최근 멀티모달 모델 경쟁에서 중요한 갈림길은 “모든 모달리티를 한 모델에 넣을 수 있는가”보다 “그 통합이 실제로 네이티브한가”에 가깝다. 텍스트 이해와 이미지 생성, 음성 입출력, 비디오 이해를 하나의 제품 경험으로 묶고 싶어도, 많은 시스템은 결국 오토리그레시브 LLM 위에 외부 디퓨전 생성기나 TTS·ASR 모듈을 이어 붙이는 식으로 확장된다. 이런 조합형 설계는 성능은 강할 수 있지만, 학습 목표와 디코딩 경로가 서로 다른 모듈들로 쪼개지기 쉽다.
Dynin-Omni는 이 문제에 대해 꽤 선명한 대답을 내놓는다. 서울대 AIDAS Lab이 공개한 이 모델은 텍스트, 이미지, 음성의 이해와 생성, 그리고 비디오 이해를 단일 아키텍처에 넣은 8B 규모의 masked diffusion 기반 옴니모달 모델이다. 핵심은 모든 모달리티를 shared discrete token space에 매핑하고, 오토리그레시브 left-to-right decoding 대신 iterative masked denoising으로 처리한다는 점이다. 즉 옴니모달을 “여러 특화 생성기를 조립한 시스템”이 아니라, 한 백본 안에서 어떤 모달이든 token refinement로 다루는 문제로 재정의한다.
무엇을 해결하려는가
Dynin-Omni가 겨냥하는 병목은 현재 통합 멀티모달 시스템의 구조적 불균형이다. 오토리그레시브 기반 통합 모델은 텍스트에는 강하지만, 이미지나 음성처럼 본질적으로 비순차적이거나 병렬 refinement가 유리한 모달리티까지 동일한 left-to-right 생성 규칙으로 직렬화해야 한다. 반대로 생성 품질을 높이기 위해 외부 diffusion 또는 flow 모듈을 붙이면, 이번에는 하나의 범용 백본이 아니라 여러 생성기와 오케스트레이션 계층을 관리해야 한다.
논문은 이 지점을 꽤 직접적으로 비판한다. AR unified model은 heterogeneous modality를 억지로 하나의 causal 순서에 집어넣고, compositional unified model은 modality-specific generator에 많은 부분을 위임한다. 그 결과 cross-modal interaction은 중간 표현이나 도구 호출에 의존하게 되고, 진짜 의미의 단일 백본 통합은 어렵다. 게다가 이런 시스템은 멀티모달 범위가 넓어질수록 reasoning strength를 유지하기도 쉽지 않다.
Dynin-Omni는 여기서 masked diffusion을 택한다. 이미지나 음성처럼 전역적 일관성과 병렬 보정이 중요한 모달리티는 순차 생성보다 iterative denoising이 더 자연스럽다는 판단이다. 따라서 이 모델이 해결하려는 핵심은 단순한 멀티모달 확장이 아니라, 옴니모달 이해·생성을 하나의 생성 원리와 하나의 백본으로 통합할 수 있는가다.
핵심 아이디어 / 구조 / 동작 방식
Dynin-Omni의 구조는 크게 세 층으로 읽을 수 있다.
첫째는 shared discrete token space다. 텍스트, 이미지, 음성, 비디오를 모두 하나의 이산 토큰 공간으로 투영하고, 단일 Transformer 백본이 이를 처리한다. 이 덕분에 텍스트 생성, 이미지 생성, 이미지 편집, 음성 합성, 음성 인식, 비디오 이해를 서로 다른 디코더 조합이 아니라 하나의 token prediction 문제로 묶을 수 있다.
둘째는 masked diffusion decoding이다. 이 모델은 autoregressive next-token prediction 대신, 마스크된 토큰을 반복적으로 복원하는 방식으로 생성한다. 논문과 프로젝트 페이지 표현을 빌리면 이는 confidence-based refinement와 bidirectional token modeling에 가깝다. 즉 과거 토큰만 보는 causal decoding이 아니라, 남아 있는 문맥 전체를 보면서 여러 토큰을 병렬적으로 다듬는 경로를 택한다.
셋째는 multi-stage training이다. GitHub README 기준 학습은 세 단계로 정리된다.
- Stage 1: video와 speech를 기존 diffusion backbone에 적응시키는 omni-modal pretraining
- Stage 2: model merging을 동반한 omni-modal supervised fine-tuning
- Stage 3: context extension, 고해상도 이미지, 긴 음성 생성, thinking-mode control, chain-of-thought supervision 등을 포함한 continual scaling
논문은 이 과정을 조금 더 개념적으로 설명한다. 먼저 modality expansion을 하고, 그 다음 modality-disentangled model merging으로 기존 semantic consistency를 보존하면서 vocabulary capacity를 확장하고, 마지막으로 reasoning과 generation capability를 키운다는 식이다. 즉 새 모달리티를 한 번에 joint training으로 우겨 넣기보다, 확장과 능력 스케일링을 분리한다는 설계 철학이 분명하다.
