humanlayer/12-factor-agents는 “AI 에이전트를 어떻게 만들 것인가”를 프레임워크 선택 문제가 아니라 제품용 LLM 소프트웨어의 운영 원칙으로 다시 정리한 공개 가이드다.
이름은 Heroku의 12-Factor App에서 빌려왔지만, 내용은 환경 변수나 stateless process보다 LLM 호출, context window, tool call, 상태 저장, pause/resume, human-in-the-loop 같은 agent engineering 문제에 집중한다.
README의 출발점은 꽤 현실적이다.
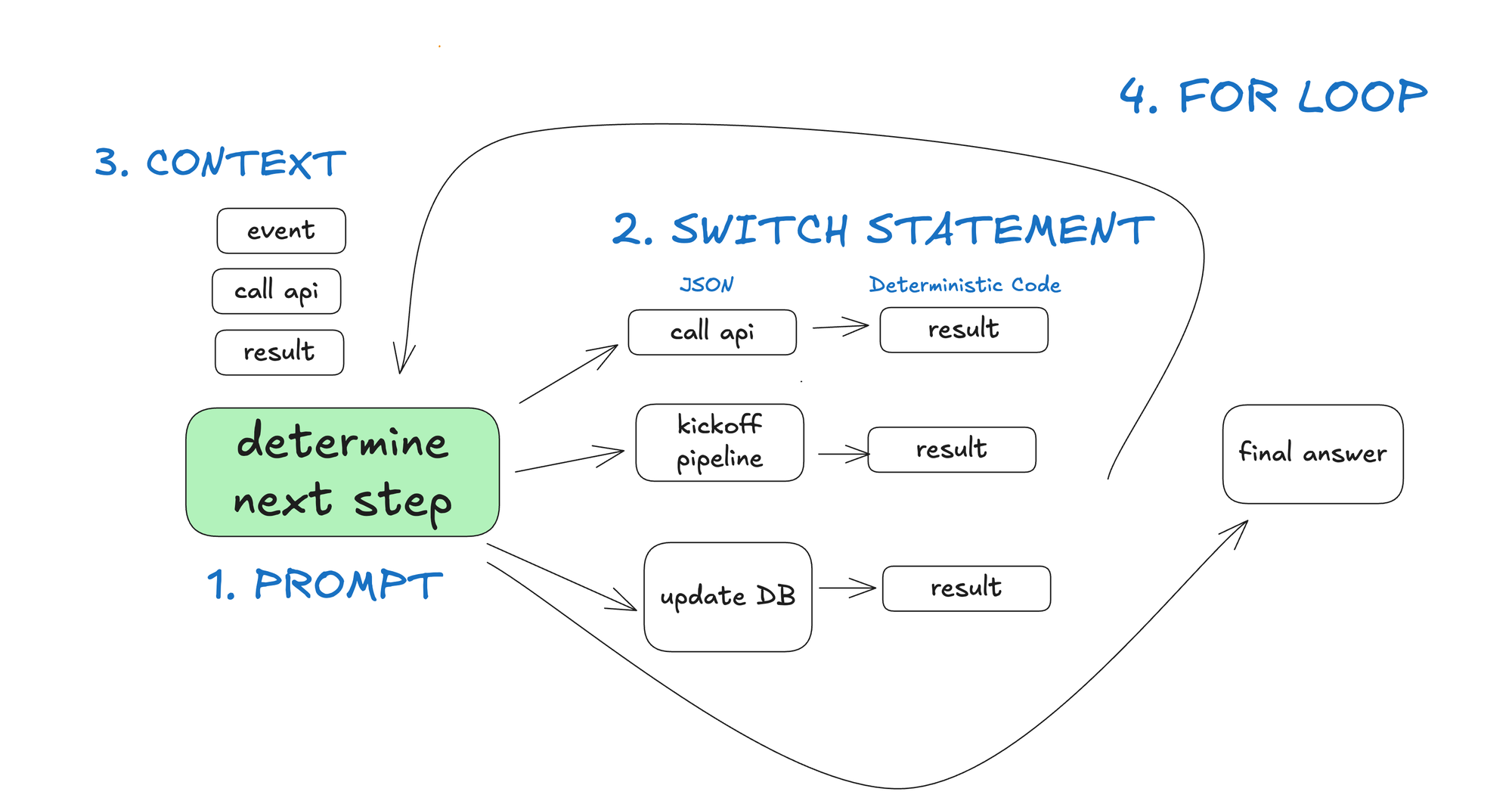
좋은 agent는 “프롬프트 하나와 도구 묶음을 주고 목표를 달성할 때까지 loop”하는 마법 같은 구조가 아니라, 대부분은 deterministic software이고 LLM은 적절한 지점에 들어가는 의사결정 함수라는 관찰이다.
