Apple Silicon Mac에서 로컬 LLM을 돌릴 때 가장 귀찮은 부분은 모델 실행 자체보다 이미 쓰고 있는 도구들이 기대하는 API 모양을 맞추는 일이다.
Cursor, Aider, LangChain, Open WebUI 같은 클라이언트는 대부분 OpenAI API 호환 endpoint를 잘 받지만, 로컬 inference 서버가 tool calling, streaming, 긴 context, reasoning 분리까지 자연스럽게 처리해줘야 실제 워크플로에 들어간다.
Rapid-MLX는 이 지점을 겨냥한 MLX 기반 inference 서버다.
Hugging Face의 MLX quantized 모델을 Apple Silicon 통합 메모리 위에서 로드하고, http://localhost:8000/v1 형태의 OpenAI-compatible API로 내보낸다.
README 기준 최신 릴리스와 PyPI 버전은 v0.6.35 / 0.6.35, Python 요구사항은 3.10+, 라이선스는 Apache-2.0이다.
Rapid-MLX 개요
Rapid-MLX를 한 문장으로 줄이면 Mac을 로컬 AI API 서버로 바꾸는 Apple Silicon 전용 엔진이다.
단순히 CLI에서 채팅하는 도구라기보다, 다음 레이어를 한꺼번에 제공하는 backend에 가깝다.
- 서빙 표면:
/v1/chat/completions,/v1/completions,/v1/models,/v1/embeddings,/health, Anthropic-compatible/v1/messages - 모델 로딩:
mlx-community/...Hugging Face 모델 ID, local path, 짧은 alias(qwen3.5-4b,nemotron-30b,qwen3-vl-4b등) - 클라이언트 호환성: Cursor, Claude Code/OpenClaude, Aider, OpenCode, Goose, Continue.dev, PydanticAI, LangChain, smolagents, Open WebUI, LibreChat
- 추론 기능: streaming, continuous batching, paged/prefix cache, tool calling parser, reasoning parser, structured JSON, logprobs, multimodal/embedding/audio extras
- 운영 옵션: API key, rate limit, timeout, MCP config, cloud routing, telemetry opt-in/disable CLI
프로젝트가 흥미로운 이유는 “MLX로 모델을 실행한다”에서 멈추지 않고, agent harness와 tool calling까지 제품 표면에 넣었다는 점이다.
README는 Model-Harness Index(MHI)라는 이름으로 Hermes Agent, PydanticAI, LangChain, smolagents 같은 harness와의 tool calling/코딩/지식 평가를 함께 보여준다.
즉 로컬 모델을 단순 Q&A용으로만 쓰는 것이 아니라, coding agent backend로도 쓰려는 방향이 분명하다.
설치와 첫 사용법
공식 README의 추천 설치는 Homebrew tap이다.
Python 버전 이슈를 피하고 싶다면 이 경로가 가장 간단하다.
brew install raullenchai/rapid-mlx/rapid-mlx
Python 환경을 직접 관리한다면 PyPI 패키지도 제공된다. macOS 기본 Python이 3.9인 경우가 많으므로 python3 --version을 먼저 확인하는 편이 좋다.
pip install rapid-mlx
자동 설정 스크립트도 있다.
curl -fsSL https://raullenchai.github.io/Rapid-MLX/install.sh | bash
가장 작은 첫 실행 흐름은 다음과 같다.
첫 실행에서는 모델을 내려받기 때문에 디스크와 네트워크 시간이 필요하다.
rapid-mlx serve qwen3.5-4b
서버가 준비되면 다른 터미널에서 OpenAI API처럼 호출한다.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"default","messages":[{"role":"user","content":"Say hello"}]}'
Python SDK도 base URL만 바꾸면 된다.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
response = client.chat.completions.create(
model="default",
messages=[{"role": "user", "content": "Say hello"}],
)
print(response.choices[0].message.content)
모델 선택 감각
README는 Mac의 RAM 크기에 따라 모델 alias를 고르는 식으로 안내한다.
예를 들어 16GB Mac은 qwen3.5-4b, 24GB는 qwen3.5-9b, 32GB 이상은 qwen3.5-27b나 nemotron-30b, 48~64GB 이상은 qwen3.5-35b, 96GB 이상은 qwen3.5-122b 같은 식이다.
# 16GB급 Mac에서 가벼운 시작점
rapid-mlx serve qwen3.5-4b --port 8000
# 24GB급 Mac에서 균형형
rapid-mlx serve qwen3.5-9b --port 8000
# coding agent backend 후보
rapid-mlx serve qwen3-coder --prefill-step-size 8192 --port 8000
# vision 모델은 별도 extras가 필요하다
pip install 'rapid-mlx[vision]'
rapid-mlx serve qwen3-vl-4b --mllm --port 8000
모델 선택에서 중요한 것은 “큰 모델이 무조건 좋다”보다 RAM, KV cache, prompt 길이, tool calling 안정성의 균형이다.
Mac의 메모리 압박이 빨갛게 뜨거나 swap이 심해지면 더 작은 4bit 모델로 내려가는 편이 낫다.