이 모델이 특히 흥미로운 이유는 “진짜 옴니모달”의 범위를 꽤 넓게 잡았기 때문이다. arXiv abstract와 프로젝트 페이지를 종합하면 지원 범위는 다음과 같다.
| 축 | 지원 범위 | 공개 자료에서 보이는 방식 |
|---|---|---|
| 이해 | 텍스트, 이미지, 비디오, 음성 | reasoning, VQA/MMU, video QA, ASR |
| 생성 | 텍스트, 이미지, 음성 | text generation, T2I, image editing, TTS |
| 생성 원리 | masked diffusion | iterative masked denoising, bidirectional context |
| 통합 방식 | 단일 백본 + shared discrete token space | 외부 modality-specific generative expert 최소화 |
| 규모 | 8B-scale | 논문·README·HF 모델 카드 모두 8B 계열로 설명 |
공개된 근거에서 확인되는 점
가장 먼저 확인되는 사실은 Dynin-Omni가 단순 프로젝트 페이지 수준에서 멈춘 릴리스는 아니라는 점이다. arXiv 논문, GitHub 저장소, Hugging Face 모델 카드, 그리고 Space 데모까지 연결된 공개 패키지를 갖추고 있다. Hugging Face API 기준 모델 저장소는 2026-02-21에 생성됐고, 마지막 수정 시각은 2026-04-13T11:53:15Z다. 다운로드는 9,905회, likes는 19개로 표시된다. GitHub 저장소는 2026-03-09 생성, stars 44, forks 4이며 MIT 라이선스다.
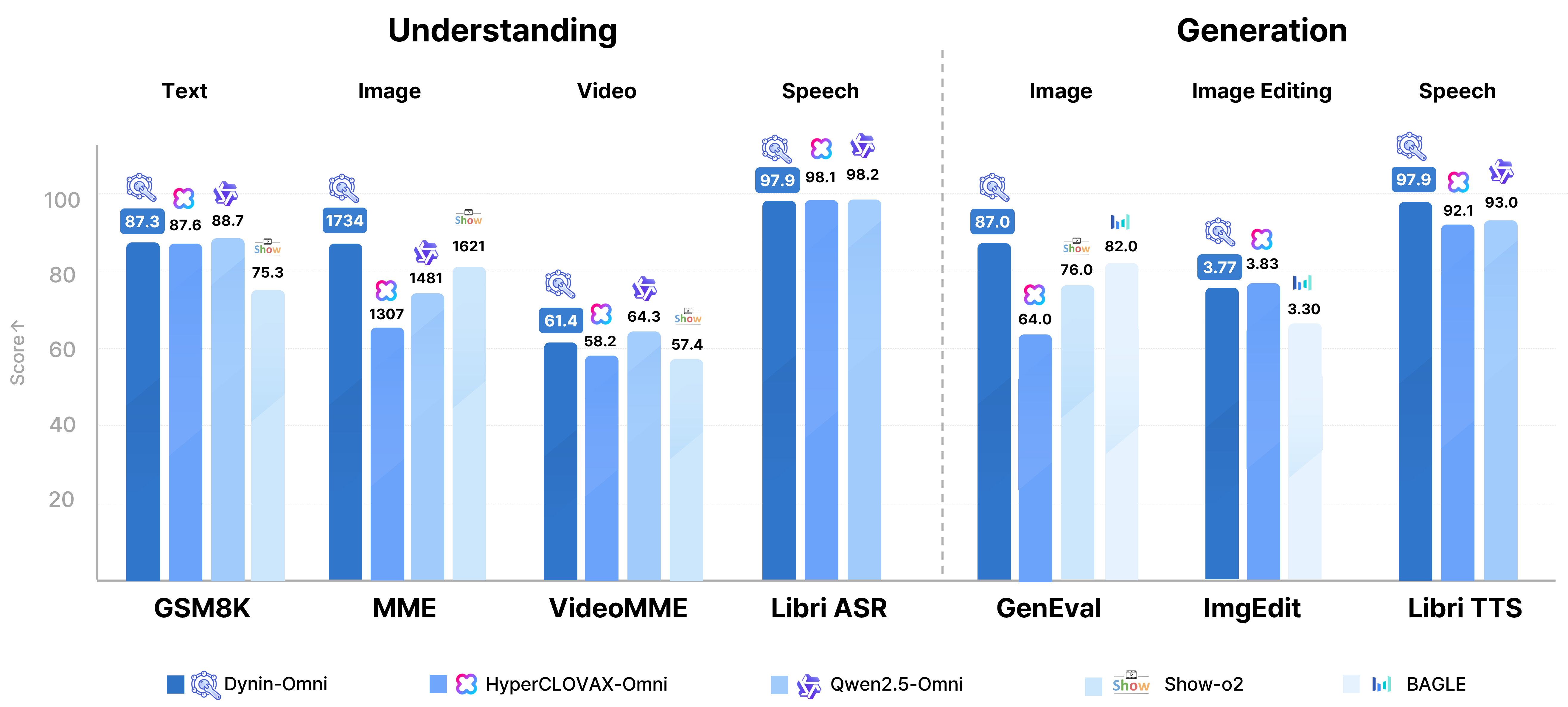
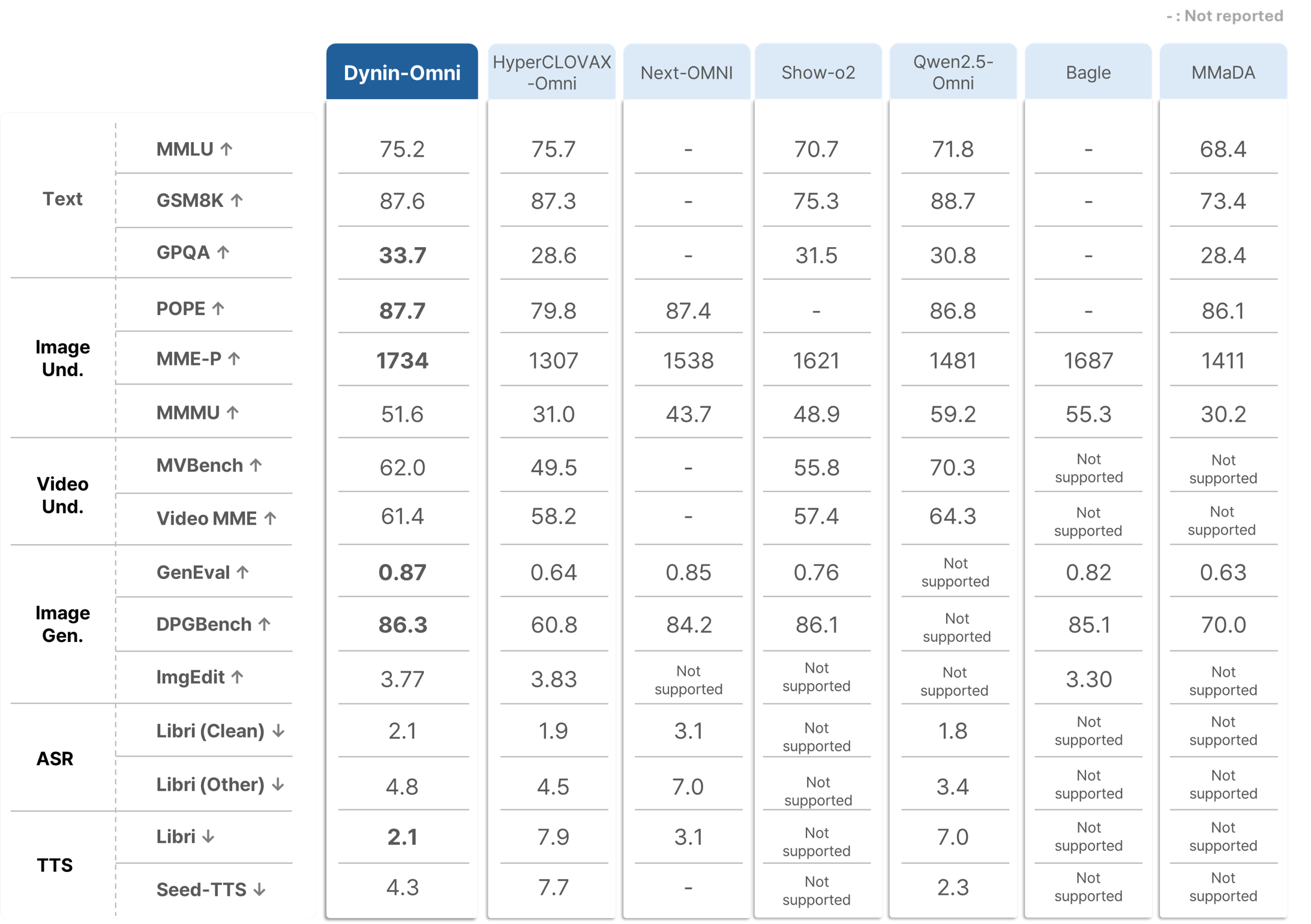
성능 수치도 꽤 구체적이다. arXiv abstract는 Dynin-Omni가 19개 벤치마크에서 평가됐으며, 대표 수치로 GSM8K 87.6, MME-P 1733.6, VideoMME 61.4, GenEval 0.87, LibriSpeech test-clean 2.1 WER를 제시한다. 또 논문 본문은 기존 unified model 대비 최대 +6.2% reasoning, +10.1% video understanding 개선을 언급한다. 프로젝트 페이지도 이 서사를 이어 받아 “existing open-source unified model 대비 우세하고 modality-specific expert와도 경쟁 가능하다”는 포지션을 취한다.
