MoneyPrinterTurbo는 “유튜브 쇼츠/릴스/TikTok용 짧은 영상을 매번 손으로 조립하기 귀찮다”는 문제를 겨냥한 오픈소스 도구다.
주제나 키워드를 넣으면 LLM이 대본과 검색어를 만들고, Pexels/Pixabay 또는 로컬 소재를 가져오며, TTS 음성·자막·배경음악을 붙여 최종 MP4를 합성한다.
핵심은 단일 모델 데모가 아니라 숏폼 생성 파이프라인이라는 점이다.
WebUI로 한 번씩 눌러 볼 수도 있고, FastAPI 엔드포인트를 통해 영상 생성·자막 생성·오디오 생성·작업 상태 조회를 자동화할 수도 있다.
콘텐츠 공장이라는 이름은 과격하지만, 실제로는 반복적인 초안 제작과 소재 조합을 줄여 주는 로컬/셀프호스트형 작업대에 가깝다.
MoneyPrinterTurbo 개요
저장소 설명과 README 기준으로 MoneyPrinterTurbo는 Python 기반 애플리케이션이다.
WebUI는 Streamlit, API는 FastAPI/uvicorn, 영상 합성은 MoviePy 계열 의존성을 사용하고, 의존성 관리는 pyproject.toml과 uv.lock으로 정리되어 있다.
조사 시점 기준 프로젝트 버전과 최신 GitHub Release는 v1.2.8이며, GitHub API 라이선스와 루트 LICENSE는 MIT로 일치한다.
지원 흐름은 꽤 넓다.
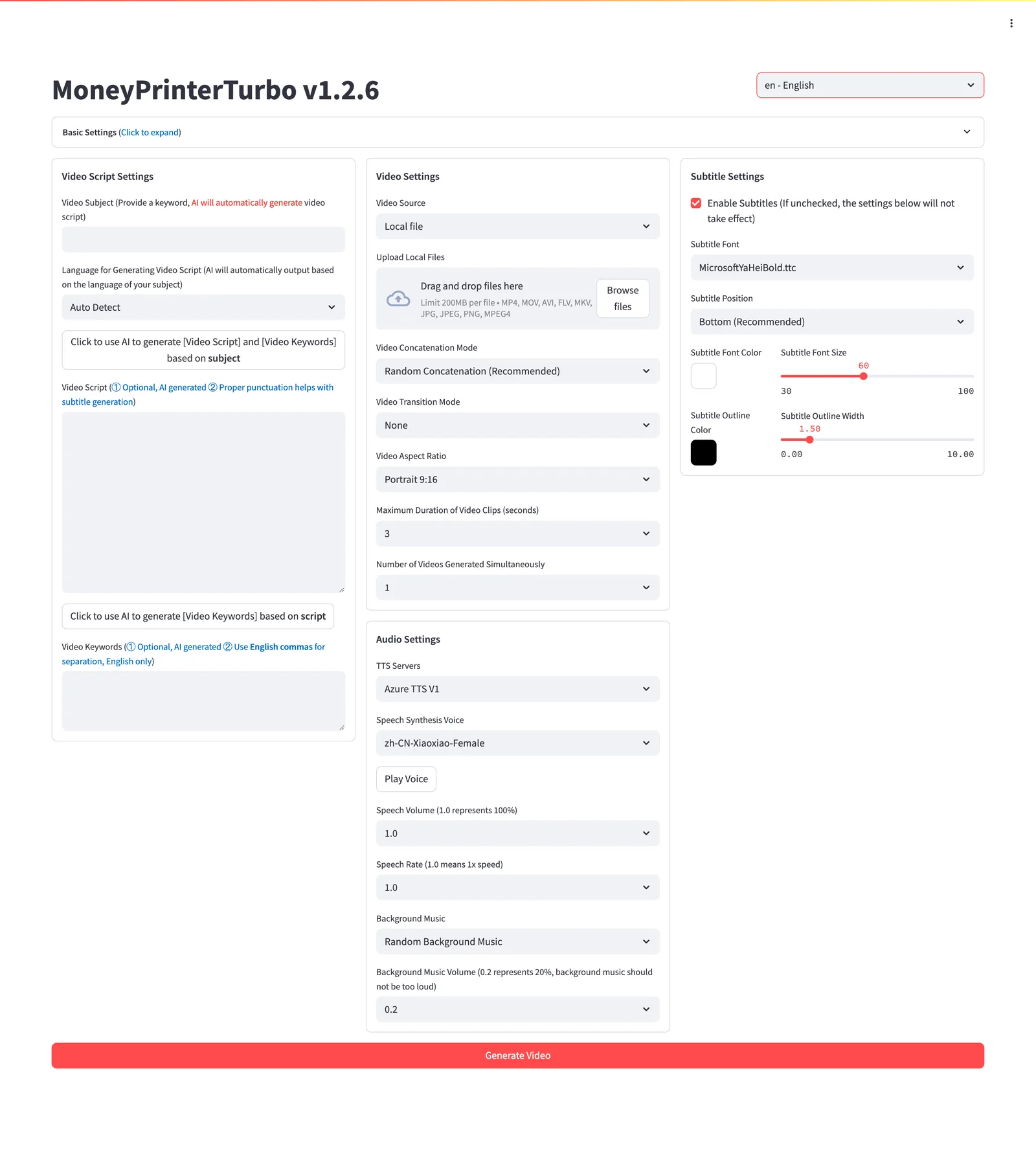
- 주제/키워드 기반 영상 대본 자동 생성
- 직접 작성한 대본 또는 로컬 영상·이미지 소재 사용
- 세로 9:16
1080x1920, 가로 16:91920x1080영상 생성 - 여러 영상을 배치로 만들고 결과를 고르는 흐름
- TTS 음성 미리듣기와 자막 폰트·위치·색상·외곽선 설정
- 랜덤 또는 지정 BGM 사용
- WebUI와 OpenAPI 문서가 있는 API 서버 병행 제공