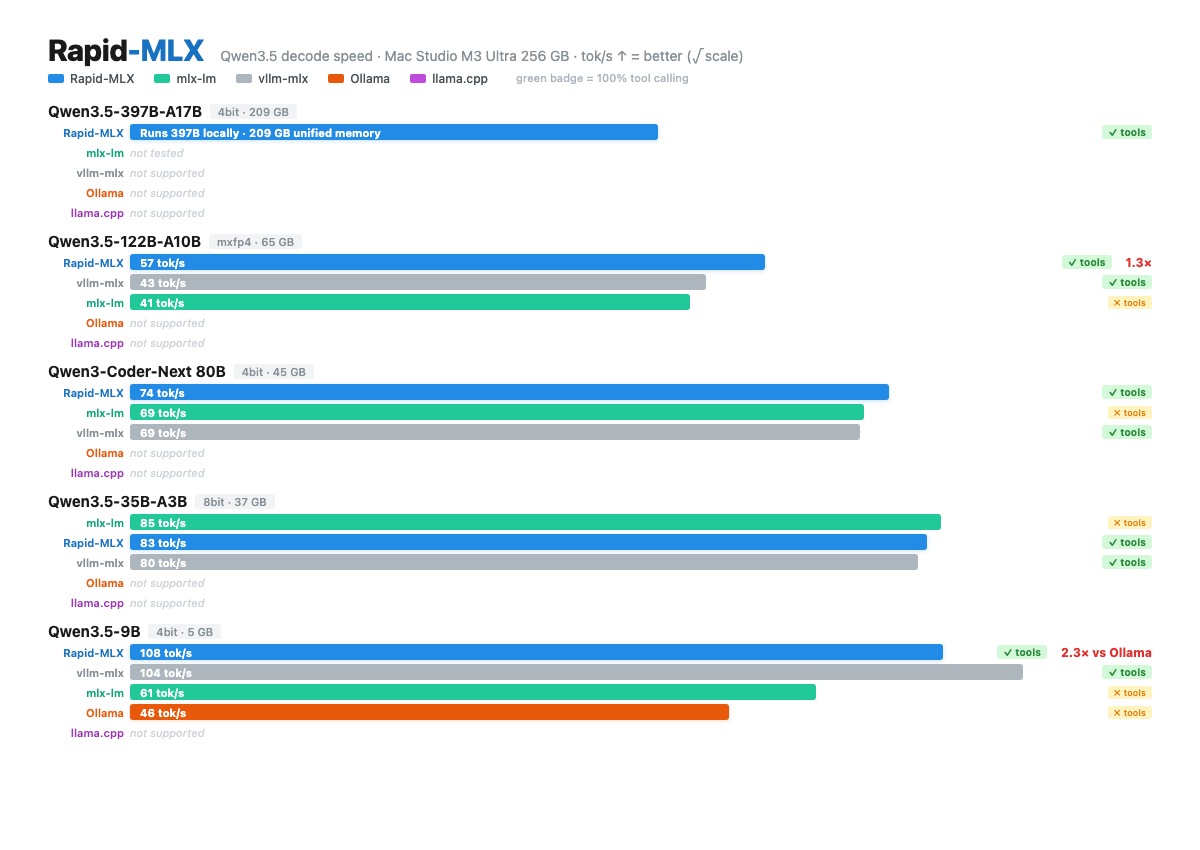
왜 유용한가
Rapid-MLX의 실용 포인트는 네 가지다.
첫째, OpenAI API 호환 서버라 기존 도구 연결이 쉽다.
Cursor의 OpenAI Base URL, Aider의 --openai-api-base, PydanticAI/LangChain의 OpenAI provider, Open WebUI/LibreChat의 custom endpoint에 http://localhost:8000/v1을 넣는 방식이다.
Claude Code 계열 도구에는 OpenAI-compatible endpoint뿐 아니라 Anthropic-compatible /v1/messages endpoint도 제공한다.
둘째, tool calling과 reasoning separation을 별도 기능으로 다룬다. mistral, qwen, llama, hermes, deepseek, kimi, granite, nemotron, xlam, functionary, glm47 등 모델 family별 parser를 제공하고, README 최신 버전은 모델 이름 기반 자동 감지와 broken tool-call recovery를 강조한다.
Qwen3나 DeepSeek-R1처럼 <think> 계열 reasoning을 내보내는 모델은 reasoning과 최종 answer를 분리해 API response에 담을 수 있다.
셋째, Apple Silicon의 MLX 생태계를 정면으로 탄다. macOS/arm64와 MLX/MLX-LM을 기본 전제로 삼기 때문에, CUDA 서버나 x86 Linux inference stack과 다른 최적화 지점을 가진다.
README의 benchmark는 Mac Studio M3 Ultra 256GB 같은 고사양 Apple Silicon에서 Qwen3.5, Qwen3-Coder, GPT-OSS, Nemotron, DeepSeek, Kimi 계열 모델을 비교한다.
수치는 하드웨어·모델·버전에 민감하지만, “Mac에서 로컬 AI API 서버를 빠르게 돌린다”는 제품 thesis는 분명하다.
