OCR은 글자를 읽어주지만, 업무에서 필요한 것은 "이 값이 어느 행·어느 열에 속하는가"입니다.
InVision OCR은 이 간극 — OCR 이후의 표 구조 복원 — 을 로직 기반 후보 생성·비교·선택 프레임으로 풀고, 그 품질을 TEDS 기반 벤치마크로 정량 증명한 프로젝트입니다.
이 글은 세 가지 기술 문제를 다룹니다. ① 격자선이 없거나 끊긴 표를 어떻게 구조로 복원하는가, ② "그럴듯해 보이는 결과"가 아니라 측정 가능한 개선을 어떻게 만드는가, ③ 모델과 로직을 고객사 서버에 두고도 어떻게 보호하는가.
문제: OCR 결과와 표 구조 사이의 간극
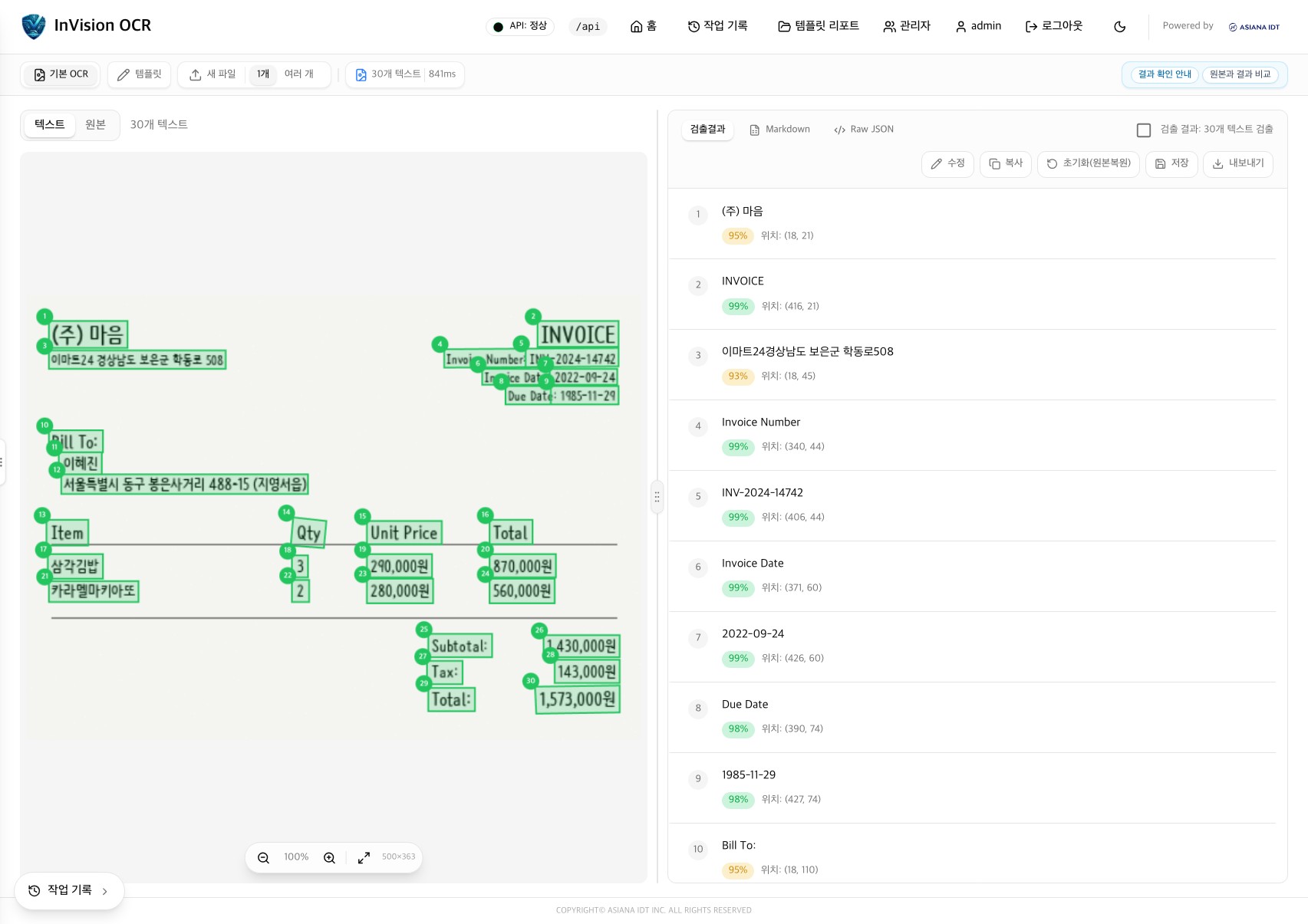
OCR 엔진의 출력은 텍스트와 bbox 좌표 목록입니다.
