최신 LLM이나 VLM을 볼 때 자주 생기는 착시는, 모델 이름만 바뀌었을 뿐 내부 설계는 대충 비슷할 것이라는 생각이다.
하지만 실제로는 어떤 normalization을 쓰는지, FFN 활성화를 어떻게 바꾸는지, 위치 인코딩을 어떤 방식으로 확장하는지, attention 메모리 병목을 어디서 줄이는지 같은 선택이 학습 안정성·긴 컨텍스트 처리·추론 비용을 갈라놓는다.
모델 카드나 논문을 하나씩 읽다 보면 이 결정들이 흩어져 보이기 쉽다.
ldj7672.github.io의 “Large-scale Model 핵심 기술: Architecture, Norm, Positional Encoding” 페이지는 바로 이 흩어진 선택지를 하나의 설계 지도처럼 다시 정리하려는 글이다.
이 페이지는 새로운 방법을 제안하는 원논문이라기보다, 최신 대규모 모델에서 사실상 표준이 된 조합을 Architecture & Norm, Positional Encoding, Attention 세 축으로 묶어 설명한다.
특히 decoder-only 구조에서 RMSNorm, SwiGLU, Pre-Norm, RoPE, FlashAttention, GQA가 왜 함께 자주 등장하는지 한 번에 복기하게 해준다는 점에서 실무자용 테크 리포트에 가깝다.
무엇을 해결하려는가
이 글이 겨냥하는 문제는 “기술 이름은 아는데 서로 어떻게 연결되는지 모르겠다”는 상태다.
최근 모델 설명을 보면 Qwen, Gemma, Llama, GLM 같은 계열마다 개별 용어는 익숙하지만, 그것이 결국 어떤 공통 설계 패턴으로 수렴하는지는 따로 정리되어 있지 않은 경우가 많다.