여기서 중요한 것은 Dynin-Omni가 모든 축에서 절대 최고를 주장하기보다, 이해와 생성을 함께 묶은 단일 diffusion 백본으로 이 정도 범위를 커버한다는 점이다. 예컨대 프로젝트 페이지는 textual reasoning, image understanding, video understanding, image generation, image editing, ASR/TTS 예시를 나란히 보여준다. 즉 벤치마크 수치뿐 아니라 capability surface 자체가 넓다는 점이 이 릴리스의 핵심 근거다.
운영 측면의 신호도 읽힌다. GitHub README에는 direct local inference/training 가이드를 제공하지만, 동시에 dInfer 통합 진행 중, sglang 통합 예정, 그리고 vLLM-Omni PR이 0.19.0에 포함될 예정이라고 적혀 있다. 즉 “어디서나 이미 쉽게 굴러가는 범용 배포물”이라기보다, 런타임 생태계가 이제 막 붙기 시작한 연구-제품 사이 단계로 보는 편이 정확하다.
버전 성숙도도 보수적으로 읽을 필요가 있다. GitHub API 기준으로 tags는 비어 있고 /releases/latest는 404다. 논문과 모델, 코드, 데모는 모두 공개됐지만, 전통적인 의미의 안정 릴리스 태그나 패키지 버저닝은 아직 약하다는 뜻이다. 따라서 지금 시점의 Dynin-Omni는 “흥미로운 완성형 제품”보다는 “강한 공개 연구 시스템이 배포형 코드로 넘어가는 초기 단계”에 가깝다.
실무 관점에서의 해석
내가 보기에 Dynin-Omni의 가장 중요한 메시지는 옴니모달 통합을 오토리그레시브 LLM의 외연 확장으로 보지 않는다는 점이다. 많은 팀이 아직도 텍스트 LLM에 이미지 입력을 붙이고, 음성은 별도 codec/TTS 모듈로 빼며, 영상은 이해 전용 경로로 처리한다. Dynin-Omni는 이런 파이프라인 분절을 줄이기 위해 아예 생성 원리부터 masked diffusion으로 바꾼다.
이 선택은 특히 이미지 생성·편집과 음성 생성처럼 전역 일관성과 병렬 refinement가 중요한 작업에서 설득력이 있다. left-to-right causal decoding은 텍스트에는 자연스럽지만, 이미지나 음성 파형 수준의 전역 구조에는 다소 어색할 수 있다. Dynin-Omni가 iterative denoising을 전면에 둔 이유도 결국 여기에 있다. 옴니모달을 정말로 any-to-any 문제로 보려면, 모든 모달리티를 같은 causal 순서로 직렬화하는 것보다 전역적 정합성을 유지하는 생성 방식이 더 자연스럽다는 판단이다.
다만 현실적인 한계도 명확하다. 첫째, 현재 공개 자료는 강하지만 대부분 저자 측 공식 자료다. 벤치마크 표와 예시가 풍부하긴 해도, 제3자 재현과 대규모 운영 사례가 더 쌓여야 실제 상대적 위치를 확정적으로 말하기 쉽다. 둘째, GitHub 배포 상태를 보면 tags/release가 비어 있어 안정 버전 운영감은 아직 약하다. 셋째, vLLM-Omni·dInfer·sglang 통합 문구는 오히려 이 모델이 자체 추론 스택을 단순히 바로 붙이기 쉬운 타입은 아니라는 신호이기도 하다.
그럼에도 방향성은 분명하다. Dynin-Omni는 “통합 멀티모달”의 다음 단계가 단지 더 많은 입출력 인터페이스를 붙이는 것이 아니라, shared token space와 unified generation objective를 가진 네이티브 옴니모달 백본으로 가는 것임을 보여준다. 이 관점에서 Dynin-Omni는 단일 모델 성능 발표라기보다, diffusion language model 계열이 앞으로 텍스트를 넘어 어떤 범용 인터페이스를 노릴 수 있는지 보여주는 실험에 가깝다.