대형 언어모델 post-training을 실제 서비스로 운영할 때 병목은 “LoRA를 붙일 수 있는가”보다 “붙인 LoRA를 몇 개나, 어떤 상태로, 얼마나 자주 바꿔가며, 어떤 근거로 다시 서빙할 수 있는가”에 가깝다.
단일 실험에서는 LoRA adapter가 작은 파일로 보이지만, 제품 환경에서는 task branch, tenant variant, rollback point, evaluation snapshot, personalization branch가 계속 늘어난다.
이때 각 변형을 full checkpoint나 별도 model server로 다루면, 모델 수가 늘어나는 순간 운영 표면이 폭발한다.
Mind Lab의 기술 보고서 MinT: Managed Infrastructure for Training and Serving Millions of LLMs는 이 문제를 꽤 명확하게 재정의한다.
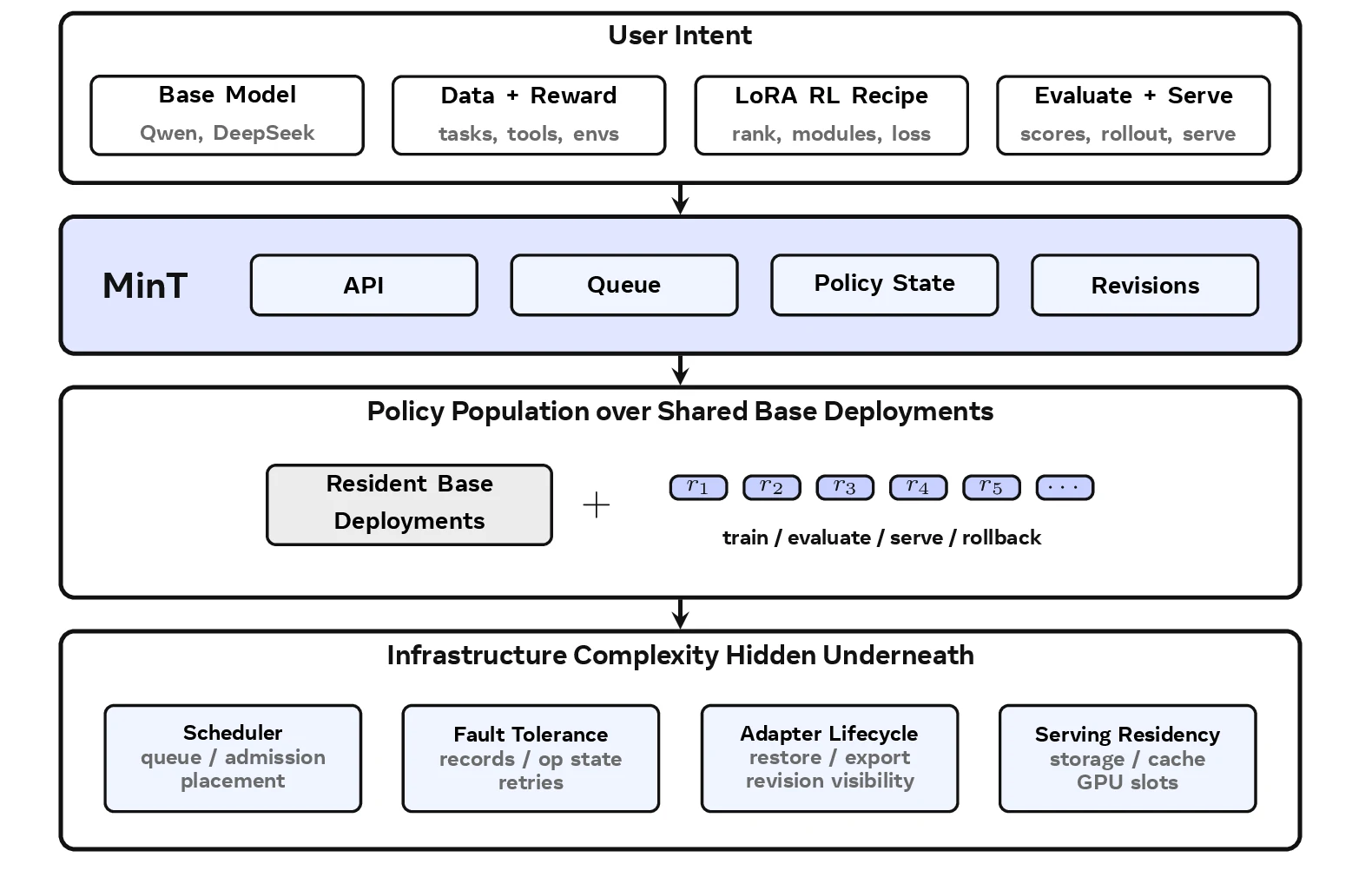
MinT(MindLab Toolkit)는 LoRA를 단순한 parameter-efficient fine-tuning 기법이 아니라 서비스가 관리하는 policy revision 단위로 본다.