넷째, 기본 설치와 extras의 경계를 잘 나눈다.
텍스트 모델만 쓰면 pip install rapid-mlx로 시작하고, 필요할 때만 다음 extras를 더한다.
rapid-mlx[vision]: Qwen-VL, Gemma vision, video understanding 계열rapid-mlx[audio]: STT/TTS용 mlx-audio 계열rapid-mlx[embeddings]:/v1/embeddingsendpointrapid-mlx[chat]: Gradio chat UIrapid-mlx[guided]: schema-constrained JSON generationrapid-mlx[all]: 여러 extras를 한 번에 설치
coding agent backend로 붙일 때
Rapid-MLX는 “Claude Code 같은 TUI 자체”가 아니라 backend다.
README도 OpenCode나 Codex 같은 open-source agent CLI와 조합하라고 설명한다.
예를 들어 OpenCode는 project root의 config에서 OpenAI provider endpoint를 http://localhost:8000/v1로 잡는 방식이고, Aider는 다음처럼 붙일 수 있다.
aider --openai-api-base http://localhost:8000/v1 --openai-api-key not-needed
Cursor는 Settings → Models → Add Model에서 OpenAI API Base를 지정한다.
OpenAI API Base: http://localhost:8000/v1
API Key: not-needed
Model name: default
Claude Code/OpenClaude류 도구는 환경변수로 OpenAI-compatible endpoint를 지정하는 패턴을 쓴다.
OPENAI_BASE_URL=http://localhost:8000/v1 claude
여기서 체감 품질은 서버보다 선택한 모델의 tool calling 안정성에 크게 좌우된다.
README 기준 Qwen3.5 계열은 hermes parser와 qwen3 reasoning parser가 추천 경로로 잡혀 있고, Devstral/Mistral, GLM, Kimi, DeepSeek, Nemotron 등은 각각 다른 parser format을 가진다.
잘 안 되면 무작정 큰 모델로 올리기보다 parser/alias/템플릿 조합을 먼저 확인하는 편이 좋다.
운영과 보안 caveat
Rapid-MLX는 로컬 inference 서버지만, 서버라는 사실은 변하지 않는다.
특히 CLI reference 기준 rapid-mlx serve의 기본 host는 0.0.0.0, 기본 port는 8000, 기본 API key는 없음, rate limit은 비활성화다.
개인 Mac에서만 쓰더라도 네트워크 환경에 따라 LAN에서 접근될 수 있으므로, 로컬 전용으로 쓰려면 명시적으로 host를 좁히는 편이 안전하다.
rapid-mlx serve qwen3.5-4b \
--host 127.0.0.1 \
--port 8000
외부에서 접근시키거나 Docker/터널/공유 네트워크에 올릴 때는 최소한 API key와 rate limit을 설정한다.
rapid-mlx serve qwen3.5-4b \
--api-key your-secret-key \
--rate-limit 60 \
--timeout 120
MCP를 붙이는 경우도 주의가 필요하다. --mcp-config mcp.json은 모델이 MCP tool을 호출할 수 있게 만드는 기능이므로, filesystem/shell/browser류 MCP 서버를 연결하면 로컬 파일·명령 실행 표면이 생긴다. coding agent backend로 쓸 때는 편리하지만, 신뢰하지 않는 prompt나 공개 endpoint와 섞는 것은 위험하다.
Cloud routing도 기본값은 꺼져 있지만, --cloud-model openai/gpt-5 --cloud-threshold 20000처럼 설정하면 큰 요청을 외부 LLM으로 넘길 수 있다.
로컬-only 워크플로를 기대한다면 이 옵션을 켰는지 확인해야 한다.
Telemetry는 README 기준 명시적 opt-in 전에는 꺼져 있고, 현재 Phase 1 release에는 consent/CLI/schema만 있으며 network transport code는 없다고 설명한다.
그래도 CI나 재현 스크립트에서는 다음처럼 강제로 꺼두면 의도가 명확하다.
RAPID_MLX_TELEMETRY=0 rapid-mlx serve qwen3.5-9b
rapid-mlx --no-telemetry serve qwen3.5-9b
rapid-mlx telemetry status
내 판단
Rapid-MLX는 “Mac에서 로컬 AI를 한 번 체험해보는 장난감”보다 Apple Silicon을 진지한 로컬 LLM backend로 쓰려는 사람에게 더 잘 맞는다.
이미 Cursor, Aider, PydanticAI, LangChain, Open WebUI 같은 도구를 쓰고 있고, API 비용·지연·프라이버시 때문에 일부 작업을 로컬로 돌리고 싶다면 바로 시험해볼 가치가 있다.
반대로 NVIDIA GPU 서버, Linux 중심 배포, Ollama의 단순 모델 관리 UX, 팀 단위 multi-tenant serving을 기대한다면 범위가 다르다.
Rapid-MLX의 강점은 Apple Silicon + MLX + OpenAI-compatible API + agent/tool-calling 호환성의 조합이다.
내 기준으로는 개인 Mac을 coding agent용 로컬 inference 서버로 쓰고 싶은 개발자에게 추천할 만한 빠르게 움직이는 beta 프로젝트다.