생성형 비디오 모델이 빠르게 좋아지고 있지만, 실제 편집 관점에서 보면 여전히 허점이 분명하다.
사람이나 물체를 영상에서 지우는 작업은 이제 데모 수준에서는 꽤 자연스럽게 보일 수 있지만, 대부분의 모델은 그 물체 “뒤에 있던 배경”만 복원하는 데 강할 뿐이다.
그림자나 반사처럼 표면적인 흔적은 어느 정도 고칠 수 있어도, 제거된 물체가 장면의 물리 상태에 영향을 줬던 경우에는 결과가 급격히 부자연스러워진다.
예를 들어 사람이 들고 있던 물건이 원래는 떨어져야 하는데 그대로 공중에 남아 있으면, 편집 결과는 금방 가짜처럼 보인다.
Netflix가 공개한 VOID(Video Object and Interaction Deletion)는 바로 이 지점을 정면으로 겨냥한다.
Hugging Face 모델 카드, GitHub 저장소, 그리고 arXiv 논문 기준으로 VOID는 단순한 video object removal 모델이 아니라, 제거 대상이 유발한 상호작용까지 함께 수정해 물리적으로 더 그럴듯한 counterfactual video를 생성하려는 프레임워크다.
즉 “무언가를 지운 뒤 배경을 메우는 모델”이라기보다, “그 물체가 애초에 없었다면 장면이 어떻게 전개됐을지를 다시 시뮬레이션하는 모델”에 더 가깝다.
흥미로운 점은 VOID가 이 문제를 순수 diffusion만으로 풀지 않는다는 것이다.
공식 설명을 보면 이 시스템은 VLM 기반 reasoning, SAM 계열 segmentation, interaction-aware quadmask, 그리고 CogVideoX 기반 video inpainting을 묶는다.
다시 말해 이 프로젝트의 핵심은 비디오 생성 모델 하나를 더 키우는 데 있지 않고, 장면에서 무엇이 인과적으로 영향을 받는지 먼저 추론한 뒤 그 정보를 생성 모델에 조건으로 밀어 넣는 데 있다.
이 글은 VOID가 무엇을 공개했고, 어떤 설계로 기존 object removal 한계를 넘으려 하며, 실무적으로 어떤 의미를 갖는지 정리한다.
무엇을 해결하려는가
기존 비디오 object removal 방법의 가장 큰 한계는 “보이는 흔적”과 “실제 상호작용”을 구분하지 못한다는 점이다.
많은 모델은 제거 대상이 가리고 있던 배경을 복원하거나, 그림자와 반사 같은 appearance-level artifact를 완화하는 데는 강하다.
하지만 그 물체가 다른 객체를 밀었거나, 받치고 있었거나, 충돌을 일으켰다면 상황이 달라진다.
이때는 단순 인페인팅이 아니라 장면 동역학 자체를 다시 써야 한다.
VOID 논문 초록이 강조하는 문제도 정확히 이것이다.
기존 방법은 object “behind” content 복원에는 강하지만, collision이나 support 같은 더 강한 상호작용이 들어가면 현재 모델들은 implausible한 결과를 만든다고 지적한다.
사람이 사라졌는데 들고 있던 기타가 공중에 그대로 남아 있거나, 물체를 밀어 생긴 연쇄 움직임이 사라지지 않는 식이다.
결국 이 프로젝트가 풀려는 핵심 문제는 object removal이 아니라 causal interaction removal이라고 보는 편이 더 정확하다.
실무적으로도 이 문제는 중요하다.
영상 편집, 광고 후반 작업, 합성 데이터 생성, counterfactual simulation 같은 작업에서 단순 배경 복원만으로는 충분하지 않기 때문이다.
편집자가 원하는 것은 “화면에서 사람 픽셀만 지우는 것”이 아니라, 그 사람이 원래 없었다면 전체 장면이 어떻게 움직였을지를 자연스럽게 다시 만드는 것이다.
VOID는 바로 그 요구를 모델링하려는 시도다.