LLM 공급자는 OpenAI, Azure, Gemini, DeepSeek, Qwen, Moonshot, MiniMax, ERNIE, ModelScope, Ollama, one-api, Pollinations, LiteLLM 등으로 넓게 열려 있다.
특히 v1.2.8 릴리스는 LiteLLM 경로를 통해 100개 이상 호환 모델 게이트웨이를 다룰 수 있다고 설명하고, Grok/xAI도 OpenAI 호환 경로로 추가했다.
어디에 쓰기 좋은가
첫 번째 용도는 숏폼 초안 제작이다.
완성된 브랜드 영상보다는 “이 주제로 3~5개 버전을 빠르게 뽑고, 대본·소재·자막 톤을 보면서 고른다”는 흐름에 잘 맞는다.
영상 소재를 전부 직접 만들기보다 스톡 영상 API와 로컬 파일 업로드를 섞어 초안을 구성하는 방식이다.
두 번째는 내부 자동화 실험이다.
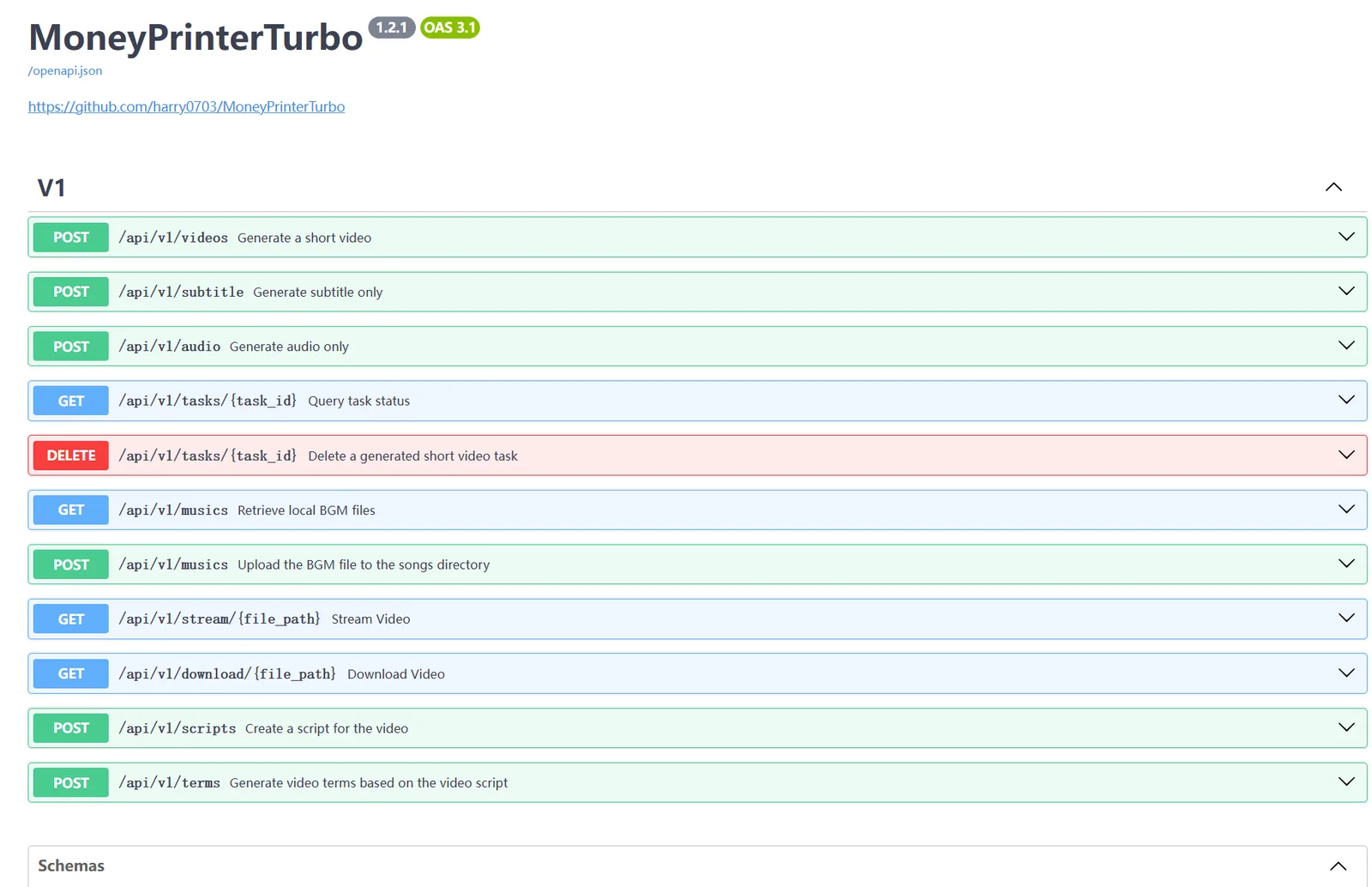
API 화면에는 POST /api/v1/videos, POST /api/v1/subtitle, POST /api/v1/audio, GET /api/v1/tasks/{task_id}, GET /api/v1/download/{file_path} 같은 엔드포인트가 보인다.
콘텐츠 캘린더, 사내 캠페인, 교육용 짧은 클립처럼 “일정한 형식의 영상 초안을 반복 생성”하는 작업이라면 다른 스크립트나 에이전트에서 호출하기 쉽다.
세 번째는 로컬 소재 기반 내레이션 영상이다. v1.2.8 릴리스는 WebUI에서 사용자 지정 오디오를 업로드하고 로컬 내레이션으로 영상을 생성하는 기능을 강조한다.
이미 녹음한 음성이나 사내 교육 음성 자료가 있고, 여기에 자막과 영상 소재를 붙이고 싶은 경우에 유용하다.
설치와 첫 사용법
