 파일로 따라갈 수 있다.
실패한 task도 다음 실행에서 고칠 수 있는 코드 artifact로 남는다.
반대로 말하면 출력 폴더는 민감할 수 있다.
웹 task 설명, 방문 URL, 화면 캡처, 추출 결과, model error log, command history가 함께 남을 수 있으므로 공유·백업·git add 범위를 조심해야 한다.
주의할 점
첫째, 아직 release/tag가 없는 초기 공개 repo다.
README와 project page는 빠르게 업데이트되고 있지만, 안정된 패키지 릴리스나 versioned documentation을 전제로 도입하면 곤란하다.
실험에 쓰려면 commit hash를 pinning하고, 내부 workflow에 넣기 전에 작은 task로 재현성을 확인하는 편이 좋다.
둘째, Webwright는 일반 라이브러리보다 로컬 실행 권한이 큰 에이전트 runtime에 가깝다. local_workspace 환경은 모델이 낸 command를 shell로 실행하고, 작업공간 안에 script/log/screenshot을 남긴다.
코드상 cwd는 output workspace 안으로 제한되지만, 셸 명령 자체가 실행되는 구조라는 점은 변하지 않는다.
신뢰하지 않는 prompt, 외부 skill/plugin, 민감한 repo에서 바로 돌리는 것은 피하는 편이 안전하다.
셋째, credential 경계를 분리해야 한다.
직접 실행 모드는 OPENAI_API_KEY, ANTHROPIC_API_KEY, OPENROUTER_API_KEY 같은 provider key를 읽고, Browserbase 모드를 쓰면 BROWSERBASE_API_KEY, BROWSERBASE_PROJECT_ID도 필요할 수 있다. credentials_file을 쓰는 경우 해당 파일과 output artifact가 backup/sync/스크린샷에 섞이지 않게 해야 한다.
넷째, local browser mode와 persistent/local CDP helper를 쓸 때 로그인된 브라우저 profile을 무심코 붙이면 웹 계정 세션과 자동화 task가 같은 경계에 놓인다.
특히 쇼핑, 금융, 회사 admin page, 내부 dashboard처럼 부작용이 있는 사이트에서는 별도 test account와 격리 profile을 쓰는 편이 낫다.
마지막으로, Claude/Codex/OpenClaw/Hermes plugin/skill 경로는 편하지만 신뢰 경계가 더 넓어진다.
설치한 skill은 코딩 에이전트의 작업 절차와 tool 사용 방식을 바꾼다. marketplace에서 최신 default branch를 바로 읽는 대신, 팀 환경에서는 검토한 commit으로 고정하고 skill 내용을 리뷰한 뒤 배포하는 편이 안전하다.
내 판단
Webwright는 “브라우저를 보는 에이전트”보다 “브라우저 자동화 스크립트를 개발하는 에이전트”가 더 강하다는 가설을 아주 미니멀하게 구현한 프로젝트다.
대형 orchestration framework 없이 터미널, 파일, Playwright, 모델 backend만으로 긴 웹 task를 푸는 구조라서 연구용으로 읽기 좋고, 실제 에이전트 workflow에 가져와 실험하기도 쉽다.
내 기준으로는 두 부류에게 특히 유용하다.
하나는 web-agent benchmark나 RPA-style agent를 직접 실험하는 사람이다.
다른 하나는 Claude Code/Codex/Hermes 같은 코딩 에이전트에게 “웹에서 찾아서 결과만 말해”가 아니라 “재실행 가능한 스크립트와 검증 evidence를 남겨”라고 시키고 싶은 사람이다.
반대로 안정 패키지, 사내 표준 자동화 도구, GUI 없는 간단 스크래퍼만 원하는 경우라면 아직은 과하다.
Release/tag가 생기고 install surface가 정리될 때까지는 작은 repo/샌드박스에서 task별로 검증하면서 쓰는 편이 좋다.