핵심 아이디어 / 구조 / 동작 방식
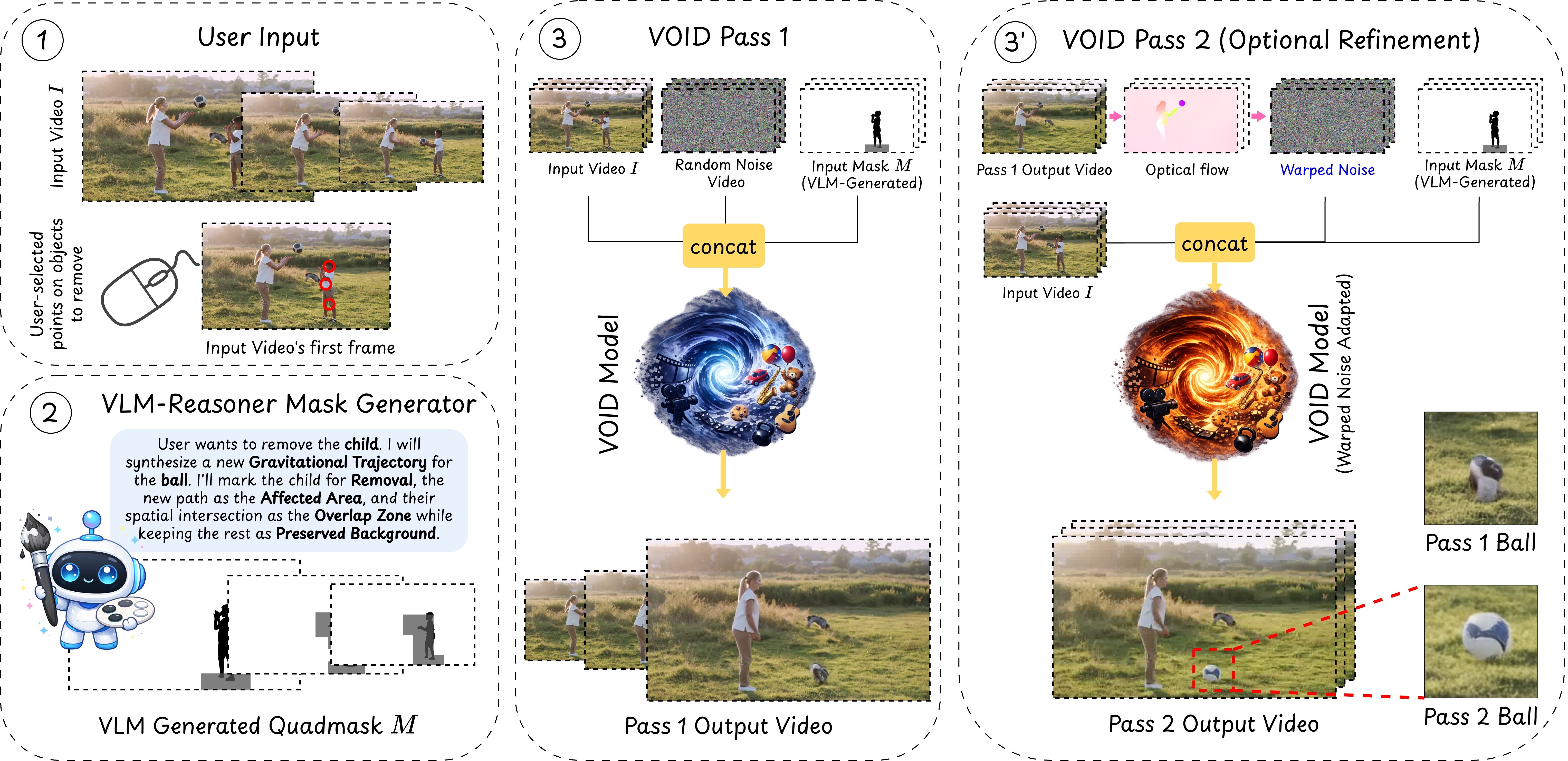
VOID의 구조에서 가장 중요한 개념은 quadmask다.
Hugging Face README 기준으로 이 마스크는 단순 binary remove/keep 마스크가 아니라 네 가지 값을 사용한다.0은 제거할 주 객체, 63은 주 객체와 영향 영역이 겹치는 구간, 127은 상호작용으로 영향을 받는 영역, 255는 그대로 유지할 배경을 뜻한다.
즉 모델은 “무엇을 지울까”만 받는 것이 아니라, “무엇이 함께 바뀌어야 하는가”까지 조건으로 입력받는다.
이 interaction-aware quadmask는 VLM-MASK-REASONER 파이프라인에서 만들어진다.
공식 GitHub 설명에 따르면 이 단계는 사용자가 제거할 물체를 클릭하면, SAM2 segmentation과 Gemini 기반 VLM reasoning을 이용해 어떤 다른 영역이 인과적으로 영향을 받는지 추론하고, 이를 최종 quadmask_0.mp4로 결합한다.
이 부분이 VOID를 단순 diffusion fine-tune과 구분하는 핵심이다.
장면의 물리적 변화 후보를 먼저 구조화한 뒤, 생성 모델은 그 구조를 따라 counterfactual 결과를 만든다.
생성 backbone은 CogVideoX-Fun-V1.5-5b-InP 위에 구축돼 있다.