README의 기본 흐름은 먼저 저장소를 클론하고 config.example.toml을 config.toml로 복사한 뒤, pexels_api_keys, pixabay_api_keys, llm_provider, 선택한 공급자의 API 키를 채우는 방식이다.
git clone https://github.com/harry0703/MoneyPrinterTurbo.git
cd MoneyPrinterTurbo
cp config.example.toml config.toml
가장 격리된 실행 경로는 Docker다.
docker compose up
README는 WebUI를 http://0.0.0.0:8501, API 문서를 http://0.0.0.0:8080/docs 또는 /redoc에서 확인하라고 안내한다.
실제 로컬 브라우저에서는 보통 http://127.0.0.1:8501과 http://127.0.0.1:8080/docs로 접속하면 된다.
macOS/Linux의 수동 실행은 uv와 Python 3.11을 기본 경로로 둔다.
uv python install 3.11
uv sync --frozen
uv run streamlit run ./webui/Main.py --browser.gatherUsageStats=False
API 서버만 띄우려면 다음 명령을 쓴다.
uv run python main.py
Windows는 README 기준 원클릭 패키지가 아직 v1.2.6 번들 빌드이며, 다운로드 후 update.bat을 먼저 실행해 최신 코드로 갱신한 뒤 start.bat으로 실행하는 흐름을 권한다.
즉 최신 릴리스 번호와 Windows 번들 버전이 다를 수 있으므로, 처음 설치할 때는 README와 Release를 같이 보는 편이 안전하다.
GPU와 자막 생성 경계
GPU가 필요한 “영상 생성 모델” 프로젝트처럼 보일 수 있지만, 문서상 GPU 가속의 주 대상은 faster-whisper 자막 생성이다.
