장애 대응에서 가장 위험한 상태는 “도구가 없는 상태”가 아니다.
로그도 있고, 대시보드도 있고, 알림도 있는데 정작 중요한 장애가 고객 제보로 먼저 발견되는 상태다.
이때 문제는 보통 특정 솔루션 하나가 빠졌다는 것보다, 무엇을 지표로 볼 것인지, 누가 대시보드를 만들 것인지, 어떤 알림을 행동으로 연결할 것인지, 저장소가 서비스 성장 속도를 따라갈 수 있는지가 함께 정리되지 않았다는 데 있다.
카카오페이의 if(kakao)2020 발표 메트릭 기반 모니터링 환경 구축 (feat. Prometheus)는 바로 이 지점을 다룬다.
발표는 Prometheus나 Thanos의 기능 소개로 시작하지 않는다.
코로나 시기 온라인 서비스 사용량이 늘고 장애가 증가한 상황, 100여 개 마이크로서비스와 다양한 런타임, 로그 기반 알림의 한계, 그리고 “평균 5분 이내 탐지”라는 운영 목표에서 출발한다.
그래서 이 발표의 핵심은 “Prometheus를 썼다”가 아니라, 서비스 신뢰성을 지표·대시보드·알림·온콜·저장소 확장이라는 하나의 루프로 묶어 가는 과정이다.
2020년 발표지만, 오늘날 OpenTelemetry, managed metrics, SLO platform을 쓰는 팀에도 여전히 유효한 운영 질문을 던진다.

무엇을 다루는 영상인가
영상은 kakao tech 채널에 올라온 if(kakao)2020 세션이다.
YouTube 설명 기준 제목은 메트릭 기반 모니터링 환경 구축 (feat. Prometheus), 발표자는 카카오페이 Software Developer 양원석 Joel이다.
설명에는 “확장 가능한 메트릭 저장소 구축과 장애 관리, 장애 대응 프로세스를 만들어가는 경험”을 공유한다고 되어 있다.
설명란에는 별도의 GitHub 저장소나 슬라이드 링크가 없었다.
따라서 이 글은 YouTube 메타데이터, 자동 한국어 자막, 영상 속 슬라이드 프레임, 그리고 Prometheus·Thanos 공식 문서를 함께 대조해 정리했다.
자동 자막에는 “알럿”, “Grafana”, “Thanos”, “OpenStack Swift”, “MinIO” 같은 기술 용어 오인식이 일부 있어, 영상 화면과 공식 용어를 기준으로 보정했다.
발표 당시 카카오페이는 송금·결제뿐 아니라 영수증, 청구서, 인증, 투자, 자산관리, 보험, 증권까지 다루는 금융 플랫폼으로 설명된다.
발표자는 가입자 3천만 명 이상, 월간 이용자 2천만 명, 300여 명의 개발자, 100여 개 마이크로서비스라는 규모를 언급한다.
Java/Kotlin과 Spring 기반 서비스가 주류지만 Scala, Node, Netty, gRPC, WebFlux 같은 다양한 런타임도 함께 존재했다.
이런 환경에서 기존 모니터링은 기본 구성은 갖추고 있었다.
로그는 ELK stack, 수집은 Filebeat와 Logstash, 검색과 대시보드는 Kibana를 사용했다.
메트릭과 분산 트레이싱 쪽에는 카카오 내부의 Neo를 사용했고, 예외 알림은 Sentry와 메신저를 통해 전달하는 구조였다.
문제는 “있다”와 “잘 작동한다”가 다르다는 데 있었다.
장애 리뷰를 해 보니 대시보드가 없는 서비스도 있었고, 로그 기반 대시보드는 트래픽 증가와 함께 느려졌다.
기본 메트릭만으로는 서비스 상태를 알기 어려웠고, 부정확한 알림은 점점 무시되었다.
또 Java agent 기반 수집은 Servlet 중심 정보에는 강했지만 Netty, gRPC, WebFlux처럼 늘어나는 비동기·비서블릿 계열 서비스에서는 누락이 생겼다.
첫 번째 전환: 로그로 사후 분석하기보다 메트릭으로 변화를 본다
발표자는 로그와 메트릭의 차이를 먼저 짚는다.
로그는 특정 이벤트가 발생했을 때 그 상황을 서술해 기록한다.
정확한 원인 분석에는 유용하지만, 정보를 만들기 위해 후처리와 검색 비용이 든다.
서비스 규모가 커질수록 로그 기반으로 “지금 상태가 어떤가”를 빠르게 계산하기 어려워진다.
반면 메트릭은 특정 시점의 상태를 숫자로 저장한다.
후처리 비용이 상대적으로 작고, 추세와 이상 변화를 빠르게 계산할 수 있다.
카카오페이가 메트릭 기반 모니터링으로 전환하려 한 이유도 여기에 있다.
스케일과 복잡도가 커지는 환경에서 빠르게 계산 가능한 지표가 필요했고, 장애가 고객에게 드러나기 전에 상황 변화를 먼저 포착하고 싶었다.
하지만 메트릭은 공짜가 아니다.
발표에서 가장 좋은 경고는 label cardinality 이야기다.
같은 metric name이라도 label을 붙이면 method, status, endpoint 같은 차원을 나눠 볼 수 있다.
문제는 label 조합이 폭발하면 Prometheus 자체가 병목이 된다는 점이다.
발표자는 특정 서비스에서 latency histogram을 적용하면서 200만 개의 label을 추가하게 되었고, 그 결과 Prometheus scrape timeout이 발생해 모니터링 전체에 영향을 준 장애가 있었다고 설명한다.
