멀티모달 모델을 실제 업무에 쓰려면 결국 두 가지 질문으로 돌아온다.
범용 거대 모델 API를 계속 호출하는 편이 나은가, 아니면 작은 오픈모델을 도메인 데이터에 맞춰 직접 튜닝하는 편이 나은가.
데모 단계에서는 전자가 훨씬 빠르고 편하지만, 비용·지연·개인정보·정확도 상한을 동시에 고려하기 시작하면 이야기가 달라진다.
Oxen.ai의 “How a $1 Qwen3-VL Fine-Tune Beat Gemini 3”는 이 질문을 매우 실용적인 방식으로 검증한다.
자동차 손상 이미지를 scratch, dent, crack 세 클래스로 분류하는 문제에서, Qwen3-VL-8B를 319장 이미지로 LoRA 파인튜닝해 Gemini 3 Flash와 직접 비교했다.
결과는 꽤 강하다.
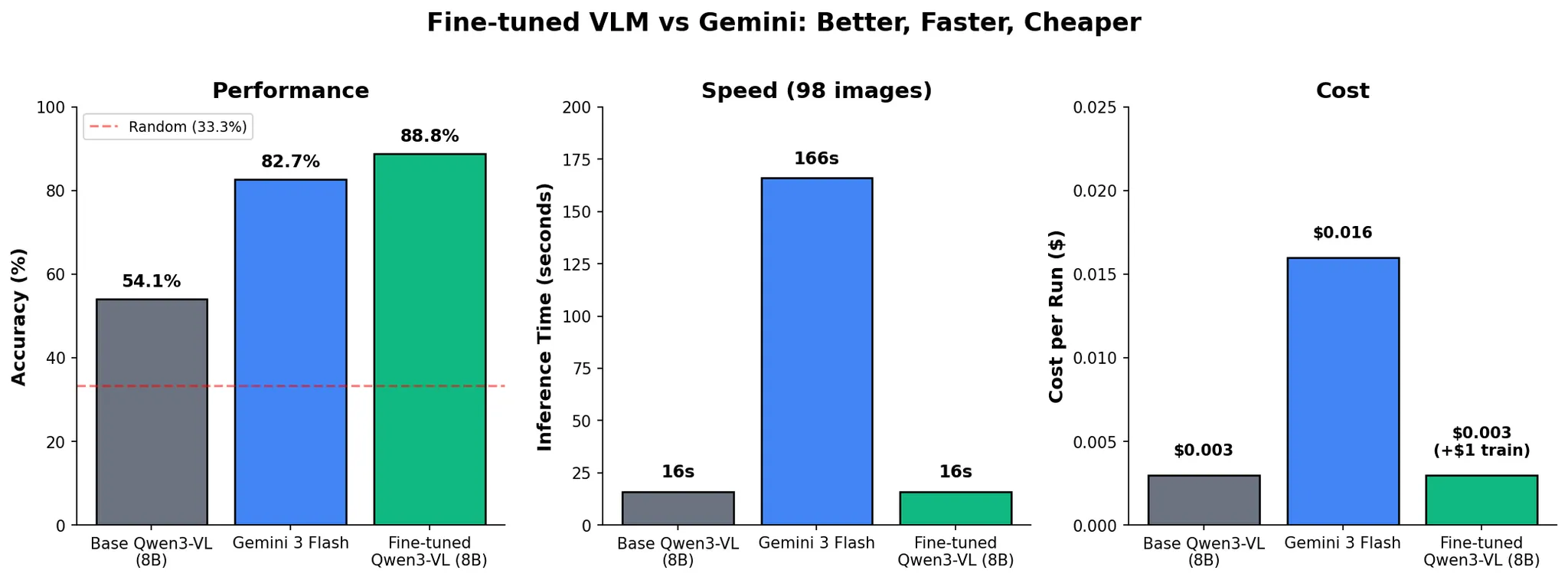
기본 Qwen3-VL은 54.1%였지만, 파인튜닝 후 88.8%까지 올라가며 Gemini 3 Flash의 82.7%를 넘어섰고, 추론 시간도 약 10초 대 166초로 더 짧았다.
이 글의 핵심은 단순히 “오픈모델이 이겼다”가 아니라, 작은 VLM을 도메인 특화 자산으로 바꾸는 과정이 생각보다 싸고 빠르며, 무엇을 점검해야 성능이 실제로 올라가는지를 꽤 투명하게 보여준다는 점이다.
무엇을 해결하려는가
이 사례가 겨냥하는 문제는 범용 VLM이 특정 시각 분류 업무에서 얼마나 빨리 한계에 부딪히는가다.