그래서 이 저장소는 “어떤 agent framework가 최고인가?”
보다 “프레임워크를 쓰더라도 우리가 직접 소유해야 할 경계는 무엇인가?”
에 답하려고 한다.
12-Factor Agents 개요
README가 제시하는 12개 항목은 다음 흐름으로 읽으면 이해가 쉽다.
- 자연어를 structured tool call로 바꾸되, tool call을 특별한 마법 API가 아니라 typed JSON/structured output으로 본다.
- prompt와 context window를 framework 내부에 숨기지 말고, 애플리케이션이 직접 구성하고 버전 관리한다.
- execution state와 business state를 분리된 추적 시스템으로 과하게 쪼개기보다, 재시작·감사·resume이 가능한 단일 thread/event 모델로 생각한다.
- agent를 launch, pause, resume할 수 있는 단순 API를 만들고, 고위험 tool invocation 전에는 loop를 끊어 사람에게 물어본다.
- 작은 agent와 명시적인 control flow를 조합하고, 마지막에는 agent를 “이전 event들을 받아 다음 event를 내는 reducer”에 가깝게 본다.
이 관점이 마음에 드는 이유는 “agent답게 보이는 데모”와 “고객에게 열어도 되는 기능” 사이의 간극을 정확히 찌르기 때문이다.
실제 제품에서는 승인, 감사 로그, 재시도, 실패 요약, context compaction, rate limit, 장기 작업 대기, 외부 채널 입력 같은 지루한 문제가 대부분의 품질을 결정한다.
12-Factor Agents는 이 지루한 부분을 agent loop 바깥의 일반 소프트웨어 설계로 끌어낸다.
특히 먼저 읽을 만한 Factor
처음부터 12개를 모두 외우려 하기보다 아래 네 묶음을 먼저 보는 편이 좋다.
-
Factor 2: Own your prompts
프롬프트를 framework default에 맡기지 말고 코드처럼 소유하라는 주장이다. agent 품질을 디버깅하려면 어떤 prompt가 어떤 structured output을 유도했는지 재현 가능해야 한다. -
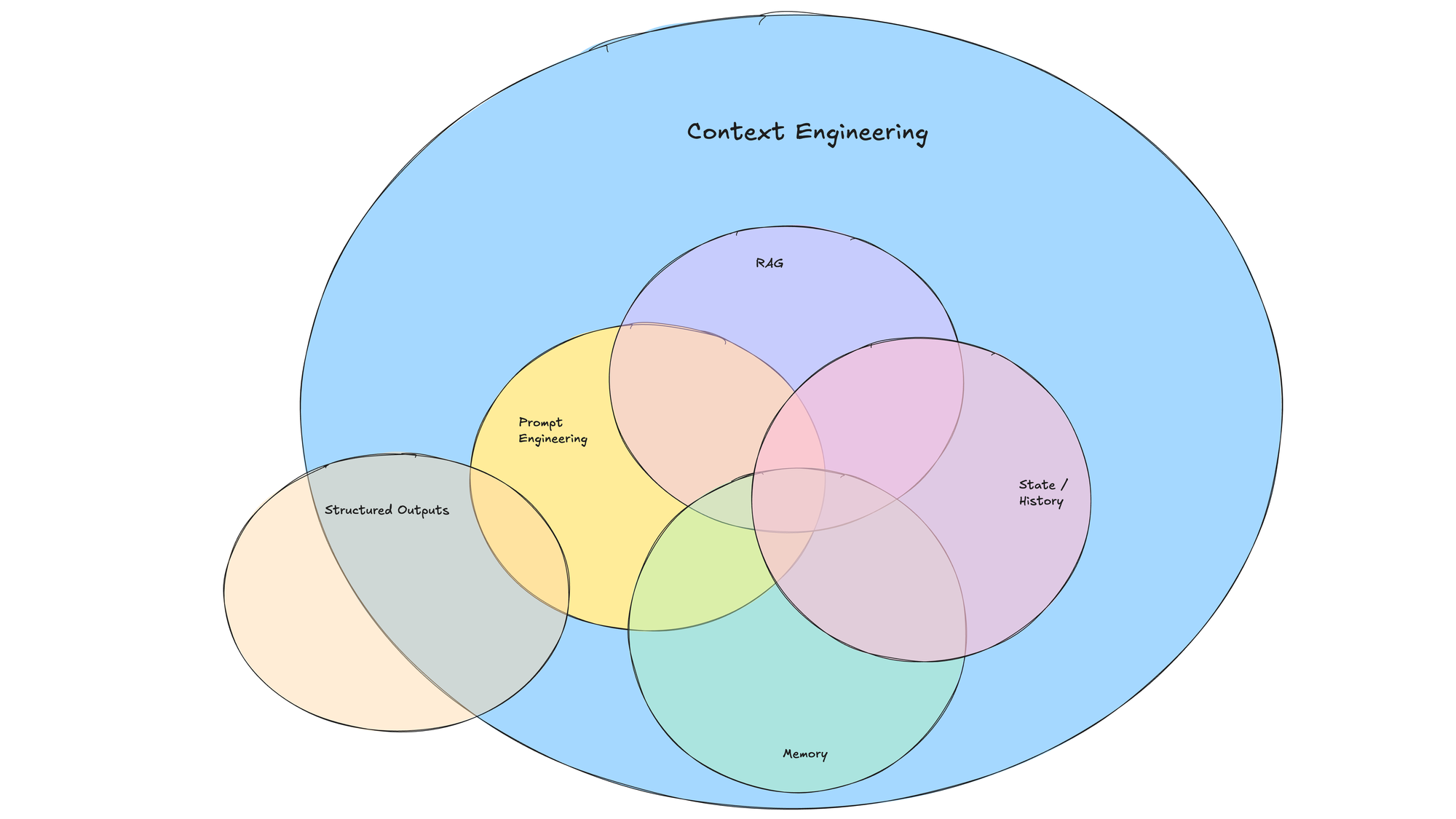
Factor 3: Own your context window
이 저장소에서 가장 실용적인 파트다. LLM 입력은 “지금까지 무슨 일이 있었고, 다음 단계는 무엇인가?”라는 질문에 가깝다. 그래서 standard chat message format에만 묶이지 말고, task에 맞는 XML/YAML/custom event format으로 context를 더 token-efficient하게 구성할 수 있어야 한다.