그러나 실무 문서의 표는 이 정보만으로 복원되지 않습니다.
병합 셀(colspan/rowspan)은 좌표 정렬을 깨뜨리고, 다단 헤더는 어느 행까지가 헤더인지 모호하게 만들며, 스캔 품질에 따라 격자선이 아예 검출되지 않는 표도 흔합니다.
셀 하나의 텍스트가 표 경계선을 관통해 두 조각으로 분리되어 인식되는 경우도 있습니다.
좌표 군집화(kmeans) 같은 단일 전략은 이런 변형 앞에서 쉽게 무너집니다 — 실제로 자체 벤치마크에서 kmeans baseline은 TEDS 0.3304, 고정 임계값 기반 baseline은 0.7540에 그쳤습니다.
결론은 단일 알고리즘이 아니라 여러 신호에서 후보를 만들고, 비교하고, 근거를 남기며 선택하는 구조가 필요하다는 것이었습니다.

딥다이브 ① 표 구조 복원 — 후보 생성·비교·선택 프레임
표 영역 하나에 대해 파이프라인은 성격이 다른 구조 후보를 병렬로 만듭니다.
검출된 가로·세로 선분으로 격자(lattice)를 구성합니다.
선이 온전한 표에서 가장 정확하지만, 선이 끊기면 행·열이 통째로 붕괴합니다.
OCR bbox의 행 간격·열 정렬에서 row/column grouping을 추정합니다.
선이 없어도 동작하지만 병합 셀과 다단 헤더에 취약합니다.
다단 헤더의 colspan 추론과 좌측 행 헤더 계층 보존을 별도로 다룹니다.
헤더가 무너지면 표 전체의 의미가 무너지기 때문입니다.
누락된 격자선의 복구, 경계선 관통으로 분리된 텍스트의 재결합, 행 안정성 검증 등 후보를 교정하는 규칙 계층입니다.
핵심은 이 후보들을 비교해서 선택한다는 점입니다.
어떤 표는 선분 기반이, 어떤 표는 bbox 기반이 옳습니다.
파이프라인은 각 후보의 구조 안정성을 평가해 가장 설득력 있는 구조를 고르고, 어떤 후보가 왜 선택됐는지 진단 정보를 남깁니다.
이 선택 근거는 연구 화면에서 케이스 단위로 추적할 수 있어, 실패 케이스를 회귀 세트로 축적하는 기반이 됩니다.
가장 까다로웠던 케이스는 격자선이 부분적으로 누락된 표였습니다.
선분 기반 후보는 누락 구간에서 행을 병합해버리고, bbox 기반 후보는 전체 정렬을 놓칩니다.
해결은 하이브리드였습니다 — 텍스트 정렬 패턴에서 “있어야 할 선”을 역으로 추정해 격자를 복원하고, 선분·bbox 양쪽 후보의 강점 구간을 결합하는 방식입니다.
이 보정 규칙들의 구체 조건과 판정 로직은 특허 출원 중인 부분이라 여기서는 개념 수준까지만 적습니다.

딥다이브 ② 정량 평가 — 감이 아니라 지표로 개선하기
휴리스틱 기반 시스템의 고질병은 “이 케이스를 고치면 저 케이스가 깨지는” 회귀입니다.
이를 통제하기 위해 개선 작업 초기부터 평가 체계를 먼저 세웠습니다.
HTML table GT를 기준으로 지표를 계층화했습니다.
TEDS/TEDS-S(트리 편집 거리 기반 구조 유사도)는 표 전체 구조를, Cell F1은 셀 매칭을, CER은 셀 내 텍스트를, Row/Col 일치는 행·열 수를 봅니다.