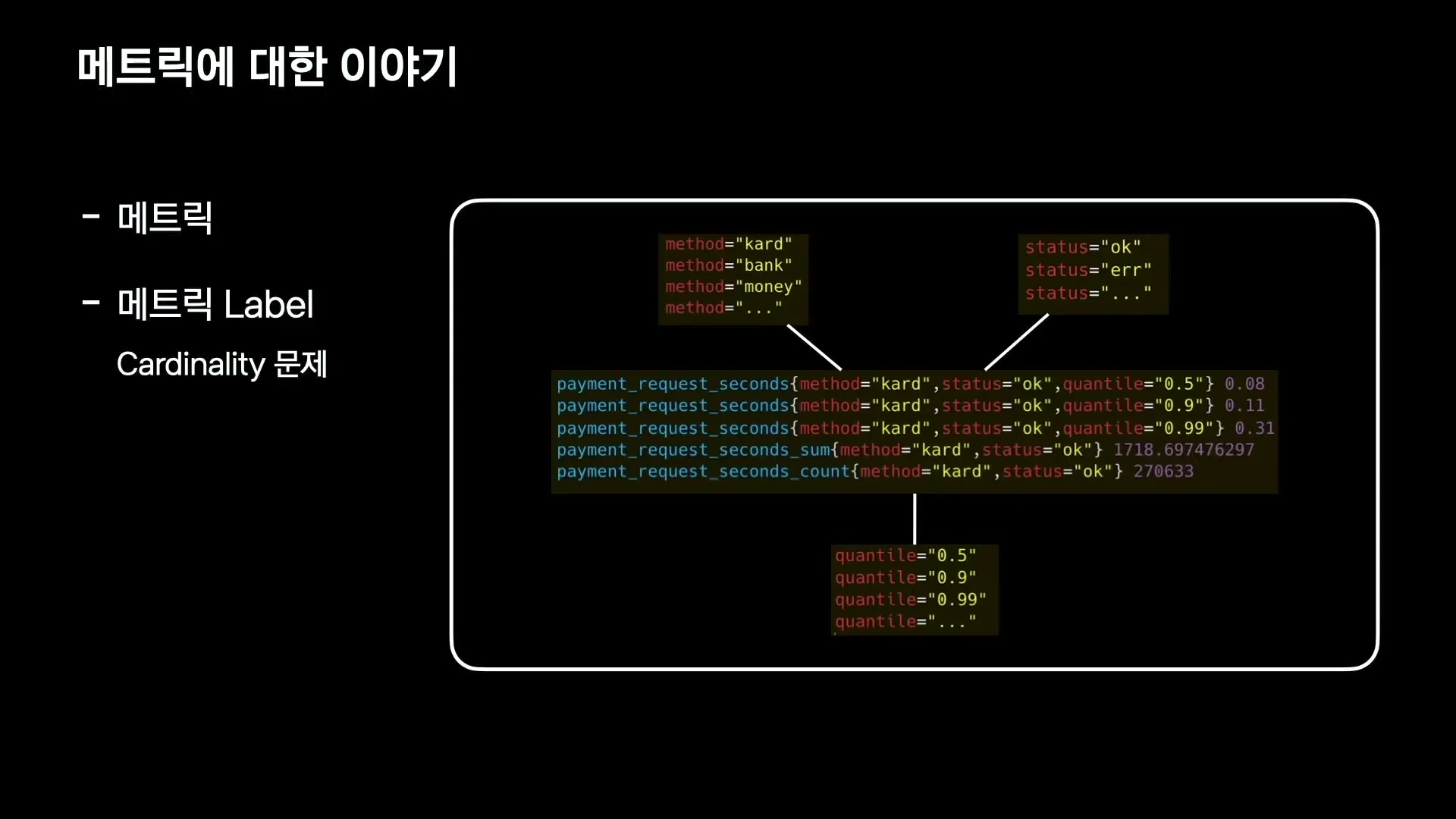
이 대목은 지금도 중요하다.
Observability 도구를 도입할 때 팀은 “무엇을 더 많이 수집할까”에 집중하기 쉽다.
그러나 실제 운영에서는 “어떤 label을 금지할 것인가”, “cardinality budget을 어떻게 볼 것인가”, “사용자 ID나 주문 ID처럼 무한히 늘어나는 값을 metric label로 넣지 못하게 막을 것인가”가 같은 무게로 중요하다.
무엇을 수집할 것인가: 고객 입장의 지표와 RED 방법론
메트릭을 수집하기로 했다고 해서 바로 좋은 모니터링이 만들어지지는 않는다.
발표자가 강조하는 다음 질문은 “어떤 메트릭을 수집할 것인가”다.
시스템 입장의 CPU, memory, thread, JVM 지표만 보면 고객 입장의 문제를 놓칠 수 있다.
마이크로서비스 환경에서는 각 담당 서비스가 정상이어도, 전체 사용자 여정에서는 장애가 발생할 수 있기 때문이다.
발표에서는 Netflix의 playback button 사례를 언급한다.
사용자는 영상이 나오지 않으면 재생 버튼을 다시 누른다.
이 행동 자체를 고객 입장의 지표로 보면, 개별 서버의 내부 상태가 아니라 실제 사용자가 경험하는 문제를 더 직접적으로 관찰할 수 있다.
카카오페이도 이런 비즈니스 메트릭을 시도하고 있다고 설명한다.
다만 모든 팀이 처음부터 완벽한 SLI/SLO 체계를 만들기는 어렵다.
발표자는 SLO/SLI 워크숍과 pair 작업도 해 봤지만, 제한된 리소스에서 우선순위가 오히려 더 어려워졌다고 말한다.
그래서 기본 출발점으로 선택한 것이 RED 방법론이다.