학습 안정성을 위한 norm 위치, FFN 표현력과 gradient flow를 위한 activation, long-context를 위한 positional encoding, 그리고 실제 serving 병목을 줄이는 attention 최적화가 서로 다른 층위의 이야기처럼 분리되어 소비되기 쉽다.
이 페이지는 그 층위를 다시 한 모델의 생애주기로 합친다.
먼저 decoder-only Transformer와 Pre-Norm 블록 구조를 기초로 놓고, 그 위에 RMSNorm과 SwiGLU 같은 학습 안정화 선택을 올린다.
이어서 RoPE와 mRoPE를 통해 텍스트 및 멀티모달 위치 정보를 어떻게 다루는지 설명하고, 마지막으로 FlashAttention과 GQA/MQA를 통해 메모리·속도 병목이 어떻게 완화되는지 연결한다.
즉 “모델 구조를 이해하는 일”과 “실제 훈련·서빙에서 어떤 선택이 살아남았는지 이해하는 일”을 한 문맥으로 묶는 것이 이 글의 목적이다.
핵심 아이디어 / 구조 / 동작 방식
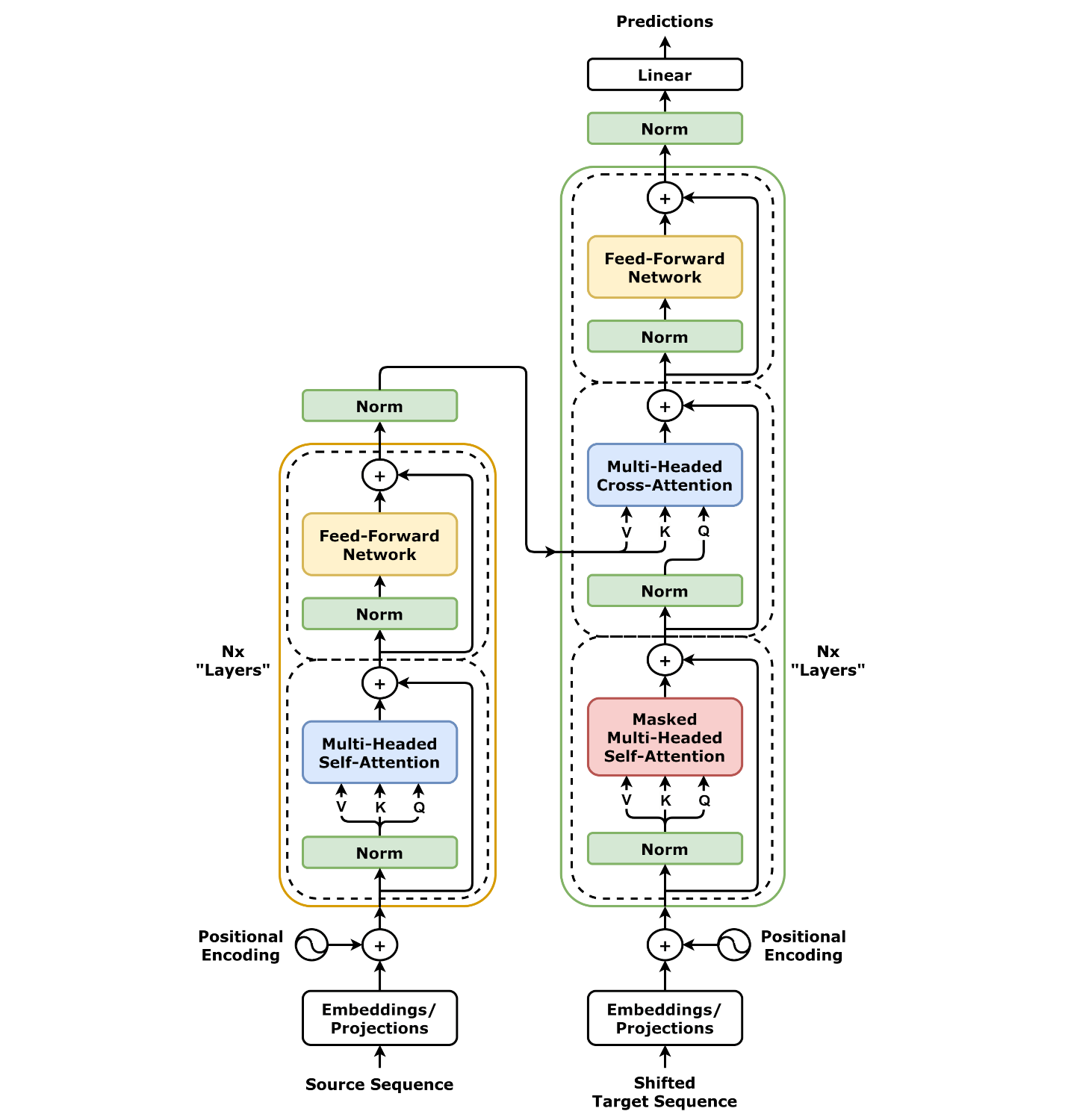
가장 먼저 이 리포트가 강조하는 것은 최신 대규모 모델의 기본 골격이 여전히 decoder-only Transformer라는 점이다.
입력 토큰은 embedding과 positional encoding을 거쳐 여러 개의 decoder block을 통과하고, 마지막 layer norm과 LM head를 지나 다음 토큰 logits로 변환된다.
여기서 중요한 것은 단순한 구조 소개가 아니라, 이 표준 구조 안에서 어떤 세부 선택이 표준으로 굳어졌는지를 순서대로 보여준다는 점이다.