Base model은 trainer, sampler, serving actor 안에 resident로 남겨두고, 학습된 행동은 export된 LoRA adapter revision으로 이동시킨다.
즉 “모델을 매번 다시 만든다”가 아니라 “같은 base 위에서 수많은 정책 revision을 스케줄링한다”는 관점이다.
논문이 흥미로운 이유는 이 주장을 개념도에서 멈추지 않고, training-serving handoff, concurrent GRPO schedule, dense/MoE scaling, adapter catalog/cache/cold-load 같은 시스템 지표로 쪼개서 보여준다는 점이다.
물론 이 보고서는 Mind Lab이 자사 managed service를 설명하는 기술 보고서이며, backend 전체가 공개 self-host framework로 제공되는 형태는 아니다.
따라서 수치는 독립 재현 benchmark라기보다 공개된 기술 보고서와 companion repo가 제시하는 시스템 evidence로 읽는 편이 맞다.
그럼에도 LoRA를 운영 단위로 격상시키는 설계는 post-training infra를 보는 데 꽤 좋은 프레임을 준다.
무엇을 해결하려는가
기존 LoRA workflow는 보통 두 단계로 설명된다.
Base model을 고정하고 LoRA만 학습한 뒤, 필요하면 base에 merge해서 checkpoint를 만든다.
연구 코드에서는 이것으로 충분해 보인다.
하지만 RL post-training이나 agent 학습에서는 rollout, scoring, update, export, evaluation이 반복되고, 그 사이에 여러 policy branch가 동시에 생긴다.
한 policy를 update한 뒤 다음 rollout이 정확히 어떤 adapter revision으로 생성됐는지, 그 revision이 어느 base deployment와 호환되는지, serving cache에서 이미 warm인지 cold-load가 필요한지, 실패 시 어디서 resume해야 하는지까지 관리해야 한다.
MinT는 이 상태를 두 객체로 나눈다.
| 개념 | MinT에서의 의미 | 왜 중요한가 |
|---|---|---|
| Adapter revision | 특정 training step에서 freeze/export된 LoRA adapter snapshot. Serving layout의 executable payload | rollout/evaluation/serving이 선택하는 “고정된 행동” 단위 |
| Policy record | base version, LoRA rank/target module, training checkpoint, optimizer state, rollout record, exported revisions를 묶는 durable service state | 같은 행동을 resume, score, export, evict, reload, rollback할 수 있게 하는 운영 상태 |
| Resident base deployment | trainer/sampler/serving actor 안에 계속 올라와 있는 비싼 base model | policy마다 full model을 다시 옮기지 않기 위한 전제 |
| Adapter cache tier | durable catalog, CPU cache, GPU batch slot의 세 계층 | “이름으로 선택 가능한 정책 수”와 “지금 GPU에서 실행 중인 adapter 수”를 분리 |
이 분리가 핵심이다.
LoRA 파일 하나만 있다고 해서 운영 가능한 policy가 되는 것은 아니다.
학습을 이어가려면 optimizer moment와 scheduler position이 필요하고, RL scoring에는 rollout record가 필요하며, serving에는 base compatibility와 tensor layout이 필요하다.
MinT의 메시지는 adapter bytes와 service state를 분리해 관리해야, 많은 policy revision을 하나의 shared-base fleet 위에서 다룰 수 있다는 것이다.
핵심 아이디어 / 구조 / 동작 방식
MinT의 runtime은 Tinker-compatible client interface를 앞에 두고, 뒤에서는 service plane과 compute plane을 분리한다.
사용자는 sample rollout, gradient computation, optimizer step, adapter export, evaluation/serving 같은 작업을 service call로 보낸다.
Service plane은 request를 검증하고, pollable operation id를 만들고, policy record를 해석한 뒤 compatible worker에 작업을 admission한다.
Compute plane에는 single-worker PEFT trainer, distributed Megatron trainer group, vLLM sampler/serving actor가 있다.
이 구조를 한 문장으로 줄이면 다음과 같다.
Base model은 가능한 한 resident로 유지하고, LoRA adapter revision만 rollout/update/export/evaluation/serving 경계를 건너게 한다.