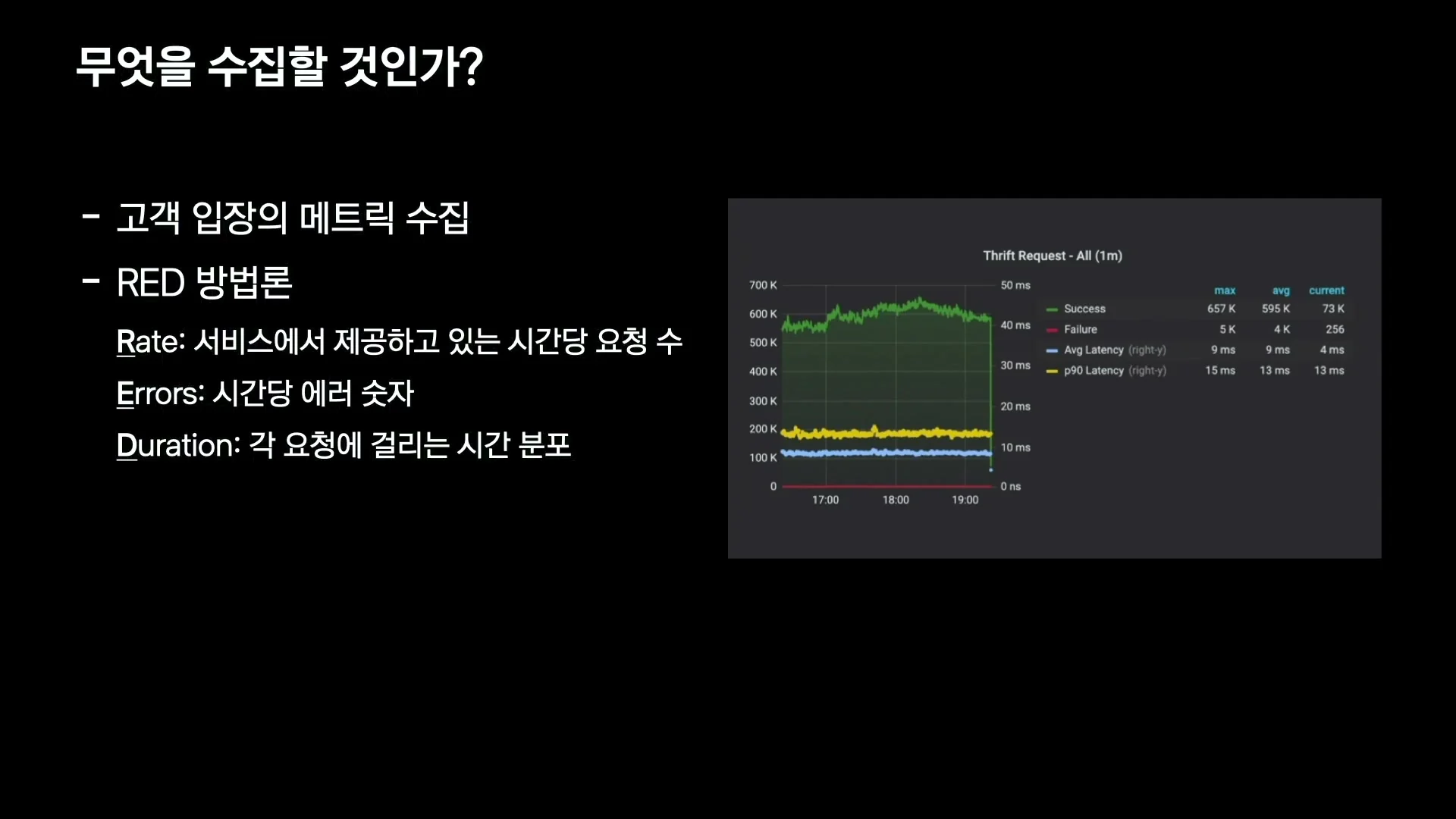
RED는 서비스가 제공하는 요청 수, 시간당 에러 수, 각 요청에 걸리는 시간 분포를 본다.
발표에서는 controller 단이 아니라 domain 단에서 이 지표들을 추가했고, 이를 기본으로 개발팀이 메트릭을 추가하는 방법까지 교육할 수 있었다고 설명한다.
완벽한 장애 탐지는 아니지만, 팀이 공통 언어를 갖고 시작하기에는 충분히 실용적인 기준이었다.
여기서 중요한 것은 “방법론을 정했다”가 아니라, 장애 리뷰를 통해 관련 메트릭을 추가·관리하는 루프를 만들었다는 점이다.
필요한 지표는 서비스와 장애 유형에 따라 계속 바뀐다.
따라서 메트릭 정의는 일회성 설계 문서가 아니라, 장애 리뷰와 운영 회고를 통해 계속 업데이트되는 산출물이어야 한다.
대시보드는 중앙에서 만들어 주는 화면이 아니라 팀이 학습하는 표면이다
수집한 메트릭은 보여야 한다.
발표 초반에는 공통 대시보드를 활용했지만, 각 팀을 만나 보니 대부분은 자기 서비스 전용 대시보드를 원했다.
100여 개 서비스가 동작하는 상황에서 중앙 조직이 100개의 대시보드를 직접 만들어 주는 것은 현실적이지 않았다.
흥미로운 해결책은 권한과 사례 공유였다.
Grafana 권한을 열어 다른 팀의 대시보드를 쉽게 볼 수 있게 했더니, 각 서비스 팀이 원하는 그래프를 직접 추가하기 시작했다.
처음에는 누군가 실수로 대시보드를 지울까 걱정했지만, 발표 기준으로는 그런 문제 없이 다른 대시보드를 참고해 자기 서비스 대시보드를 만드는 방향으로 흘러갔다고 한다.