-
Factor 5~8: state, pause/resume, human tool call, control flow
실제 운영에서는 model이 “deploy_backend” 같은 고위험 다음 단계를 고른 순간 바로 실행하면 안 된다. Factor 7과 8은request_human_input,request_clarification,deploy_backend같은 structured intent에 따라 loop를 계속 돌릴지, 저장하고 끊을지, webhook 응답을 기다릴지 직접 결정하라고 말한다. -
Factor 10~12: small focused agents와 reducer 관점
하나의 거대한 만능 agent보다 작은 agent들을 deterministic workflow 안에 배치하는 편이 디버깅과 관찰에 유리하다. “agent는 event history를 접어서 다음 event를 만드는 reducer”라는 표현은 구현 세부보다 설계 감각을 잡는 데 도움이 된다.
설치와 첫 사용법
이 저장소는 일반적인 npm/PyPI 패키지라기보다 Markdown guide와 workshop 자료에 가깝다.
따라서 첫 사용은 설치보다 읽기와 내부 설계 체크리스트화에 가깝다.
git clone https://github.com/humanlayer/12-factor-agents.git
cd 12-factor-agents
추천 읽기 순서는 다음과 같다.
README.md
content/factor-03-own-your-context-window.md
content/factor-05-unify-execution-state.md
content/factor-06-launch-pause-resume.md
content/factor-07-contact-humans-with-tools.md
content/factor-08-own-your-control-flow.md
content/factor-10-small-focused-agents.md
워크숍 예제까지 따라가려면 packages/create-12-factor-agent/template/README.md와 workshops/ 아래 자료를 보면 된다.
확인한 template README는 Node.js/npm 기반 TypeScript 흐름을 기본으로 설명하고, BAML을 structured output/prompt layer로 사용한다.