모델 카드는 VOID가 이 5B급 CogVideoX 기반 video inpainting 모델을 interaction-aware conditioning으로 fine-tune했다고 밝힌다.
기본 입력은 원본 비디오, quadmask, 그리고 제거 후 배경 상태를 설명하는 text prompt다.
기본 해상도는 384x672, 최대 프레임 수는 197, scheduler는 DDIM, 메모리 효율을 위해 BF16과 FP8 quantization을 함께 사용한다.
또 하나 중요한 설계는 two-pass inference다.
Pass 1은 기본 inpainting 결과를 만든다.
그런데 프로젝트 페이지와 README는 작은 비디오 diffusion 모델에서 object morphing이 자주 생기는 failure mode를 지적한다.
이를 줄이기 위해 VOID는 optional Pass 2를 제공하는데, Pass 1 결과로부터 optical flow-warped latent noise를 초기화로 사용해 다시 추론한다.
공식 체크포인트 설명에서도 void_pass2.safetensors는 temporal consistency를 위한 warped-noise refinement 모델로 정의된다.
즉 VOID는 한 번의 생성으로 끝내지 않고, 시간축 안정성까지 별도 단계로 다루는 구조다.
훈련 데이터 전략도 흥미롭다.
공개 자료에 따르면 VOID는 HUMOTO와 Kubric 두 소스에서 paired counterfactual removal 데이터를 생성한다.
HUMOTO 쪽은 인간-물체 상호작용을 Blender 물리 시뮬레이션으로 다시 렌더링해, 사람을 제거했을 때 다른 물체가 어떻게 움직여야 하는지를 학습하게 한다.
Kubric 쪽은 object-only interaction을 다룬다.
이 구조는 실제 데이터셋을 직접 배포하기보다, 상호작용이 있는 제거 시나리오를 합성해 supervision signal을 만들겠다는 접근으로 읽힌다.
| 구성 축 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| Core task | object removal + interaction deletion | 배경 복원보다 인과적 장면 수정에 초점 |
| Conditioning | 4-value quadmask | 제거 대상과 영향 영역을 분리해서 생성 모델에 전달 |
| Backbone | CogVideoX-Fun-V1.5-5b-InP | 기존 video diffusion backbone 위에 interaction-aware finetuning 적용 |
| Inference design | Pass 1 + optional Pass 2 | 단일 생성뿐 아니라 temporal consistency를 별도 단계로 보강 |
| Mask pipeline | SAM2 + Gemini 기반 VLM reasoning | 무엇이 영향을 받는지 먼저 추론한 뒤 생성으로 연결 |
| Training data | HUMOTO + Kubric counterfactual pairs | 실제 상호작용 변화가 반영된 paired supervision 구축 |
공개된 근거에서 확인되는 점
Hugging Face API 기준으로 netflix/void-model은 2026-03-30에 생성됐고 마지막 수정 시각은 2026-04-06T17:28:28Z다. pipeline tag는 video-to-video, 라이선스는 Apache-2.0이며, 현재 공개된 체크포인트는 void_pass1.safetensors와 void_pass2.safetensors 두 개다. likes는 911로 표시되며, 모델 카드에는 arXiv 2604.02296와 데모 스페이스가 직접 연결돼 있다.
저장소는 거대한 범용 foundation model이라기보다, 특정 편집 문제를 겨냥한 task-specific checkpoint 배포물에 가깝다.
실행 요구사항은 결코 가볍지 않다.
공식 Quick Start는 Colab 노트북을 제공하지만, 동시에 A100급 40GB+ VRAM이 필요하다고 명시한다.
GitHub README는 inference용 base model로 alibaba-pai/CogVideoX-Fun-V1.5-5b-InP를 별도로 내려받아야 하고, mask generation 단계에서는 Gemini API 키와 별도 설치한 SAM2/SAM3가 필요하다고 설명한다.
즉 사용자는 VOID 체크포인트만 받는다고 바로 끝나는 것이 아니라, VLM reasoning + segmentation + video diffusion backbone까지 포함된 전체 파이프라인을 구성해야 한다.
입력 포맷도 비교적 엄격하다.
각 시퀀스는 input_video.mp4, quadmask_0.mp4, prompt.json 세 파일을 가져야 하며, prompt.json에는 제거할 물체가 아니라 제거 후 남아 있을 배경 상태를 설명하는 bg 문장을 넣어야 한다.
README 예시는 "A lime falls on the table.", "A ball rolls off the table."처럼 상호작용 이후의 결과를 직접 기술한다.
이는 VOID가 단순 텍스트 조건 생성보다 “counterfactual scene description”을 꽤 중요한 입력 신호로 본다는 뜻이다.