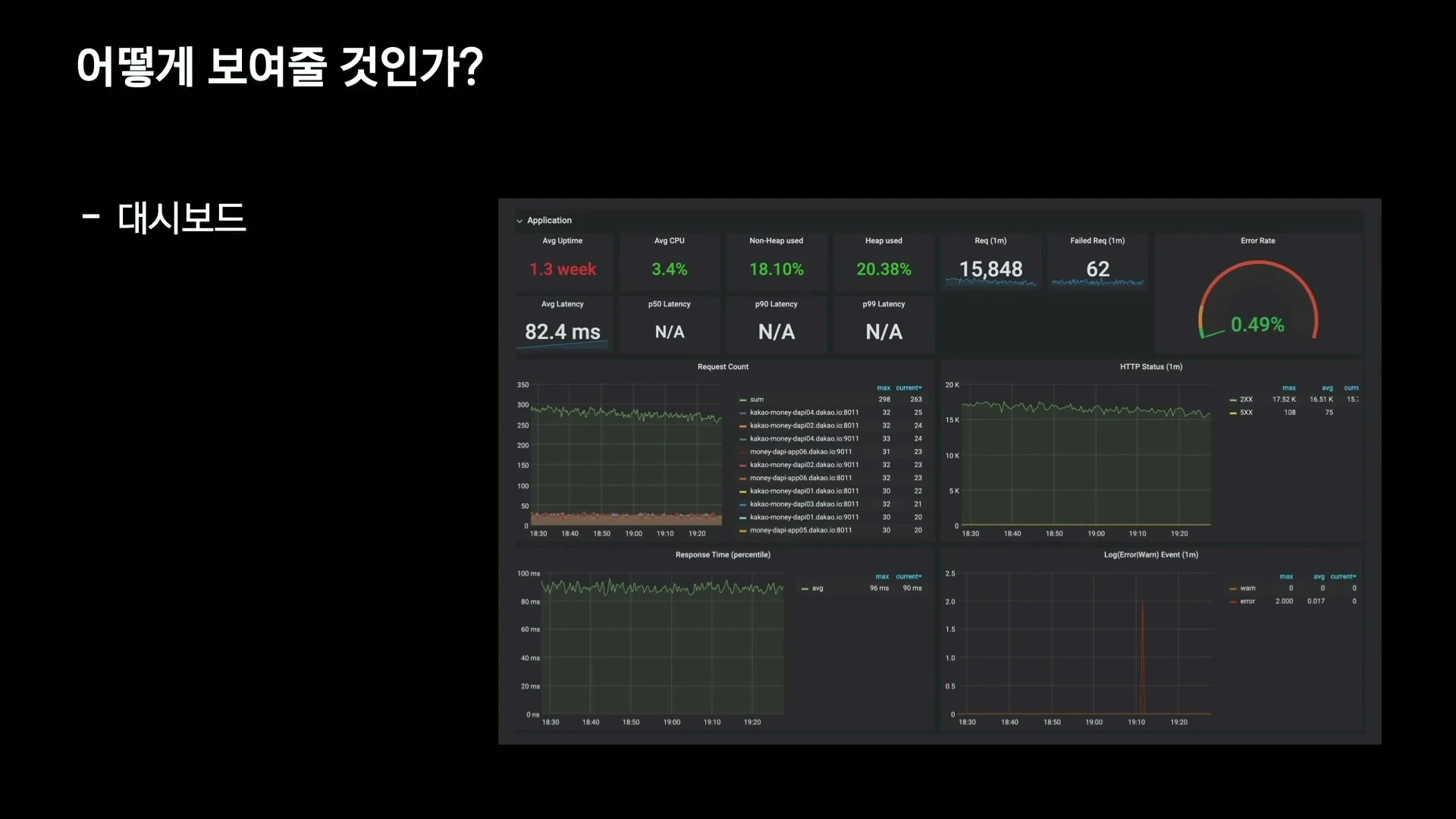
발표자는 분석용 대시보드와 모니터링용 대시보드를 분리하는 편이 효율적이었다고 말한다.
개발자 입장의 분석 대시보드는 원인 파악을 위해 다양한 정보를 보여줘야 한다.
반면 모니터링 조직이 보는 대시보드는 문제 발생 여부를 직관적으로 알 수 있어야 하므로, Grafana의 threshold와 색상을 적극 활용해 빠르게 이상을 인지하도록 구성했다.
이 차이는 작아 보이지만 실무적으로 크다.
하나의 대시보드가 모든 질문에 답하려 하면 화면은 복잡해지고, 장애 상황에서 볼 수 없는 대시보드가 된다.
반대로 모니터링용 화면은 “지금 깨졌는가”에 답하고, 분석용 화면은 “왜 깨졌는가”에 답하도록 나누면, 운영 중 인지 부하가 훨씬 줄어든다.
알림은 많이 만드는 것이 아니라 행동 가능한 신호로 남기는 것이다
좋은 alert를 만드는 일은 좋은 dashboard를 만드는 일보다 어렵다.
발표자는 안정을 얻기 위해 무수히 많은 alert를 만들게 되지만, 너무 많은 alert는 결국 보지 않는 alert가 된다고 말한다.
그래서 alert는 사용 대응지와 거짓 경보 여부를 계속 검토하고 관리해야 한다.
이 말은 지금의 SRE 원칙과도 맞닿아 있다.
알림은 “누군가 지금 일어나 행동해야 하는가”라는 질문에 답해야 한다.
로그 한 줄이나 metric threshold 하나가 흥미롭다고 해서 모두 paging alert가 되어서는 안 된다.
그렇지 않으면 알림은 시스템의 안전망이 아니라 운영자의 수면을 방해하는 노이즈가 된다.
발표의 목표는 평균 5분 이내 장애 탐지였다.
이를 위해 카카오페이는 monitoring 조직과 on-call 서비스를 도입했다.
Error level alert가 발생하면 해당 서비스의 on-call 담당자와 monitoring 조직으로 연락이 가고, 서비스 담당자는 문제 확인과 처리를 진행한다. monitoring 담당자는 필요한 정보 전달, 상황 전파, 필요 시 다른 서비스 담당자 연결을 맡는다.