모델 provider 쪽은 Baseten의 Qwen3 예시가 기본으로 나오지만, BAML client 설정을 바꾸면 OpenAI, Gemini, Anthropic 같은 provider로 바꿔보는 흐름도 설명한다.
다만 “바로 설치해서 쓰는 CLI”로 기대하면 안 된다.
README는 npx/uvx create-12-factor-agent 기여 discussion을 언급하지만, 작성 시점에 GitHub Releases와 tags는 비어 있고 npm registry에서도 create-12-factor-agent 패키지는 확인되지 않았다.
즉 지금은 패키지화된 starter보다 공개 원칙 문서와 워크숍 템플릿으로 보는 편이 맞다.
어디에 적용하면 좋은가
나는 이 저장소를 새 framework를 고르기 전의 질문지로 쓰는 편을 추천한다.
예를 들어 agent 기능을 설계할 때 아래 질문에 답해보면 좋다.
- prompt template과 few-shot 예시는 어디에 저장되고, 누가 리뷰하는가?
- LLM에 넘기는 context는 단순 chat transcript인가, 제품 domain event로 재구성한 format인가?
- tool call 결과와 사용자 승인, 외부 webhook 응답은 같은 thread/event history에 남는가?
- model이 고위험 작업을 선택한 순간 loop를 끊고 approval을 받을 수 있는가?
- 장기 실행 작업, 실패한 API 호출, 요약된 error context, retry policy는 framework 안에 숨었는가, 애플리케이션 코드가 소유하는가?
- agent가 너무 많은 일을 한 번에 맡고 있지는 않은가?
특히 SaaS 제품에 LLM 기능을 붙이는 팀이라면 “기존 제품의 workflow 안에 작은 agentic step을 넣는다”는 README의 방향이 유용하다.
반대로 연구용 데모나 일회성 자동화처럼 failure cost가 낮은 영역에서는 이 체크리스트가 다소 무겁게 느껴질 수 있다.
주의할 점
이 저장소는 유용하지만, adoption할 때 몇 가지 경계를 분명히 해야 한다.
- 프레임워크가 아니다. LangGraph, CrewAI, OpenAI Agents SDK 같은 runtime을 대체하는 패키지가 아니라 설계 원칙과 예제 모음이다. 코드 scaffold를 기대하기보다 architecture review 자료로 쓰는 편이 맞다.
- 릴리스/태그가 없다. GitHub Releases와 tags가 비어 있으므로 장기 문서 인용이나 사내 표준화에는 commit hash를 pin하는 편이 안전하다.
- 라이선스가 이중 구조다. GitHub API는 license를
NOASSERTION으로 보고했지만, checked-inLICENSE는 Apache 2.0이고 README는 content/images를 CC BY-SA 4.0, code를 Apache 2.0으로 명시한다. 문서와 이미지를 재배포할 때는 CC BY-SA 조건을 따로 확인해야 한다. - 실습에는 provider key가 필요할 수 있다. workshop template은 BAML과 model provider 설정을 다룬다. Baseten/OpenAI/Gemini/Anthropic 등 실제 provider key를 넣는 순간 prompt, test input, tool output이 외부 provider로 나갈 수 있다.
- Windows는 개념적으로 가능하지만 shell 경험을 확인해야 한다. 문서 자체와 Node/npm 기반 예제는 Windows에서도 읽고 시도할 수 있지만, README 예시는 Homebrew, shell, git 중심이다. 팀 표준 실습 환경은 macOS/Linux/WSL 기준으로 먼저 맞추는 편이 덜 헷갈린다.
내 판단
12-factor-agents는 “새로운 agent framework 추천” 글이 아니라 agent framework에 너무 빨리 기대지 않기 위한 방어적 설계 노트로 가치가 크다.
특히 context engineering, human approval, pause/resume, explicit control flow를 제품 코드가 직접 소유해야 한다는 메시지는 지금의 LLM 앱 개발에서 자주 놓치는 부분이다.
이미 agent framework를 쓰고 있다면 이 저장소를 버리는 이유로 쓰기보다, framework가 숨긴 prompt/context/state/control-flow 경계를 다시 꺼내는 감사 체크리스트로 쓰면 좋다.
반대로 아직 agent를 만들기 전이라면 Factor 3, 5, 6, 7, 8만 먼저 읽어도 “LLM 호출 한 번”과 “운영 가능한 agent 기능” 사이에 어떤 구조가 필요한지 감이 잡힌다.