금융 사기 탐지를 “이 거래가 사기인가 아닌가”를 맞히는 모델 문제로만 보면 중요한 절반을 놓친다.
실제 서비스에서는 거래가 들어오는 즉시 판단해야 하고, 과거 행동과 주변 관계를 함께 보아야 하며, 데이터 분석가가 만든 규칙과 모델을 운영 시스템 안에 안전하게 올려야 한다.
카카오페이의 if(kakao)2020 세션 **이상거래 탐지를 위한 실시간 데이터 처리와 금융 사기 행동 분석**은 이 관점을 잘 보여준다.
발표는 FDS(Fraud Detection System)를 출발점으로 삼지만, 곧 더 넓은 RMS(Risk Management System)로 이동한다.
핵심은 사기 탐지를 모델 하나가 아니라 실시간 데이터 처리, 룰 엔진, 모델 인퍼런스, 그래프 분석, 시간 행동 피처가 결합된 플랫폼 문제로 다루는 데 있다.
무엇을 다루는 영상인가
영상은 kakao tech 채널에 올라온 if(kakao)2020 발표다.
공식 세션 페이지 기준 발표자는 카카오페이의 이완근 Will Software developer와 이재광 Lukas Machine learning engineer다.
세션 설명은 카카오페이의 금융사기 모니터링을 위한 리스크 관리 플랫폼 개발 여정과 금융 사기 데이터 분석 접근을 공유한다고 소개한다.
이 글은 YouTube 메타데이터, 한국어 자동 자막, 영상 프레임, 그리고 공식 if(kakao)2020 세션 페이지를 함께 기준으로 삼았다.
공개된 별도 코드 저장소나 상세 논문은 확인되지 않았으므로, 아래 해석은 발표가 공개한 아키텍처와 분석 아이디어 범위 안에서 읽는 편이 정확하다.
| 구간 | 발표 내용 | 글에서 보는 포인트 |
|---|---|---|
| 00:10-02:15 | 카카오페이 거래와 이상거래, FDS 소개 | 결제·송금 서비스는 거래 승인 전 아주 짧은 시간 안에 위험 여부를 확인해야 한다 |
| 02:15-04:47 | 기존 FDS와 배치성 행동 데이터의 한계 | 빠르게 변하는 사기 패턴에 대응하려면 더 많은 행동 데이터를 실시간으로 다뤄야 한다 |
| 04:55-06:10 | RMS 요구사항과 기술 선택 | 시스템 의존성을 줄인 데이터 수집, 룰·모델 조합, 대시보드가 핵심 요구사항이다 |
| 06:10-13:43 | Kafka, Akka, Redis, MLflow, TensorFlow Java, Druid 기반 RMS 구현 | 실시간 룰 엔진과 모델 인퍼런스가 하나의 스트리밍 플랫폼 안에 들어간다 |
| 13:55-16:40 | 비지도 모델, 지도 모델, 룰 기반 알고리즘 비교 | 세 방법은 장단점이 다르며 하나만으로는 안정적인 탐지가 어렵다 |