이 조합은 “구조는 맞는데 텍스트가 깨진 경우”와 “텍스트는 맞는데 셀 배치가 틀린 경우”를 분리해서 진단하게 해줍니다.
| 실험 / 지표 | 확인한 값 | 해석 |
|---|---|---|
| hf_korean_table 100샘플 Proposed | TEDS 0.9174, Cell F1 0.9934, Row 1.00, Col 0.96 | 규칙 기반 구조 복원이 행·열 안정성과 셀 매칭에서 강하게 동작합니다. |
| fixed_threshold baseline | TEDS 0.7540 | 고정 임계값만으로는 다양한 표 레이아웃을 처리할 수 없다는 기준점입니다. |
| kmeans baseline | TEDS 0.3304 | 좌표 군집만으로는 병합 셀·헤더 구조 복원이 불가능하다는 한계를 보여줍니다. |
| hf_finance_legal_mrc 480샘플 최신 실행 | TEDS 0.9188, TEDS-S 0.9506, Cell F1 0.9702 | 금융·법률 문서 계열에서 구조·텍스트 유사도를 함께 개선한 결과입니다. |
수치는 모두 명시된 데이터셋·실행 조건에 묶인 실험 결과입니다.
벤치마크 콘솔 자체도 함께 만들었습니다 — 실험을 비동기 job으로 실행하고 취소·재개·stale 처리까지 다루며, CI95 신뢰구간, 메서드 간 pairwise 비교, ablation 분석을 지원합니다.
외부 VLM 계열 방법을 비교군(baseline)으로 등록해 로직 기반 접근과 같은 조건에서 비교할 수 있게 했고, 실패 사례는 케이스북으로 축적해 18개 케이스 회귀 세트로 관리했습니다.
“고치면 다른 게 깨지는” 문제를 회귀 세트 통과라는 명시적 게이트로 바꾼 것이 개선 속도를 만들었습니다.

딥다이브 ③ 보안 납품 — 고객사 서버에서 모델 보호하기
해당 솔루션은 고객사 인프라에 설치되어 돌아갑니다.
모델 가중치와 핵심 로직이 그대로 노출되는 구조로는 납품할 수 없었습니다.
secure build 파이프라인은 두 층으로 보호합니다.
모델·설정 파일은 RSA-OAEP + AES-256-GCM 하이브리드 암호화로 번들링합니다 — 대용량 자산은 AES-256-GCM으로 암호화하고, 그 키를 RSA-OAEP로 감싸는 구조입니다.