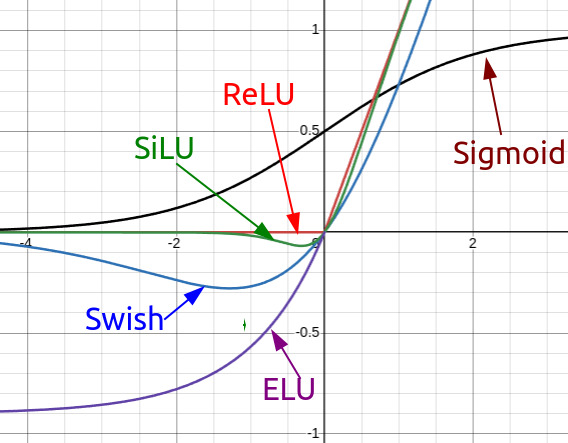
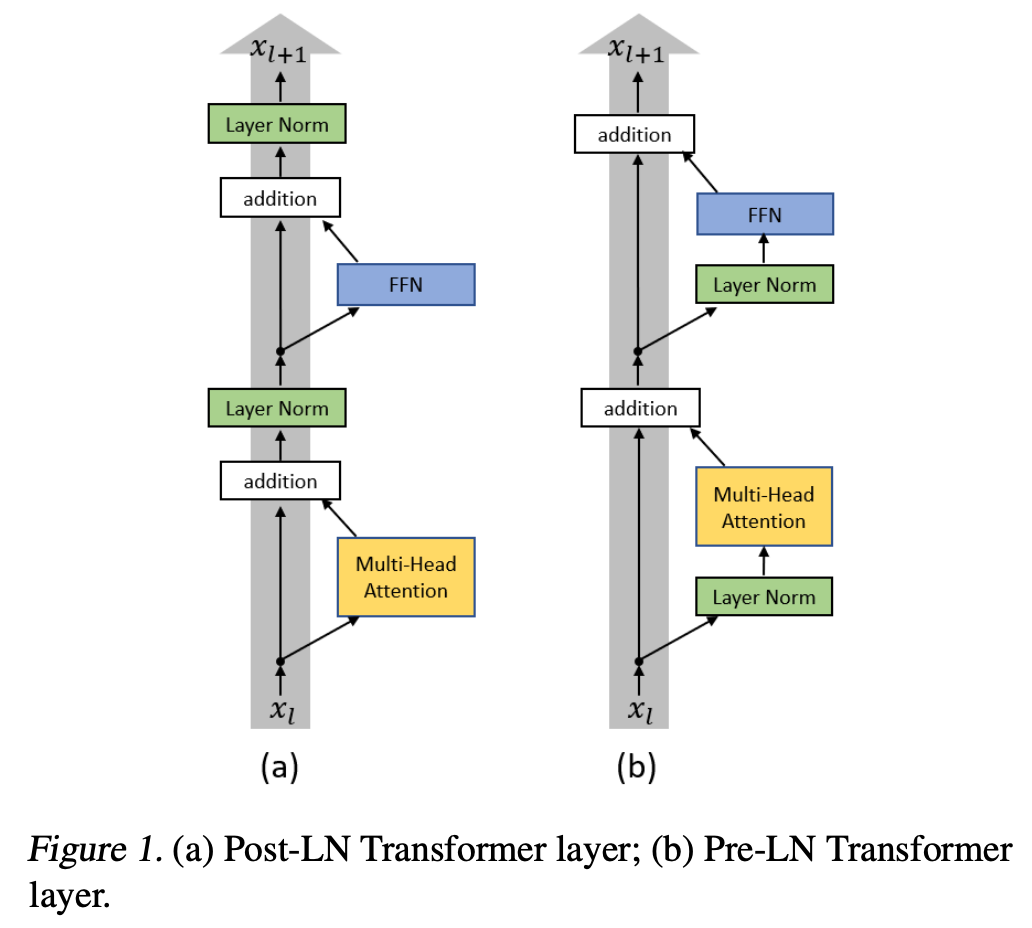
정규화와 FFN 파트에서는 LayerNorm 대비 RMSNorm, ReLU/GELU 대비 SwiGLU, Post-Norm 대비 Pre-Norm이 왜 더 자주 채택되는지 설명한다.
이 리포트의 논지는 명확하다.
최신 계열이 RMSNorm을 선호하는 이유는 평균 제거를 생략해 연산량과 메모리 부담을 줄이면서도 대규모 모델에서 충분한 안정성을 확보하기 쉽기 때문이고, SwiGLU는 gate 구조를 통해 FFN의 표현력을 높이면서 gradient 흐름도 더 부드럽게 만든다.
또한 Pre-Norm은 깊은 네트워크에서 gradient vanishing/exploding 문제를 줄이기 때문에 GPT-2 이후 세대에서 사실상 표준으로 자리 잡았다는 식으로 연결된다.
위치 인코딩 파트에서는 RoPE를 단순히 “요즘 많이 쓰는 positional encoding”이라고 넘기지 않고, 상대적 위치 관계를 보존한다는 점을 핵심으로 잡는다.
절대 위치 임베딩이 긴 컨텍스트 extrapolation에 약한 반면, RoPE는 query와 key를 회전시켜 상대 거리 정보를 attention score에 직접 남긴다.
여기에 더해 Qwen2-VL, Qwen3-VL 계열에서 중요한 mRoPE와 Interleaved-MRoPE를 소개하면서, 텍스트 전용 LLM 설계가 멀티모달 확장으로 어떻게 이어지는지도 짚는다.
이 부분은 단순한 수학 요약을 넘어서, 왜 VLM이 시간·높이·너비 축을 함께 다뤄야 하는지 감각적으로 연결해 준다는 점이 좋다.