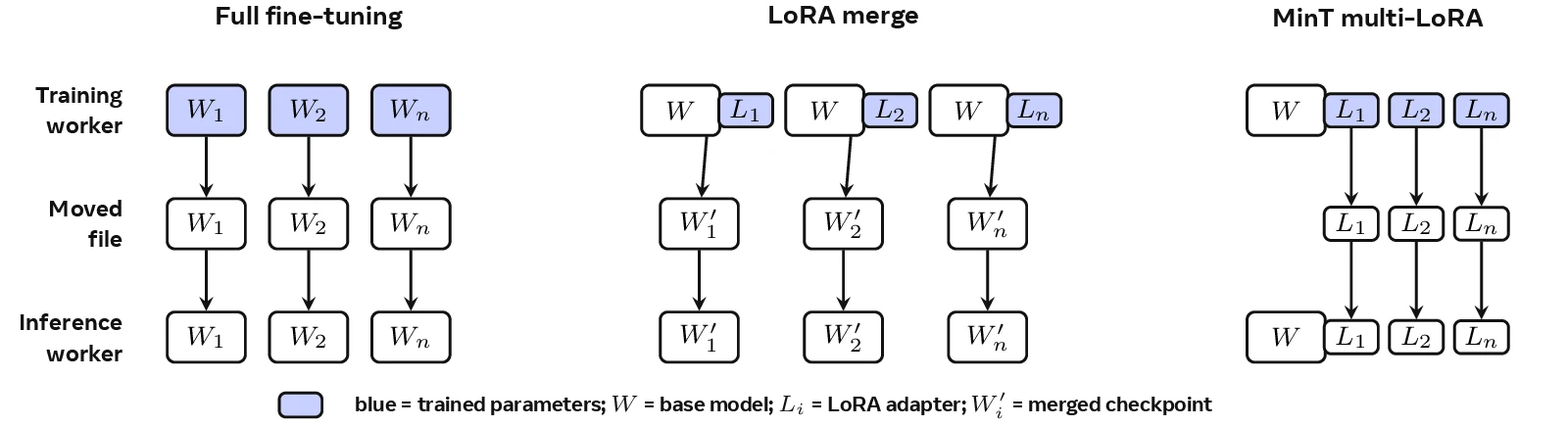
위 그림에서 차이가 선명하다.
Full fine-tuning은 각 variant마다 full checkpoint를 옮긴다.
Merge-based LoRA는 학습 중에는 adapter를 쓰지만, serving 전에 base와 merge된 full checkpoint를 다시 만든다.
MinT multi-LoRA는 inference engine이 compatible base를 이미 들고 있다고 가정하고, 학습된 adapter revision만 넘긴다.
그래서 “LoRA가 작다”는 단순한 장점이 service boundary의 설계 원칙으로 바뀐다.
논문은 MinT의 scaling을 세 축으로 나눈다.
| 축 | 질문 | MinT의 답 |
|---|---|---|
| Scale Up | 30B, 235B, 1T급 dense/MoE base에서도 LoRA RL lifecycle이 유지되는가 | Megatron training group, tensor/expert parallel export, MoE route replay, sparse-attention mismatch correction으로 대형 base를 resident하게 다룸 |
| Scale Down | Training에서 serving으로 넘어갈 때 full checkpoint materialization을 피할 수 있는가 | PEFT adapter revision만 export/load해 handoff cost를 줄임 |
| Scale Out | 수천~수백만 policy revision을 request name으로 선택 가능하게 하면서 GPU working set을 bounded하게 유지할 수 있는가 | durable catalog, CPU cache, GPU batch slot을 분리하고 cold-load를 scheduled service work로 관리 |
특히 좋은 점은 “million-scale”이라는 단어를 GPU resident adapter 수로 과장하지 않는다는 것이다.
논문은 10^6 scale을 addressable catalog 규모로 설명하고, 실제 engine-local execution은 CPU cache와 GPU batch slot으로 제한된다고 반복해서 선을 긋는다.
이 구분이 없으면 multi-LoRA serving 주장은 쉽게 마케팅 문구가 된다.
MinT의 경우 적어도 보고서 안에서는 catalog scale, CPU-cache residency, same-batch adapter diversity, cold-load cost를 분리해 말한다.
공개된 근거에서 확인되는 점
Scale Down 쪽 수치가 가장 직관적이다.
Qwen3-4B에서는 rank-32 LoRA adapter 파일이 252MiB이고, full model checkpoint는 8.061GB다.
Qwen3-30B에서는 rank-16 adapter가 1.692GB, full model checkpoint가 61.084GB다.
논문은 adapter-only handoff가 4B dense model에서 measured handoff step을 18.3배, 30B MoE model에서 2.85배 줄였다고 보고한다.