훈련 쪽 근거도 비교적 구체적이다.
Hugging Face 모델 카드는 8x A100 80GB 환경에서 DeepSpeed ZeRO Stage 2로 학습했다고 밝히며, 훈련 데이터는 HUMOTO와 Kubric에서 생성한 paired counterfactual video라고 설명한다.
GitHub는 라이선스 제약 때문에 생성된 데이터 자체는 배포하지 않고, 대신 data generation 코드를 공개한다.
이는 재현성과 법적 제약 사이에서 꽤 현실적인 절충이다.
논문과 프로젝트 페이지가 내세우는 실험 메시지는 정량 수치보다 qualitative superiority에 가깝다.
공개 설명은 synthetic와 real 데이터 모두에서 prior video object removal methods보다 더 consistent scene dynamics를 보였다고 주장한다.
특히 VOID가 더 나은 simulator of the world가 되려면 high-level causal reasoning이 필요하다는 framing을 반복하는데, 이는 이 프로젝트가 단순한 편집 모델을 넘어 “영상 생성 모델의 world modeling 부족분”을 찌르는 작업이라는 점을 보여준다.
| 항목 | 확인된 내용 | 해석 |
|---|---|---|
| 체크포인트 구성 | Pass 1 필수, Pass 2 선택 | 실사용은 가능하지만 temporal refinement를 별도 단계로 관리 |
| 실행 자원 | 40GB+ VRAM, base CogVideoX 필요 | 개인 로컬보다는 연구용 GPU 환경을 전제 |
| 외부 의존성 | Gemini API, SAM2/SAM3, ffmpeg, CogVideoX | 전체 파이프라인 통합 난이도가 적지 않음 |
| 데이터 공개 방식 | 데이터셋 대신 generation code 공개 | 라이선스 문제를 피하면서 재현 경로는 남김 |
| 문제 정의 | physical interaction-aware object removal | 기존 인페인팅보다 더 높은 수준의 causal editing 지향 |
실무 관점에서의 해석
내가 보기에 VOID의 가장 중요한 메시지는 “비디오 편집도 결국 world modeling 문제”라는 점이다.
지금까지 많은 생성형 편집 모델은 픽셀 공간에서 가려진 배경을 복구하는 데 초점을 맞췄다.
하지만 실제로 편집자가 원하는 것은 장면의 표면이 아니라 사건의 결과를 다시 쓰는 것이다.
사람이 장면에서 사라지면 그 사람이 밀던 공도 다른 경로로 가야 하고, 받치고 있던 물체는 떨어져야 한다.
VOID는 바로 그 차이를 구조적으로 모델링한다.
특히 quadmask 설계는 꽤 실용적인 아이디어다.
전체 문제를 완전한 end-to-end 비디오 reasoning 하나로 밀어붙이지 않고, 먼저 영향받는 영역을 명시적인 mask vocabulary로 분리해 diffusion backbone에 주입한다.
이 방식은 성능 자체보다도 시스템 설계 측면에서 의미가 크다.
앞으로 video editing 모델이 더 잘 되려면, segmentation·reasoning·generation을 하나의 monolith로만 보는 대신 이런 중간 구조 표현을 얼마나 잘 설계하느냐가 중요해질 수 있기 때문이다.
다만 도입 장벽은 높다.
40GB+ VRAM 요구사항, Gemini API 의존성, SAM 파이프라인 설치, CogVideoX base model 다운로드까지 고려하면 일반 사용자용 원클릭 편집 도구와는 거리가 있다.
정량 비교도 공개 페이지에서는 강하게 수치화돼 있지 않아, 현재 단계에서는 “흥미로운 연구 시스템 + 실험적 오픈 구현”으로 보는 편이 적절하다.
또한 interaction-aware mask 품질이 전체 결과를 크게 좌우할 가능성이 높아, 자동 reasoning 단계의 오류가 있으면 후단 생성도 쉽게 흔들릴 수 있다.
그럼에도 방향성은 매우 중요하다.
VOID는 비디오 생성 모델이 단지 보기 좋은 프레임을 만드는 수준을 넘어, 장면 안의 인과 관계를 다루는 방향으로 가야 한다는 점을 잘 보여준다.
만약 이런 접근이 더 확장되면, 앞으로의 비디오 편집 모델은 object removal을 넘어서 event editing, counterfactual simulation, post-production automation 같은 더 넓은 작업으로 이어질 수 있다.
그런 의미에서 VOID는 단순한 object eraser라기보다, “물리적으로 말이 되는 비디오 편집”을 향한 첫 번째 운영 가능한 청사진 중 하나다.