자동차 손상 분류는 얼핏 단순해 보이지만, 실제로는 균열(crack)과 긁힘(scratch)의 경계가 매우 모호하고, 찌그러짐(dent)에 긁힌 페인트가 함께 붙어 있는 경우도 많다.
게다가 보험 심사처럼 대량 처리 환경에서는 요청당 몇 센트 차이도 누적되면 큰 비용 차이로 바뀐다.
Oxen.ai가 강조하는 포인트도 바로 여기에 있다.
이미지 입력이 들어가는 순간 prompt engineering만으로 성능을 끌어올리는 데 한계가 생기고, latency와 비용도 API 경로에서 빠르게 커진다.
반대로 도메인 데이터가 수백 장 수준으로라도 잘 정리돼 있다면, 작은 오픈모델에 task-specific decision boundary를 학습시키는 편이 더 낫다는 가설을 세울 수 있다.
이 실험은 그 가설을 보험 손상 판정이라는 구체적 업무로 바꾼다.
즉, “범용 멀티모달 모델을 쓰는 편의성”과 “도메인 특화 파인튜닝이 주는 성능·속도·비용 이점”을 실제 수치로 비교하는 테스트베드에 가깝다.
핵심 아이디어 / 구조 / 동작 방식
데이터는 USTC의 CarDD(Car Damage Detection)에서 출발한다.
CarDD 자체는 약 4,000장의 고해상도 이미지와 9,000개 이상의 손상 인스턴스를 포함하는 공개 자동차 손상 데이터셋으로, 원래는 detection과 segmentation까지 염두에 둔 구조다.
다만 Oxen.ai는 빠른 분류 실험을 위해 여기서 단일 손상 카테고리만 가진 이미지로 subset을 만들고, 최종적으로 crack, dent, scratch 세 클래스로 단순화했다.
이렇게 정리된 샘플 수는 417장이다.
여기서 중요한 것은 모델보다 먼저 데이터를 정리했다는 점이다.
저자들은 Karpathy의 “become one with the data” 흐름을 따라, 시각적으로 train/test leakage를 확인하고 CLIP 임베딩 기반 cosine similarity로 중복에 가까운 샘플을 자동 탐지했다.
임계값 0.95 이상인 test-train 쌍 126개를 의심 사례로 잡고, 최종적으로 19개 테스트 이미지를 제거해 98개 test sample을 만들었다.
즉 성능 향상의 시작점은 LoRA rank 조정이 아니라, eval split을 먼저 믿을 수 있게 만든 것이다.
모델 쪽에서는 Qwen3-VL-8B에 LoRA를 붙였다.
기사 설명에 따르면 Qwen3-VL의 구조는 크게 vision encoder, projection layer, LLM backbone으로 나뉘고, 이미지 패치 토큰과 텍스트 토큰이 하나의 flat sequence로 이어진 뒤 self-attention을 공유한다.
학습은 attention 계열 모듈을 대상으로 한 LoRA 설정이며, 공개된 주요 하이퍼파라미터는 rank 64, alpha 16, learning rate 2e-4, batch size 4, epoch 3, target modules q,k,v,o_proj다.
실험 과정에서 발견한 구현 함정도 흥미롭다.
첫째, completion_only_loss=False 상태에서는 모델이 이미지 토큰까지 예측하려고 하면서 loss가 제대로 내려가지 않았다.
텍스트 출력에만 loss를 걸도록 바꾸자 학습이 정상화됐다.
둘째, SGLang의 LoRA 필터가 model.layers.* 패턴만 매칭하고 visual.* 계열 모듈은 런타임 적용에서 건너뛰는 문제가 있어, 단순 LoRA attach 대신 weight merge 방식으로 배포해야 했다.
이 지점은 “학습 loss는 잘 내려가는데 추론은 base model과 거의 같다”는 식의 현업형 디버깅 문제를 잘 보여준다.
| 항목 | 원본 CarDD | Oxen 실험용 subset |
|---|---|---|
| 데이터 규모 | 약 4,000장 | 417장 |
| 원래 태스크 | detection + segmentation | classification |
| 라벨 구조 | 복수 손상 가능 | 단일 라벨 |
| 사용 클래스 | 6개 손상 범주 기반 | crack / dent / scratch |
| 평가셋 정리 | 원본 기준 | CLIP 유사도 기반 leakage 제거 후 98장 test |
공개된 근거에서 확인되는 점
가장 눈에 띄는 수치는 최종 scoreboard다.
기사 기준으로 base Qwen3-VL-8B는 54.1%, Gemini 3 Flash는 82.7%, 파인튜닝된 LoRA Qwen3-VL은 88.8%를 기록했다.
같은 98개 평가 샘플 기준에서 오픈모델이 범용 상용 모델을 6.1%p 앞선 셈이다.