기본 CPU 배포는 그대로 쓸 수 있고, NVIDIA GPU가 있으면 docker-compose.gpu.yml을 겹쳐서 CUDA 기반 컨테이너로 실행한다.
docker compose -f docker-compose.yml -f docker-compose.gpu.yml up -d
GPU 문서는 whisper-large-v3가 GPU float16에서 약 1.5GB VRAM을 쓰며, 4GB는 12개, 8GB는 34개 정도의 동시 작업을 권장한다.
다만 대본 생성, TTS, 스톡 소재 검색, 영상 합성 자체는 여전히 외부 API·CPU·I/O·ffmpeg/MoviePy 처리량에 영향을 받는다.
“GPU만 붙이면 모든 단계가 빨라진다”가 아니라, Whisper 자막 병목을 줄이는 옵션으로 보는 것이 맞다.
주의할 점
가장 먼저 봐야 할 것은 API 키와 데이터 경계다. config.example.toml에는 Pexels, Pixabay, OpenAI, Azure, Gemini, Grok/xAI, Qwen, MiniMax, DeepSeek, ModelScope, LiteLLM 등 여러 키·base URL 설정이 들어간다.
영상을 만들기 위해 대본, 키워드, 일부 소재 맥락, TTS 텍스트가 외부 모델/서비스로 나갈 수 있으므로, 사내 자료나 고객 데이터로 테스트할 때는 공급자별 데이터 정책을 먼저 확인해야 한다.
두 번째는 서버 노출이다.
API 서버는 기본 설정에서 listen_host = "0.0.0.0", listen_port = 8080을 사용하고, FastAPI 라우터의 인증 의존성은 코드상 주석 처리되어 있다.
Docker Compose도 8501:8501, 8080:8080 포트를 그대로 매핑한다.
개인 PC에서만 쓰는 실험이라도 방화벽·Docker Desktop 네트워크·클라우드 VM 보안 그룹에 따라 외부에서 접근될 수 있으니, 팀이나 서버에 올릴 때는 reverse proxy 인증, loopback 바인딩, CORS 제한, 비공개 네트워크 배치를 먼저 정해야 한다.
세 번째는 저작권과 플랫폼 정책이다.
README는 스톡 영상 소재를 “고화질·royalty-free”라고 설명하지만, Pexels/Pixabay 사용 조건과 생성한 영상의 최종 사용 범위는 별도로 확인해야 한다.
또한 기본 BGM 일부는 YouTube 영상에서 온 것이라 저작권 문제가 있으면 삭제하라는 README 주석이 있다.
자동 생성 영상이 광고·상업·대량 업로드로 이어질수록 소재 라이선스와 플랫폼 스팸/중복 콘텐츠 정책을 더 보수적으로 봐야 한다.
네 번째는 선택적 공급자 리스크다.
최신 설정 파일은 g4f를 기본 비활성화하고, reverse-engineered third-party endpoint에 의존하므로 보안·신뢰성·법적 리스크를 이해한 뒤에만 켜라고 적는다.
실사용 경로라면 공식 API, OpenAI 호환 공급자, LiteLLM, Ollama, 로컬 추론 쪽을 우선 검토하는 편이 낫다.
내 판단
MoneyPrinterTurbo는 완성형 영상 스튜디오라기보다 숏폼 제작 실험대로 보는 것이 좋다.
주제 입력부터 대본, 소재, 음성, 자막, BGM, 합성까지 한 번에 묶어 놓았고, WebUI와 API가 같이 있어 개인 실험과 자동화 양쪽 모두 접근성이 좋다. v1.2.7 이후 릴리스에서 경로 검증, TLS 기본값, 큐 제한, Azure/Gemini/Edge TTS 호환성 같은 운영 안정화가 계속 들어간 점도 긍정적이다.
반대로 브랜드 채널이나 고객용 영상 파이프라인에 바로 넣기에는 확인할 것이 많다.
모델 공급자 비용, API 키 보관, 스톡 소재·BGM 라이선스, 인증 없는 API 노출, Windows 번들 버전 드리프트, Whisper 모델 다운로드와 GPU 옵션까지 모두 운영 변수다.
나는 먼저 Docker나 Colab으로 샘플 영상을 몇 개 만들어 보고, 결과 품질보다 내 워크플로에 맞는 반복 초안 생성기인지를 기준으로 평가하는 쪽을 추천한다.