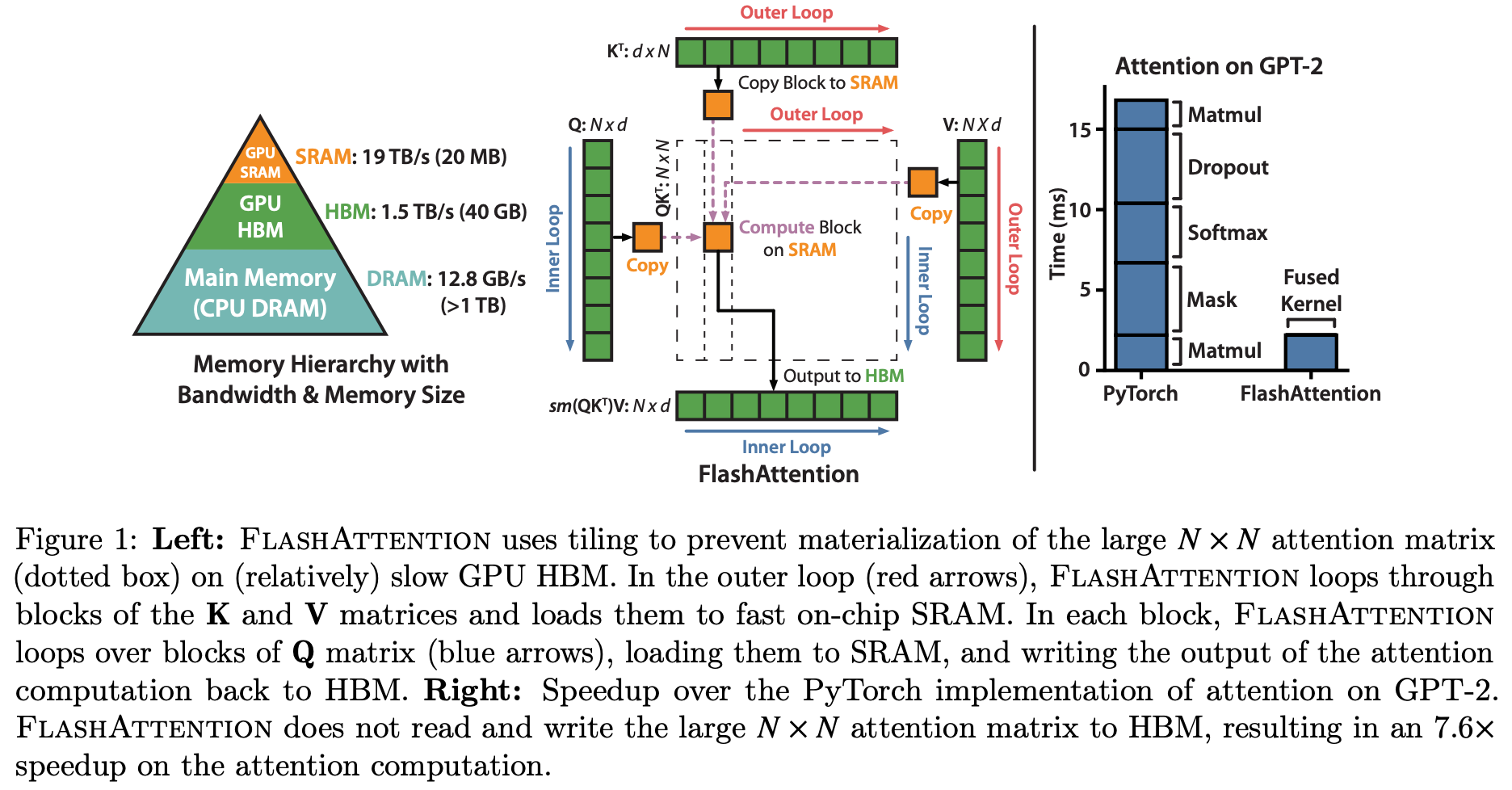
attention 파트의 핵심은 “정확한 attention을 유지하면서 메모리 병목을 줄이는 방법”이다.
FlashAttention은 QK^T 전체를 메모리에 올려두는 대신 tiling, recomputation, online softmax를 활용해 O(N^2) 메모리 부담을 O(N) 수준으로 낮춘다.