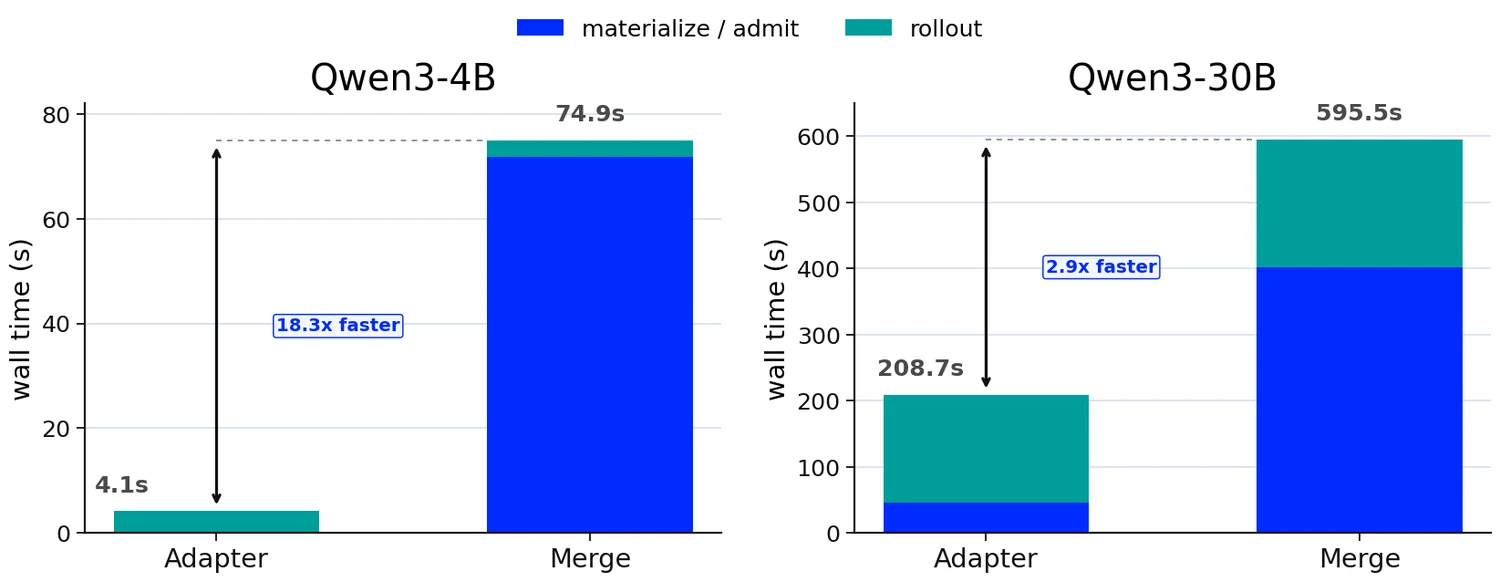
| 모델 | 경로 | 이동/로드되는 artifact | 파일 크기 | Materialization/load | 해석 |
|---|---|---|---|---|---|
| Qwen3-4B | Adapter | rank-32 LoRA | 252MiB | 0.036s | base를 다시 만들지 않고 adapter만 resident sampler에 붙임 |
| Qwen3-4B | Merge | full model | 8.061GB | 71.820s | merge된 checkpoint 생성/로드가 handoff를 지배 |
| Qwen3-30B | Adapter | rank-16 LoRA | 1.692GB | 46.455s | MoE에서도 full checkpoint보다 훨씬 작은 crossing artifact |
| Qwen3-30B | Merge | full model | 61.084GB | 402.245s | 대형 MoE에서는 full checkpoint materialization 부담이 더 커짐 |
Concurrent training 결과도 같은 방향이다.
세 개의 GRPO policy를 순차 실행하는 대신, 같은 resident-base allocation 안에서 idle gap을 채워 겹쳐 실행하면 Qwen3-4B는 3081.2초에서 1736.1초로 줄고, Qwen3-30B는 10130.0초에서 7008.4초로 줄었다.
보고서 기준 speedup은 각각 1.77배, 1.45배이며 peak memory는 각 모델 크기에서 동일하게 유지된다.