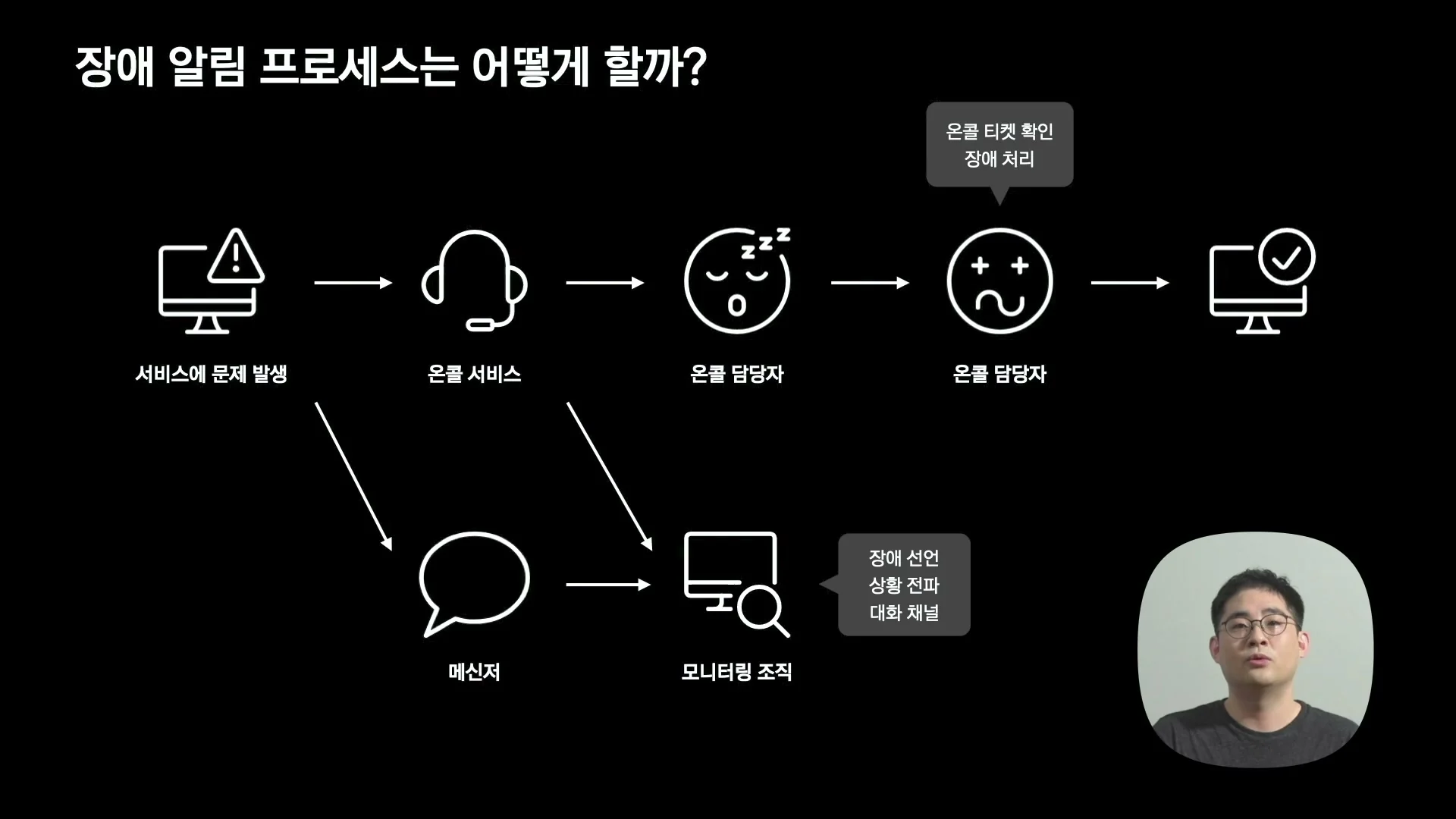
즉 이 발표에서 on-call은 단순히 “야간 담당자를 세웠다”는 의미가 아니다.
메트릭, 대시보드, alert가 실제 대응 주체와 연결되는 조직적 회로다.
그리고 그 회로는 장애 리뷰를 통해 다시 메트릭과 alert rule을 개선하는 피드백 루프로 돌아간다.
저장소 확장: Prometheus는 좋은 시작점이지만 클러스터링을 대신해 주지는 않는다
발표의 후반부는 메트릭 저장소 확장이다.
카카오페이는 메트릭 저장소로 Prometheus를 선택했다.
Graphite나 InfluxDB처럼 push 방식 저장소를 중앙에서 scale-out 하는 과정의 운영 비용이 크다고 판단했고, target이 노출한 endpoint를 Prometheus가 scrape하는 pull 방식이 더 확장에 유리하다고 본 것이다.
Prometheus 공식 문서가 설명하듯 Prometheus는 pull 기반으로 target을 scrape하고, metric name과 label로 식별되는 다차원 time series를 저장한다.
장애 상황에서 빠르게 진단할 수 있도록 독립적인 단일 서버로 동작하는 설계가 강점이다.
하지만 그 말은 동시에, Prometheus 자체가 자동으로 모든 scale-out과 clustering 문제를 해결해 주는 분산 저장소가 아니라는 뜻이기도 하다.
카카오페이도 이 문제를 만났다.
물리 장비와 Kubernetes가 공존하면서 target 정보를 찾고 수집하는 방식이 달랐고, target 수가 늘어나며 한 Prometheus가 모든 metric을 모으기 어려워졌다.
수집 timeout은 metric 누락으로 이어지고, 결국 모니터링 자체의 신뢰성을 떨어뜨린다.
해법은 zone 기준 partitioning과 Prometheus Federation이었다.
내부적으로 zone을 나눠 사용하고 있었기 때문에, 각 zone마다 Prometheus를 설치하고 그 zone의 target metric을 수집하게 만들었다.
그 위에서 상위 Prometheus가 필요한 metric을 federation으로 모아 전체 관점을 만든다.