추론 시간은 base와 LoRA Qwen3-VL이 약 10초, Gemini 3 Flash가 166초였고, run cost는 각각 0.003달러와 0.016달러로 제시된다.
학습비도 인상적이다.
319장 학습 run이 약 8분, 비용은 1달러였다고 적혀 있다.
중간 결과를 보면 78개 샘플 학습 시 정확도는 67.3%, 319개에서는 88.8%까지 상승한다.
즉 단순히 “파인튜닝이 된다”가 아니라, 소량 데이터 추가가 성능 상승으로 이어지는 learning curve가 아직 plateau에 도달하지 않았다는 신호까지 같이 보여준다.
클래스별 개선 폭은 더 극적이다. base 모델에서 crack 클래스 정확도는 19.4%에 불과했지만, fine-tuned 모델에서는 96.8%까지 올라간다. scratch도 65.7%에서 91.4%로 상승했고, dent는 75.0%에서 78.1%로 상대적으로 완만하게 오른다.
즉 이 실험의 본질은 평균 정확도 개선보다도, 기본 모델이 거의 이해하지 못하던 crack decision boundary를 도메인 데이터가 재구성했다는 데 있다.
Gemini 3 Flash와의 직접 대결 표도 흥미롭다.
LoRA Qwen3-VL이 맞고 Gemini가 틀린 경우가 10장, 반대가 4장, 둘 다 맞은 경우가 77장, 둘 다 틀린 경우가 7장으로 제시된다.
표본이 아주 크진 않지만, 단순 평균 차이뿐 아니라 샘플 단위로도 작은 우위가 있음을 보여준다.
동시에 저자들은 98개 test sample, 87 vs 81 correct처럼 차이가 6장이라는 점도 솔직하게 적어 두며 과도한 일반화를 경계한다.
| 모델 | 정확도 | 98샘플 추론 시간 | run 비용 | 학습 비용 |
|---|---|---|---|---|
| Base Qwen3-VL-8B | 54.1% | 약 10초 | $0.003 | - |
| Gemini 2.0 Flash (batch) | 78.6% | 203초 | $0.0015 | - |
| Gemini 3 Flash | 82.7% | 166초 | $0.016 | - |
| LoRA Qwen3-VL | 88.8% | 약 10초 | $0.003 | $1 |
| 클래스 | Base | Fine-tuned | 변화 |
|---|---|---|---|
| Crack | 19.4% | 96.8% | +77.4%p |
| Dent | 75.0% | 78.1% | +3.1%p |
| Scratch | 65.7% | 91.4% | +25.7%p |
실무 관점에서의 해석
내가 보기에 이 사례의 핵심은 “오픈모델이 클로즈드 모델을 이겼다”보다도, 성능 향상의 대부분이 모델 교체보다 데이터 정리와 평가 설계에서 나왔다는 점이다. leakage를 제거하고, multi-label에 가까운 현실을 single-label 태스크로 어떻게 단순화할지 명시하고, crack 클래스가 왜 어려운지 실제 샘플을 보고 해석한 뒤 파인튜닝을 걸었다.
즉 이 결과는 단순한 LoRA 성공담이 아니라, 작은 도메인 데이터셋을 운영 가능한 학습 문제로 바꾸는 절차의 승리에 가깝다.
또 하나 중요한 점은 VLM 파인튜닝이 텍스트 모델 파인튜닝보다 구현 함정이 더 많다는 사실이다. loss masking, vision 모듈 대상 adaptation, 런타임 serving stack의 LoRA 적용 범위 같은 이슈는 대시보드 숫자만 봐서는 잘 드러나지 않는다.
이 글은 그런 함정을 비교적 솔직하게 드러내기 때문에, 단순한 마케팅 글보다 실무 레퍼런스로 쓸 가치가 있다.
물론 한계도 분명하다. test set은 98장으로 작고, 단일 도메인 실험이며, single-label framing 자체가 현실의 복합 손상 상황을 충분히 반영하지 못한다.
또한 Oxen.ai 플랫폼 위에서 정리된 학습·배포 경험과, 범용 self-hosted 스택에서의 재현 난도는 다를 수 있다.
따라서 이 결과를 “모든 시각 업무에서 작은 파인튜닝 모델이 Gemini보다 낫다”로 읽으면 과하다.
그럼에도 불구하고 방향성은 명확하다.
프로토타이핑은 큰 API 모델로 시작하되, 반복 비용과 latency가 커지고 prompt engineering만으로는 더 이상 성능이 안 오를 때, 수백 장 수준의 정제된 도메인 데이터와 작은 오픈 VLM 파인튜닝이 매우 현실적인 다음 카드가 될 수 있다.
이 사례는 그 전환점이 생각보다 훨씬 낮은 비용과 짧은 시간에 도달할 수 있음을 보여준다.