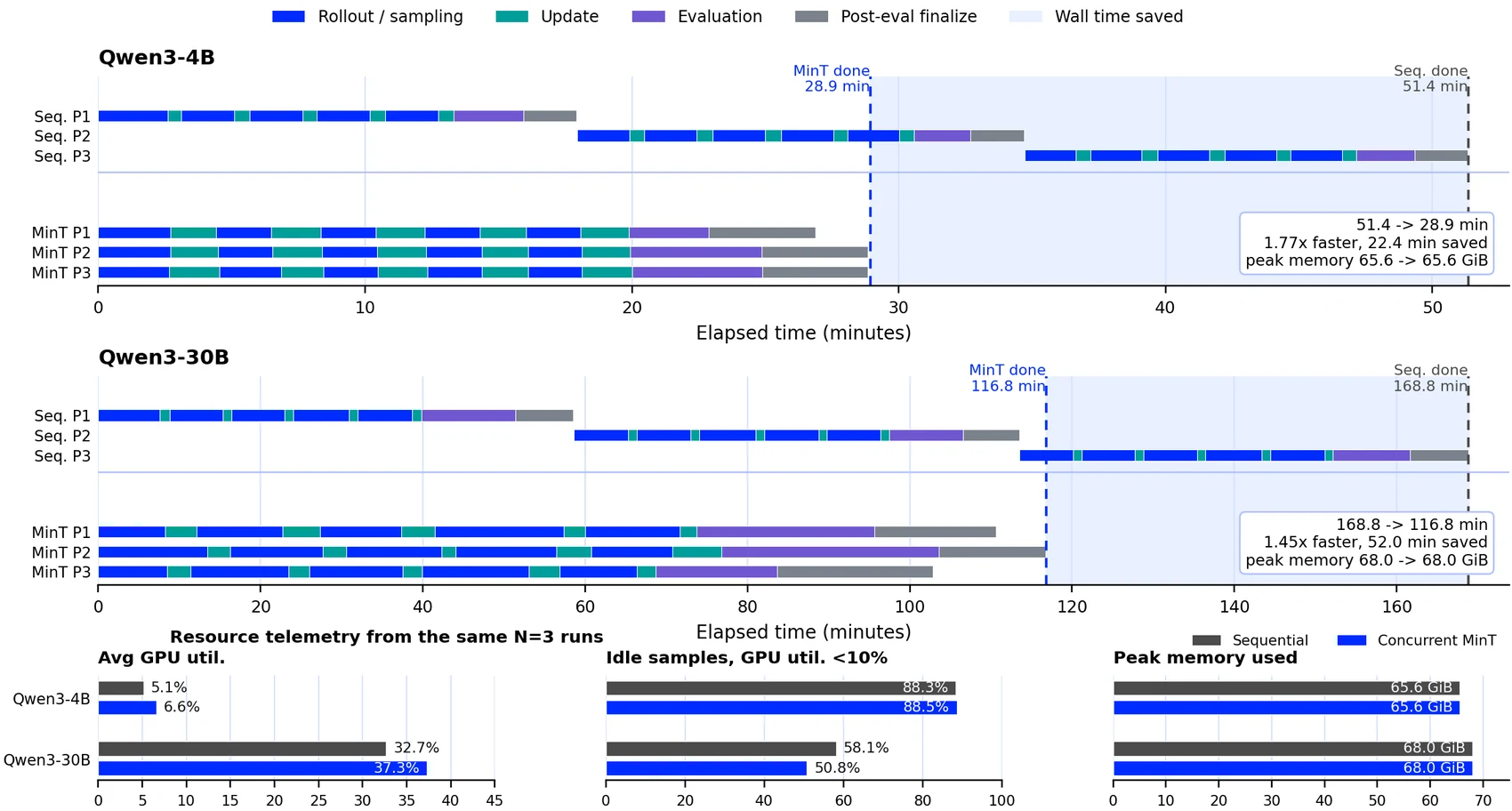
여기서 중요한 점은 “한 모델 계산 자체가 마법처럼 빨라졌다”가 아니다.
MinT가 얻는 이득은 resident base를 중심으로 여러 policy의 rollout/update/export/evaluation phase 사이 idle window를 채우는 schedule utilization에서 나온다.
즉 GPU memory 대부분을 차지하는 base를 policy마다 중복 배치하지 않고, adapter와 training state만 바꾸며 policy population을 돌리는 방식이다.
Scale Up evidence는 dense/MoE model family를 모두 통과한다.
Dense 쪽에서는 Qwen3-4B SFT/DPO, Qwen3-8B GRPO trace를 보여준다.
예를 들어 SFT는 Fineval accuracy를 0.4226에서 0.7811로, FPB를 0.6906에서 0.8804로 올렸고, DPO는 reward margin을 -0.03에서 30.88로, GRPO는 AIME24 train accuracy EMA를 0.11에서 0.47로 올렸다고 보고한다.
MoE 쪽에서는 Qwen3-30B-A3B, Qwen3-235B-A22B, Kimi K2 1.04T countdown-task path가 등장한다.