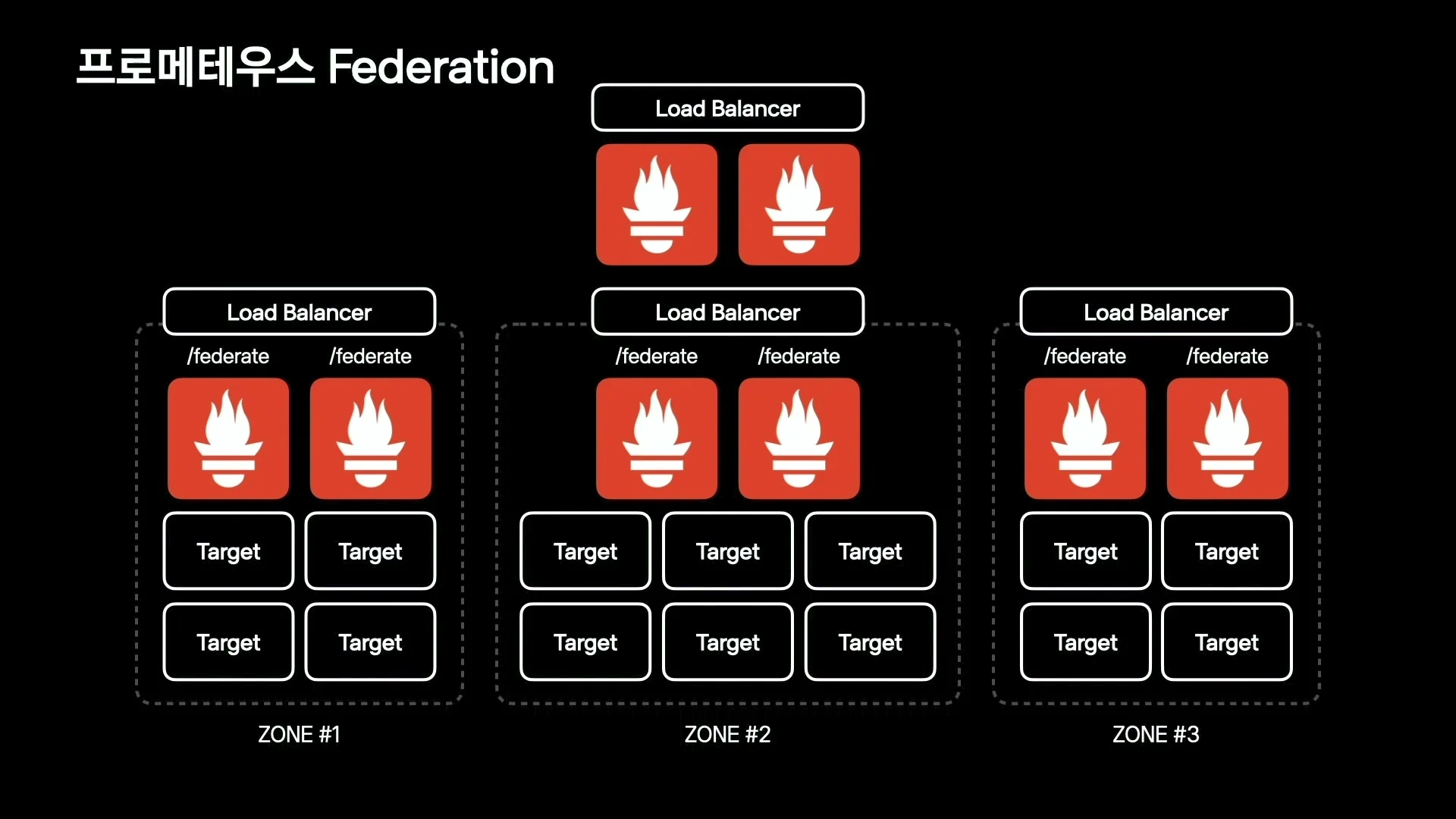
Prometheus 공식 문서에서도 federation은 한 Prometheus가 다른 Prometheus의 /federate endpoint에서 선택된 time series를 scrape하는 기능으로 설명된다.
대표 용도는 두 가지다.
하나는 여러 data center나 zone의 Prometheus를 tree 구조로 묶는 hierarchical federation이고, 다른 하나는 서비스별 Prometheus 사이에서 관련 metric을 가져오는 cross-service federation이다.
발표에서 카카오페이가 선택한 방식은 전자에 가깝다.
중요한 점은 federation이 “모든 metric을 중앙에 다 복제한다”는 의미가 아니라는 것이다.
상위 Prometheus는 global view에 필요한 aggregate 또는 selected series를 가져오고, 세부 drill-down은 local Prometheus에 남기는 방식이 더 자연스럽다.
이 구조를 잘못 설계하면 상위 Prometheus가 다시 병목이 된다.
Thanos는 장기 보관과 고가용성의 다음 단계다
Federation만으로 모든 문제가 해결되지는 않는다.
발표자는 Prometheus를 두 대로 늘리고 load balancer를 붙이는 방식도 가능하지만, Prometheus 특성상 시간에 따라 서로 다른 metric을 수집할 수 있고, reload 때마다 다른 graph를 보게 되는 문제가 생길 수 있다고 설명한다. sticky session이나 active-standby는 우회책일 수 있지만 근본 해결은 아니라고 본다.
그래서 다음 단계로 Thanos를 추가하기로 한다.
발표에서 Thanos를 선택한 이유는 세 가지로 정리된다.
첫째, 여러 Prometheus instance의 지표를 하나의 query layer에서 볼 수 있고 중복 metric 처리에 도움을 준다.
둘째, local disk 중심인 Prometheus 보관 기간 문제를 object storage로 확장할 수 있다.
셋째, 사용자는 Grafana endpoint를 바꾸는 정도로 접근할 수 있어 적용 부담이 상대적으로 작다.
Thanos 공식 문서도 같은 축을 강조한다.
Thanos는 Prometheus 위에서 long-term object storage, 여러 Prometheus instance에 대한 global querying, HA pair deduplication, historical querying, compaction·downsampling·retention 같은 기능을 제공한다.
구성 요소도 Sidecar, Store Gateway, Compactor, Receiver, Ruler, Querier, Query Frontend처럼 역할별로 나뉜다.