빌드 과정에서 원본 비암호화 파일은 삭제됩니다.
핵심 Python 로직은 Cython 컴파일로 바이너리화해 소스 노출을 막습니다.
실행 환경은 프로필로 분리했습니다.
개발·연구·고객 납품·모니터링 프로필이 각각 노출 기능과 포함 자산을 다르게 가져가며, 납품 프로필은 라이선스 조건과 실행 잠금 상태를 함께 검증합니다.
연구용 실험 기능이 고객 환경에 섞여 나가는 사고를 빌드 단계에서 차단하는 구조입니다.
시스템 전체 구조
표 복원과 벤치마크는 독립 모듈이 아니라 운영 가능한 제품 위에 있습니다.
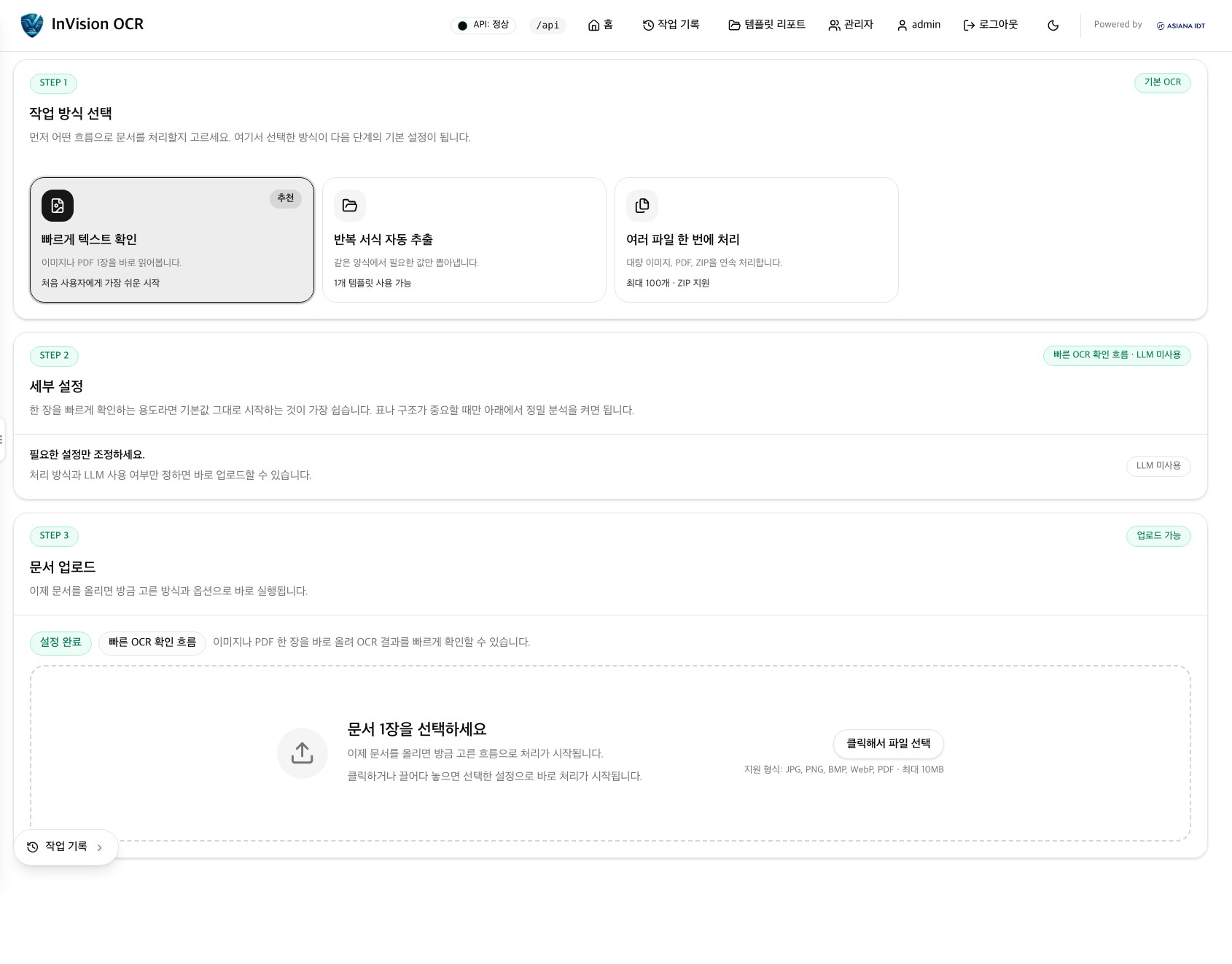
FastAPI 백엔드와 Next.js 콘솔로 이미지/PDF/ZIP 업로드, 레이아웃 분석, 영역 지정 OCR, 배치 처리, 결과 검수·이력·재처리, 템플릿 리포트, 관리자 기능(계정·권한·운영 설정)까지 하나의 흐름으로 연결했습니다.
템플릿 기반 정형 문서 추출에는 가이드 기반 위치 보정과 PDF 폴백을 붙였고, 앵커 가중치와 LLM 후처리 설정은 관리자 화면에서 직접 운영합니다.
성과
"사용자 정의 템플릿 및 가이드 기반 후보 제한과 위치 보정을 이용한 문서 정보 추출 장치 및 방법" — 표 구조 복원·템플릿 보정 기술로 출원했습니다.
보안 납품 파이프라인을 통해 고객사 전용 secure runtime으로 공급 계약을 수주했습니다.
baseline TEDS 0.754(고정 임계)·0.330(kmeans) 대비 0.9188까지, 조건이 명시된 벤치마크로 개선을 증명했습니다.
백엔드·프론트·복원 엔진·벤치마크·보안 빌드까지 전 영역을 단독으로 설계·구현했습니다.
정리
이 프로젝트에서 만든 가치는 OCR 모델을 호출하는 실행 계층이 아닙니다.
OCR 이후의 구조화 품질이라는 문제를 정의하고, 후보 생성·비교·선택이라는 복원 프레임을 설계했으며, 그 품질을 TEDS 기반 벤치마크로 측정 가능하게 만들고, 회귀 세트로 개선을 통제했으며, 결과물을 암호화 번들로 고객사에 납품 가능한 형태까지 끌고 갔습니다.
진행 중인 프로젝트이며, 표 복원 정확도와 운영 환경 검증을 계속 고도화하고 있습니다.