특히 Qwen3-235B-A22B는 AIME24 mean@1 peak 0.967을 보고한다.
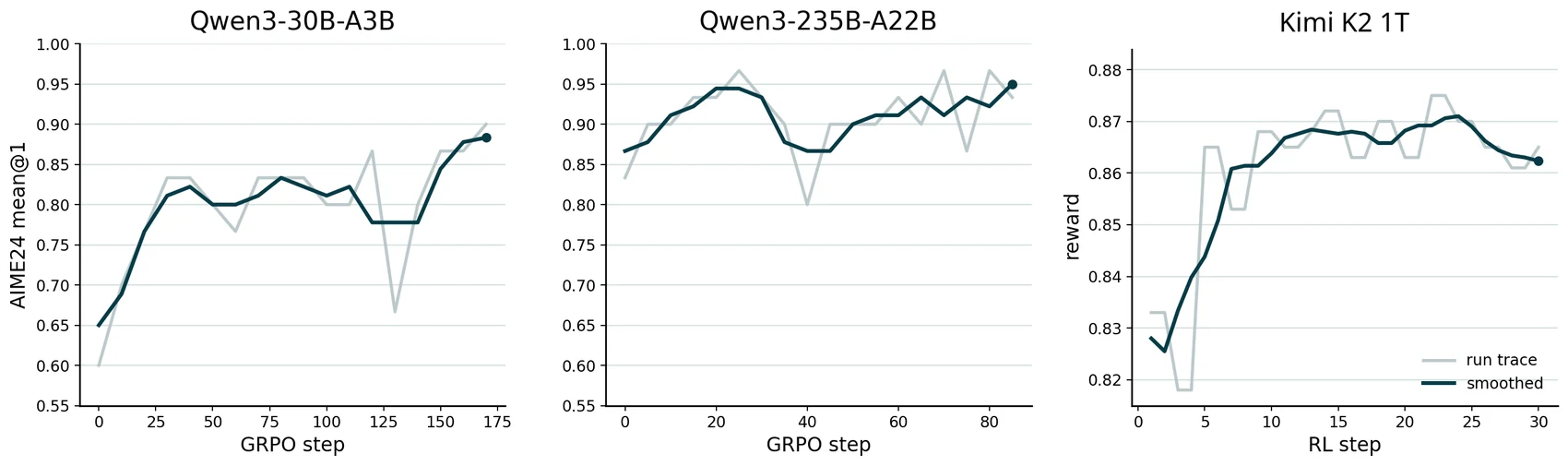
물론 이 수치들은 “MinT라는 infra만으로 모델 성능이 좋아진다”는 의미가 아니다.
더 정확히는 SFT, DPO, GRPO, MoE RL 같은 서로 다른 training paradigm이 같은 adapter lifecycle 위에서 실행될 수 있음을 보여주는 evidence에 가깝다.
MinT의 논점은 algorithmic novelty보다 대형 base, sharded trainer, vLLM sampler, exported PEFT adapter, evaluation/serving record를 하나의 운영 경로로 잇는 것이다.
Scale Out은 serving 쪽에서 더 시스템스럽다.
논문은 Qwen3-30B rank-1 MoE LoRA adapter를 한 4-GPU tensor-parallel serving actor에서 실험한다.
핵심은 addressable catalog, CPU cache, GPU batch를 분리하는 것이다.