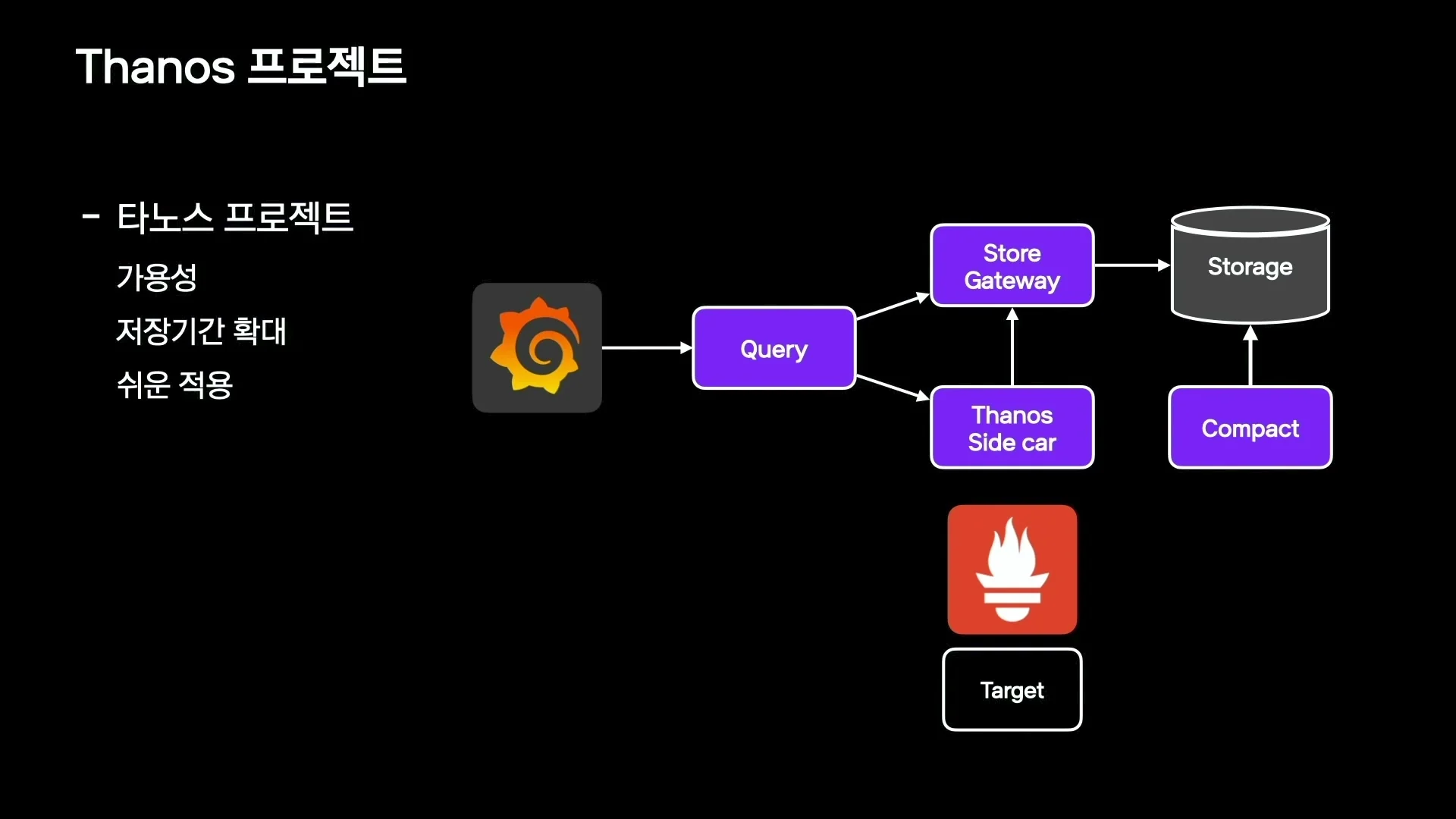
카카오페이의 특수한 제약도 흥미롭다.
주요 서비스가 IDC에서 운영되기 때문에 AWS S3 같은 외부 cloud storage를 그대로 쓰는 것은 비용 관점에서 비효율적이라고 판단했다.
그래서 Thanos storage로 IDC에서 사용할 수 있는 OpenStack Swift 호환 object storage를 쓰는 방안과, MinIO를 Kubernetes 환경에 설치하는 방안을 실험하고 있다고 설명한다.
발표자는 두 선택지 모두 성능보다는 운영 비용 관점에서 검토 중이며, 기능적으로는 충분히 활용 가능하다고 본다.
이 부분은 “기술 선택은 아키텍처 그림만으로 끝나지 않는다”는 사실을 잘 보여준다.
Thanos 자체는 object storage를 전제로 하지만, 어떤 object storage를 쓸지는 네트워크 위치, 비용, 운영 팀 역량, consistency 요구, 백업·복구 정책에 따라 달라진다.
특히 Thanos storage 문서는 object store 설정과 backend별 maturity를 별도로 다루며, object storage가 단순 파일 덤프가 아니라 운영 신뢰성의 핵심 의존성임을 전제한다.
타임라인으로 보는 핵심 구간
| 구간 | 내용 | 읽을 포인트 |
|---|---|---|
| 00:10–02:24 | 코로나 시기 장애 증가와 발표 목표 소개 | 안정성의 시작을 “중요 지표를 찾고 관찰하는 것”으로 둔다. |
| 02:24–06:08 | 카카오페이 서비스 규모와 기존 모니터링 환경 | ELK, Neo, Sentry 등 기본 구성은 있었지만 제보 기반 장애 발견, 느린 로그 대시보드, runtime 누락 문제가 드러난다. |
| 06:08–08:18 | 평균 5분 이내 장애 탐지 목표 | SRE 팀이 모든 장애를 자동 복구하기보다, 서비스 on-call 담당자에게 빠르게 연결하는 프로세스를 목표로 둔다. |
| 08:18–10:22 | 로그와 메트릭의 차이, label cardinality | metric은 빠른 trend 계산에 강하지만, label 폭발은 Prometheus scrape timeout을 만들 수 있다. |
| 10:22–13:21 | 고객 입장의 metric과 RED 방법론 | 시스템 지표만으로는 사용자 경험을 설명하기 어렵고, Rate·Errors·Duration을 domain 단위 기본 지표로 시작한다. |
| 13:21–16:53 | Grafana 대시보드와 alert 운영 | 공통 대시보드보다 팀별 대시보드 학습, 분석용/모니터링용 분리, actionable alert 관리가 중요해진다. |
| 16:53–18:07 | on-call과 monitoring 조직 프로세스 | alert가 담당자와 monitoring 조직으로 연결되고, 장애 리뷰가 다시 metric·alert 개선으로 이어진다. |
| 18:07–21:44 | Prometheus 저장소 확장과 federation | target 증가로 수집 timeout이 생기자 zone별 Prometheus와 hierarchical federation으로 partitioning한다. |
| 21:44–24:52 | Thanos 선택과 object storage 검토 | 고가용성, 장기 보관, 적용 편의성을 이유로 Thanos를 검토하고, OpenStack Swift·MinIO를 storage 후보로 본다. |
| 24:52–27:55 | 적용 현황과 결론 | 발표 기준 절반 정도 서비스에 metric/dashboard가 운영되고, 중요 서비스에는 alert/on-call 프로세스가 적용됐다. |
영상에서 확인되는 적용 현황
발표 말미에는 적용 현황도 나온다.