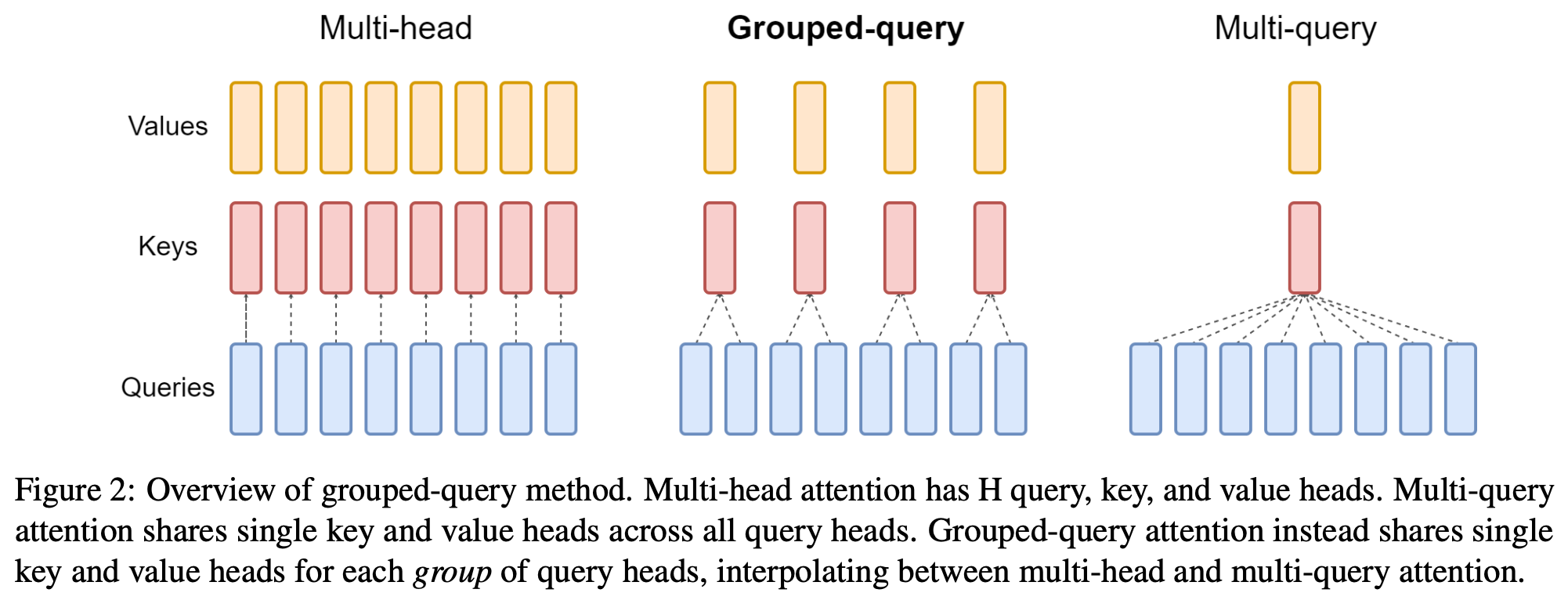
이어서 GQA와 MQA는 KV cache 메모리 문제를 해결하기 위해 key/value 공유 범위를 조정하는 방식으로 소개된다.
이 리포트는 MHA, GQA, MQA를 단순 정의 비교가 아니라 “표현력과 메모리 효율성 사이의 trade-off”로 배열해, 왜 최신 모델들이 GQA를 선호하는지 실전적인 시각으로 설명한다.
| 설계 축 | 이 리포트가 묶는 핵심 선택 | 실무적으로 중요한 이유 |
|---|---|---|
| Architecture & Norm | Decoder-only, RMSNorm, SwiGLU, Pre-Norm | 깊은 모델 학습 안정성, FFN 표현력, 연산 효율을 동시에 좌우함 |
| Positional Encoding | RoPE, mRoPE, Interleaved-MRoPE | long context와 멀티모달 입력에서 위치 정보를 어떻게 보존할지 결정함 |
| Attention Optimization | FlashAttention, GQA, MQA | 긴 시퀀스에서 메모리 IO와 KV cache 비용을 줄여 실제 serving 가능성을 높임 |
공개된 근거에서 확인되는 점
이 글에서 직접 확인되는 가장 중요한 사실은, 그것이 단일 모델 홍보 문서가 아니라 여러 원 논문과 실제 채택 사례를 엮은 정리형 리포트라는 점이다.
페이지는 2025년 12월 16일에 게시되었고, Architecture & Norm, Positional Encoding, Attention이라는 세 축으로 내용을 분리한다.
또한 참고 자료로 Transformer, RMSNorm, SwiGLU, Pre-Norm, RoPE, FlashAttention, GQA 원 논문을 명시해 두고 있어, 설명의 계보를 역추적하기 쉽다.
구체적으로 페이지는 RMSNorm이 평균 제거를 생략해 LayerNorm보다 계산량이 적고, 대규모 모델에서 약 10~15% 수준의 속도 이점을 줄 수 있다고 서술한다.