| 계층 | 보고된 규모/한계 | 의미 |
|---|---|---|
| Addressable catalog | 1k~100k sweep, appendix에서 10^6 catalog sizing | request가 이름으로 선택할 수 있는 durable policy namespace |
| CPU adapter cache | 512 hotset에서 369 loaded adapters, weak-locality 2048 target에서 550 loaded adapters | 한 serving actor 가까이에 warm하게 둘 수 있는 adapter 수 |
| GPU batch | tested same-batch window 64 distinct adapters | 한 decoding step에서 실제로 같이 실행되는 adapter diversity |
| Cold loading | warm p95 21.35s, cold-cache p95 199.81s, 16 unique cold loads 1.375~23.267s | cache miss는 generation 이전의 별도 scheduled service work |
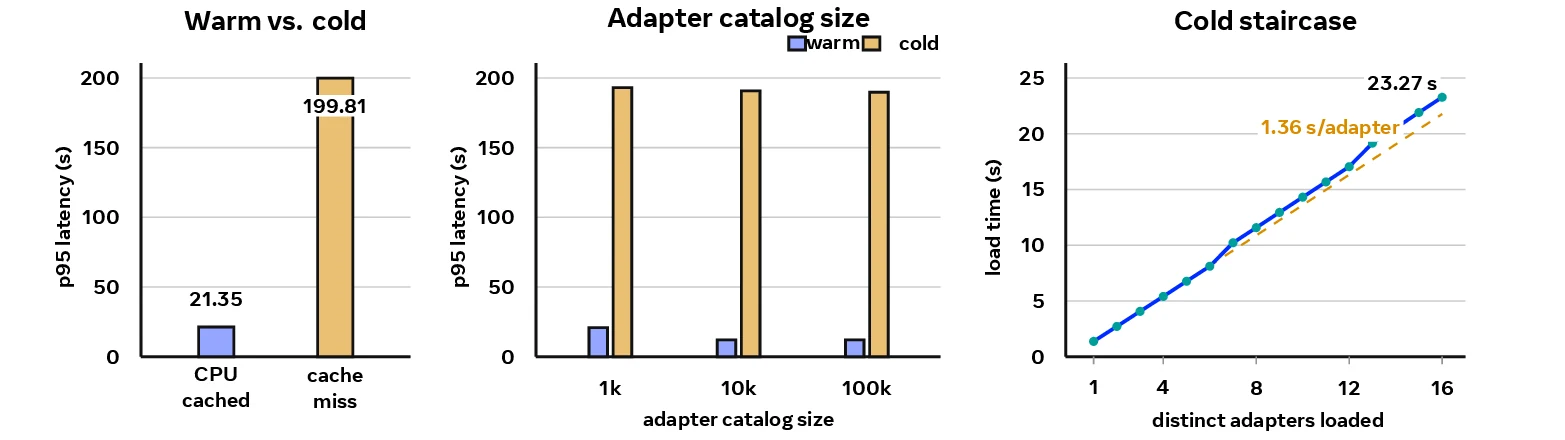
이 대목에서 가장 실용적인 경고는 cold-load다.
Adapter 파일이 full checkpoint보다 작아도, cache miss가 무료가 되는 것은 아니다.
논문은 16개 서로 다른 missing policy가 들어오면 load staircase가 1.375초에서 23.267초까지 올라가며, policy당 약 1.35~1.40초의 serialized load cost가 생긴다고 설명한다.
따라서 multi-LoRA serving에서 중요한 것은 adapter 파일 크기만이 아니라 routing locality, prewarming, cache admission, backpressure다.
Packed MoE LoRA representation은 이 cold path를 줄이기 위한 최적화다.
원래 rank-1 MoE LoRA adapter는 37,248개 tensor object로 쪼개져 있었고, packed representation은 이를 672개로 줄인다.
파일 크기는 110.75MB에서 105.58MB로 거의 비슷하지만, tensor object fanout이 줄면서 live engine loading median이 8.5~8.7배 빨라진다.
| 항목 | Original | Packed | 효과 |
|---|---|---|---|
| File size | 110.75MB | 105.58MB | 1.05배 작음 |
| Tensor objects | 37,248 | 672 | 55.4배 적음 |
| Read tensors | 0.3669s | 0.0067s | 54.8배 빠름 |
| Build loader objects | 0.7540s | 0.0256s | 29.5배 빠름 |
| N=4 live load | 1.363s | 0.156s | 8.7배 빠름 |
| N=16 live load | 1.388s | 0.164s | 8.5배 빠름 |
이 결과는 꽤 좋은 시스템 교훈을 준다.
Serving latency는 “몇 MB인가”만으로 결정되지 않는다.
수만 개의 작은 tensor object를 Python/engine loader가 다루는 비용이 cold-load tail을 만들 수 있다.
대규모 multi-adapter serving에서는 object layout 자체가 latency optimization surface가 된다.
Companion repo와 제품 표면
공개된 companion surface도 확인할 만하다.MindLab-Research/mindlab-toolkit은 GitHub API 기준 MIT license, Python >=3.11, tinker==0.15.0 dependency를 가진 client toolkit이다.
README는 import mint as tinker 형태의 migration을 강조하며, MinT credential과 endpoint를 사용하면 Tinker-style client surface를 유지할 수 있다고 설명한다.
즉 논문이 말하는 Tinker-compatible service interface가 실제 client package 설계에도 드러난다.
다만 중요한 caveat가 있다. mint-quickstart README는 모든 실험이 이미 배포된 MinT server를 대상으로 실행되며, 이 repo가 backend service를 local에서 띄우지 않는다고 명시한다.
즉 현재 공개 repo는 “완전한 self-host MinT cluster”라기보다, managed MinT endpoint/API key를 전제로 한 quickstart와 demo portfolio에 가깝다.