메트릭 기반 모니터링 체계 전환은 2020년 상반기에 시작해 발표 시점에도 진행 중인 프로젝트였다고 한다.
기존 모니터링에서 부족했던 metric을 확충하고, 장애 대응 커뮤니케이션도 메신저만의 흐름에서 monitoring 조직과 on-call 프로세스가 포함된 구조로 바꾸었다.
발표 기준으로는 약 절반의 서비스에 metric 수집과 dashboard가 만들어져 운영되고 있었다.
결제, 머니, 계정, 인증서 같은 중요 서비스에는 alert와 on-call 프로세스가 적용되었다.
전체 서비스 평균 탐지 시간 5분이라는 목표까지는 아직 갈 길이 있지만, metric 기반 모니터링이 적용된 서비스의 경우 탐지는 약 1.4분, 담당자 ack까지는 3분 이내라고 설명한다.

물론 이 숫자는 공개 영상에서 발표자가 설명한 적용 사례이며, 장기 추세나 전체 조직의 이후 운영 결과까지 검증해 주지는 않는다. false positive 비율, alert noise 변화, dashboard 유지 비용, Thanos 최종 도입 결과, OpenStack Swift와 MinIO 중 무엇을 선택했는지는 이 영상만으로 확인되지 않는다.
그럼에도 이 수치는 발표의 메시지를 잘 보여준다.
목표는 멋진 dashboard를 만드는 것이 아니라, 장애가 실제로 더 빨리 발견되고 담당자에게 연결되는 것이다.
모니터링 시스템의 성공 지표도 결국 “얼마나 많이 수집했는가”가 아니라 “어느 문제를 얼마나 빨리 발견하고 대응했는가”로 돌아와야 한다.
실무 관점에서의 해석
첫째, observability는 도구 설치가 아니라 운영 루프 설계다.
Prometheus, Grafana, Thanos, Sentry, ELK는 각각 유용하지만, 이들이 metric 정의, dashboard 소유권, alert 품질 관리, on-call, 장애 리뷰와 연결되지 않으면 장애 대응 능력으로 바뀌지 않는다.
발표가 좋은 이유는 도구보다 이 연결 방식을 보여준다는 데 있다.
둘째, metric은 “많을수록 좋다”가 아니다. label은 metric의 표현력을 높이지만 cardinality를 폭발시킨다.
특히 microservice와 domain metric이 늘어나는 조직에서는 metric naming, label policy, histogram bucket, high-cardinality field 금지, retention과 query cost 관리가 함께 가야 한다.
메트릭 시스템도 장애를 일으킬 수 있는 production system이다.
셋째, 대시보드는 조직 학습의 표면이다.
중앙 팀이 모든 서비스 대시보드를 대신 만들어 주는 방식은 scale하지 않는다.
반대로 좋은 예시를 볼 수 있게 열고, 팀이 자기 서비스에 맞는 화면을 만들게 하며, 장애 리뷰에서 다시 metric과 panel을 정리하면 대시보드는 살아 있는 운영 문서가 된다.
넷째, alert는 기술보다 계약에 가깝다.
누가 받는가, 언제 깨우는가, 무엇을 보고 판단하는가, 처리 후 어떤 리뷰로 돌아오는가가 정해져야 한다. alert rule 자체보다 이 계약이 약하면, 알림은 쌓이지만 신뢰는 떨어진다.
다섯째, Prometheus scaling은 단계적으로 봐야 한다.
처음부터 거대한 distributed metrics platform을 만들 필요는 없지만, target 수·label cardinality·retention·HA 요구가 커지는 순간 단일 Prometheus의 단순함은 한계가 된다.
이때 federation은 local detail과 global view를 나누는 한 방법이고, Thanos는 query 통합과 object storage 기반 장기 보관을 제공하는 다음 단계가 된다.
마지막으로, 이 발표의 현재적 의미는 “2020년에 어떤 도구를 썼나”보다 “성장하는 서비스가 모니터링을 어떻게 조직 운영 문제로 받아들이는가”에 있다.
오늘이라면 OpenTelemetry collector, managed Prometheus, Grafana Mimir, Cortex, cloud-native alerting, incident management SaaS 같은 선택지가 더 많다.
하지만 질문은 그대로다.
어떤 고객 경험 지표를 볼 것인가.
누가 dashboard를 소유할 것인가.
어떤 alert가 사람을 깨울 가치가 있는가. metric 저장소는 서비스 성장과 보관 요구를 따라갈 수 있는가.
이 질문에 대한 카카오페이의 답은 꽤 실용적이다.
중요한 지표를 작게 시작하고, 팀이 보게 만들고, 알림을 행동으로 연결하고, 저장소 한계를 만나면 federation과 Thanos로 확장한다.
모니터링을 제품처럼 운영해야 한다는 메시지로 읽으면, 이 발표는 지금도 충분히 다시 볼 가치가 있다.