GQA 파트에서는 32 head, head dimension 128, sequence length 32K라는 예시를 두고 MHA가 약 268MB, MQA가 약 8.4MB, GQA가 8 KV head 기준 약 67MB의 FP16 KV-cache 메모리를 쓴다고 정리한다.
즉 이 글은 추상적인 개념 소개에 그치지 않고, 메모리·속도 관점에서 왜 이런 선택이 실제 시스템에 중요한지 수치 예시까지 포함해 설명한다.
또 하나 눈에 띄는 점은 멀티모달 확장까지 한 번에 다룬다는 것이다.
RoPE 설명 뒤에 바로 mRoPE, 그리고 Qwen3-VL의 Interleaved-MRoPE를 이어 붙이며, 텍스트 LLM의 위치 인코딩 논리를 이미지·비디오로 확장하는 흐름을 보여준다.
FlashAttention도 v1, v2, v3의 차이를 간단히 나눠 설명하고, GQA는 MHA와 MQA 사이의 절충안으로 배치한다.
교육용 글이지만, 선택의 맥락을 모델 운영 문제와 연결한다는 점이 강점이다.
| 항목 | 페이지에서 확인되는 내용 | 의미 |
|---|---|---|
| 게시 시점 | 2025-12-16 | 비교적 최근 시점의 LLM/VLM 기본 설계 정리 |
| 범위 | Architecture & Norm / Positional Encoding / Attention | 모델 구조·학습 안정성·서빙 효율을 한 문맥으로 묶음 |
| 포함 기술 | RMSNorm, SwiGLU, Pre-Norm, RoPE, mRoPE, FlashAttention, GQA, MQA | 최신 LLM/VLM에서 자주 등장하는 핵심 선택지 압축 |
| 근거 방식 | 원 논문 목록과 수식·도식·메모리 예시 포함 | 단순 의견글이 아니라 참고 가능한 기술 요약 문서에 가까움 |
실무 관점에서의 해석
내가 보기에 이 페이지의 가장 큰 장점은 “새로운 주장”보다 “좋은 압축”에 있다.
LLM 관련 문서를 계속 읽는 사람도 RMSNorm, RoPE, FlashAttention, GQA를 각각 다른 논문과 다른 구현 저장소에서 따로 접하는 경우가 많다.
그런데 실제 모델을 이해하거나, 새 모델 카드의 스펙을 읽거나, inference stack을 설계할 때는 이 네 가지가 분리된 지식으로 남아 있으면 별 도움이 되지 않는다.
결국 중요한 것은 “왜 이 조합이 오늘의 표준이 되었는가”인데, 이 페이지는 그 질문에 꽤 잘 답한다.
특히 팀 단위 학습 자료로 쓰기 좋다.
새로 합류한 엔지니어나 리서처에게 논문 여섯 편을 바로 던지기보다, 먼저 이 정도 밀도의 리포트로 구조를 잡고 나서 각 원 논문으로 내려가는 방식이 훨씬 효율적일 수 있다.
모델 구조를 처음 정리하는 사람에게는 decoder-only → RMSNorm/SwiGLU/Pre-Norm → RoPE/mRoPE → FlashAttention/GQA라는 순서 자체가 좋은 mental model이 된다.
물론 한계도 분명하다.
이 글은 본질적으로 정리 문서이기 때문에, 각 기법의 최신 변형이나 구현 디테일까지 모두 담지는 않는다.
예를 들어 long-context extrapolation 보정 기법, FlashAttention의 하드웨어별 차이, GQA uptraining의 실제 적용 난이도, VLM별 mRoPE 세부 구현 차이 등은 각 원 논문과 최신 코드베이스를 다시 봐야 한다.
따라서 이 페이지는 최종 레퍼런스라기보다, 최신 대규모 모델 스택을 빠르게 재정렬하는 입구 문서로 읽는 것이 맞다.
그럼에도 이 글은 “모델이 왜 이렇게 생겼는가”를 설명하는 요약본으로서는 충분히 가치가 있다.
특히 요즘처럼 모델 아키텍처, 멀티모달 확장, long-context inference 최적화가 한 번에 얽히는 시점에는, 이런 형태의 구조화된 기술 리포트가 생각보다 훨씬 실용적이다.
제품 팀이든 연구 팀이든, 새로운 모델을 해석하고 비교하는 기준선을 세울 때 좋은 출발점이 될 만하다.