Verifiable math RL, preference chat, environment tool use, sampling log, OpenPI/VLA demo 등이 제공되지만, backend scheduling/serving plane 자체를 로컬에서 재현하는 형태는 아니다.
이 점을 감안하면 MinT를 평가하는 올바른 태도는 둘 중 하나다.
| 관점 | 읽는 방식 |
|---|---|
| 연구/시스템 아이디어 | LoRA를 policy revision으로 승격하고, base residency + adapter lifecycle + cache tiers로 post-training infra를 설계하는 사례 |
| 도입/운영 검토 | managed service access, API key, endpoint, 지원 모델, 데이터 보안, cold-load SLO, backend visibility를 별도로 확인해야 하는 제품 |
Macaron/Mind Lab의 MinT 제품 페이지는 MinT를 “agents and models learn from real experience”를 위한 RL infrastructure라고 설명하며, compute scheduling, distributed rollout, training orchestration을 추상화한다고 말한다.
공개 페이지에는 Qwen, DeepSeek, Kimi, GLM, MiniMax, VLA 계열 모델 지원이 언급된다.
하지만 실제 production 도입에서는 공개 논문보다 service contract, data ownership, audit log, deployment region, quota, failure handling이 더 중요해질 것이다.
실무 관점에서의 해석
내가 보기에 MinT의 가장 중요한 메시지는 LoRA의 의미를 바꾸는 데 있다.
많은 팀은 LoRA를 “GPU memory를 덜 쓰는 fine-tuning trick”으로만 본다.
MinT는 한 단계 더 나아가 LoRA를 서비스가 versioning, scheduling, rollback, cache, serving할 수 있는 policy artifact로 만든다.
이 관점에서는 adapter가 작은 이유보다, adapter가 독립적으로 이름 붙고, export되고, evaluation score와 연결되고, cache tier를 이동하며, rollback 가능한 revision이 된다는 점이 더 중요하다.
이 설계는 agent post-training과 잘 맞는다.
Agent는 하나의 final checkpoint보다 계속 바뀌는 behavior population에 가깝다.
어떤 tenant는 tool-use policy v7을 쓰고, 어떤 실험은 reward 변경 후 v12를 평가하며, 어떤 rollout은 이전 revision으로 rollback해야 한다.
Full checkpoint 중심 운영에서는 이런 변화가 model deployment explosion으로 이어진다.
Adapter revision 중심 운영에서는 base fleet는 비교적 안정적으로 두고, behavior 변화만 adapter population으로 다룰 수 있다.
반대로 한계도 분명하다.
첫째, million-scale 주장은 동시 GPU 실행 규모가 아니라 addressable catalog 규모다.
실제 latency와 throughput은 CPU cache hit rate, same-batch adapter diversity, cold-load queue, routing locality에 좌우된다.
논문도 이 점을 인정하고 있으며, cold-cache p95 199.81초 같은 수치는 multi-LoRA serving이 “adapter가 작으니 항상 빠르다”가 아님을 보여준다.
둘째, backend 전체가 공개 self-host stack으로 재현되는 것은 아니다.
Client toolkit과 quickstart는 유용하지만, 논문 수치를 독자가 같은 cluster control plane에서 그대로 재현하기는 어렵다.
따라서 수치를 benchmark처럼 절대화하기보다, 시스템 설계와 evidence boundary를 읽는 편이 안전하다.
셋째, MoE/DSA mismatch 처리는 복잡하다.
Qwen3-style MoE에서는 selected expert ids를 rollout record에 저장해 training-time scoring에 활용할 수 있지만, GLM-5-style dynamic sparse attention에서는 모든 sparse-attention token selection을 완전히 replay하지 못한다.
MinT는 IcePop-style rollout correction으로 training/rollout probability ratio가 trusted band를 벗어난 token의 importance weight를 0으로 만드는 mitigation을 사용한다.
즉 일부 sparse path는 “정확한 재현”보다 “불안정한 gradient term 제거”에 가깝다.
그럼에도 MinT는 앞으로 post-training infrastructure가 어디로 가야 하는지 꽤 잘 보여준다.
모델 하나를 잘 학습하는 시대에서, 많은 behavior revision을 shared frontier base 위에서 계속 만들고, 평가하고, 되돌리고, 서빙하는 시대로 이동하고 있기 때문이다.
그런 환경에서는 adapter가 단순 파일이 아니라 lifecycle을 가진 운영 객체가 된다.
MinT의 가치도 바로 그 지점에 있다.
LoRA를 작게 만드는 것이 아니라, 작은 LoRA를 대규모 서비스 상태 안에서 안전하게 움직일 수 있게 만드는 것이다.