| 16:43-22:10 | 관계 기반 계좌 네트워크와 블랙리스트 추적 | 단일 유저·계좌·상점이 아니라 주변 관계와 계좌 이동을 피처로 본다 |
| 22:14-26:38 | 헬릭스 구조를 활용한 유저 행적 시각화와 피처 추출 | 거래 시간, 속도, 연속 거래 횟수 같은 시간 행동을 구조화한다 |
| 26:40-28:54 | 공격자와 방어자의 긴장, 금융 안전성 강조 | 사기 탐지는 정적 모델이 아니라 계속 바뀌는 운영 리스크와의 싸움이다 |
FDS에서 RMS로: 단일 거래 판정에서 리스크 플랫폼으로
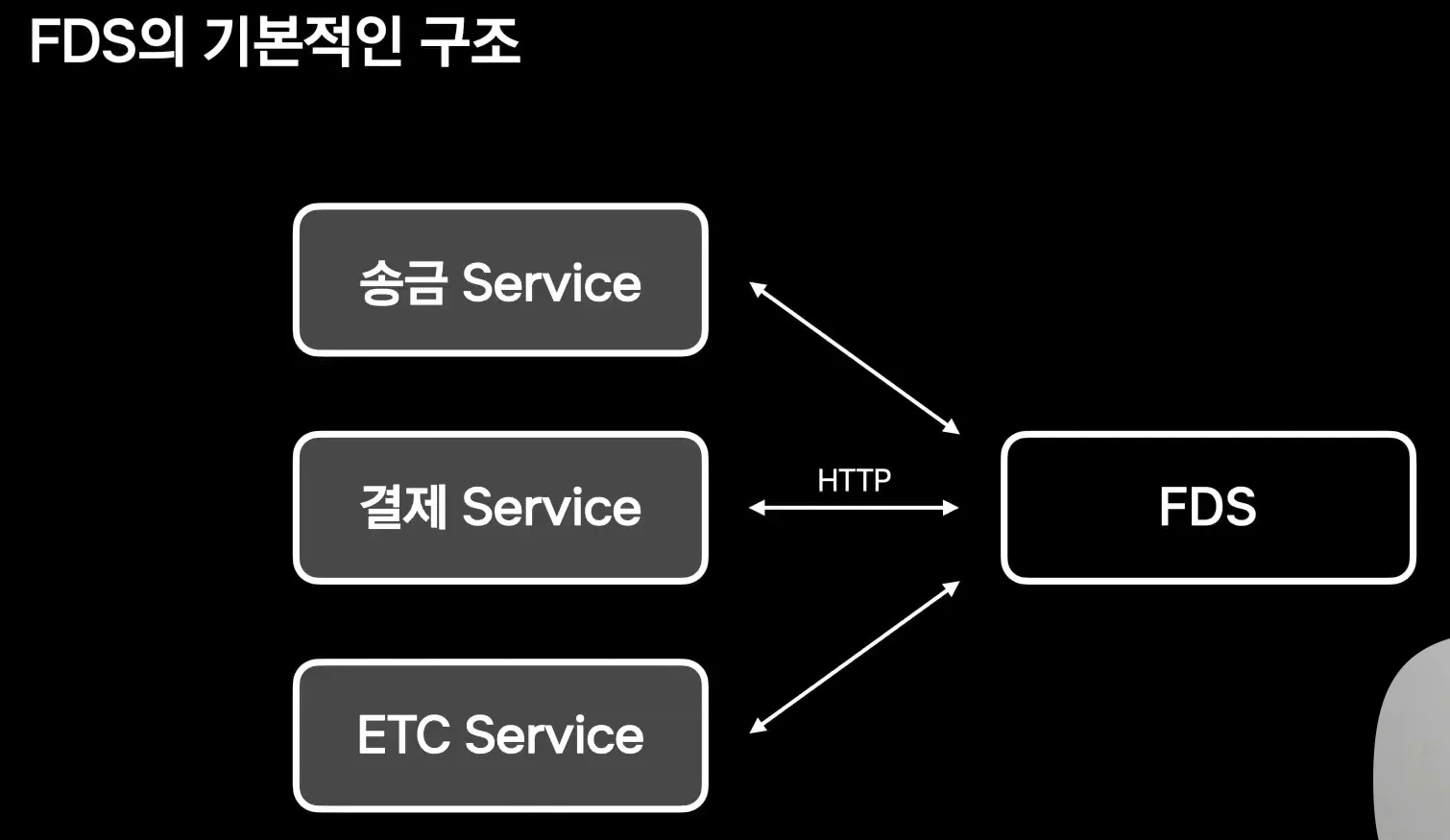
발표 초반의 FDS 구조는 단순하다.
송금, 결제, 기타 서비스가 거래를 처리하기 전 FDS에 HTTP API로 문의한다.
FDS는 거래 데이터와 사용자 행동 정보를 바탕으로 정상 거래인지 이상 거래인지 빠르게 판단해 응답한다.
문제는 행동 데이터다.
거래 데이터는 실시간으로 들어오지만, 다양한 행동 데이터는 시간 단위 또는 일 단위 ETL을 거쳐 사용되는 경우가 많다.
발표자는 이런 방식이 빠르게 변화하는 이상거래 패턴에 적극적으로 대응하기 어렵다고 설명한다.
그래서 RMS가 등장한다.
RMS는 이상거래만 보는 FDS보다 더 넓은 범위에서 데이터를 수집하고, 카카오페이 전반의 잠재적 금융 위험을 관리하며, 복잡한 룰과 모델을 실시간으로 조합하는 플랫폼이다.
여기서 사기 탐지는 더 이상 “모델을 하나 붙이는 일”이 아니라, 위험 신호를 수집하고 계산하고 운영자가 볼 수 있게 만드는 데이터 인프라가 된다.
RMS 아키텍처: 스트림, 룰, 모델, 피처 저장소가 한 몸으로 움직인다
RMS의 최초 요구사항은 세 가지로 정리된다.
시스템과의 의존성을 최소화하면서 데이터를 수집할 것, 룰뿐 아니라 다양한 모델을 적절히 조합해 실시간 모니터링할 것, 데이터 흐름과 상태를 대시보드로 확인할 수 있게 할 것.
이를 위해 발표팀은 Kafka와 Akka를 이용한 이벤트 드리븐 아키텍처를 선택했다.
Kafka로 들어오는 데이터를 이벤트로 보고, Akka Streams와 Akka Typed, Akka Cluster Sharding을 이용해 룰 엔진과 룰 액터, 컨디션 액터가 분산 환경에서 동작한다.
Kubernetes 위에서는 K8S API를 활용해 Akka Cluster 애플리케이션을 디스커버리한다고 설명한다.
발표에서 특히 흥미로운 부분은 모델이 룰 엔진 바깥의 별도 배치 산출물이 아니라, 룰 평가 과정 안의 하나의 컨디션으로 들어간다는 점이다.
컨디션에는 단건 이벤트를 필터링하는 필터 컨디션, Redis나 Druid 같은 데이터베이스를 참조하는 컨디션, 그리고 데이터 사이언티스트가 준비한 지도·비지도 모델이 올라간 모델 컨디션이 있다.
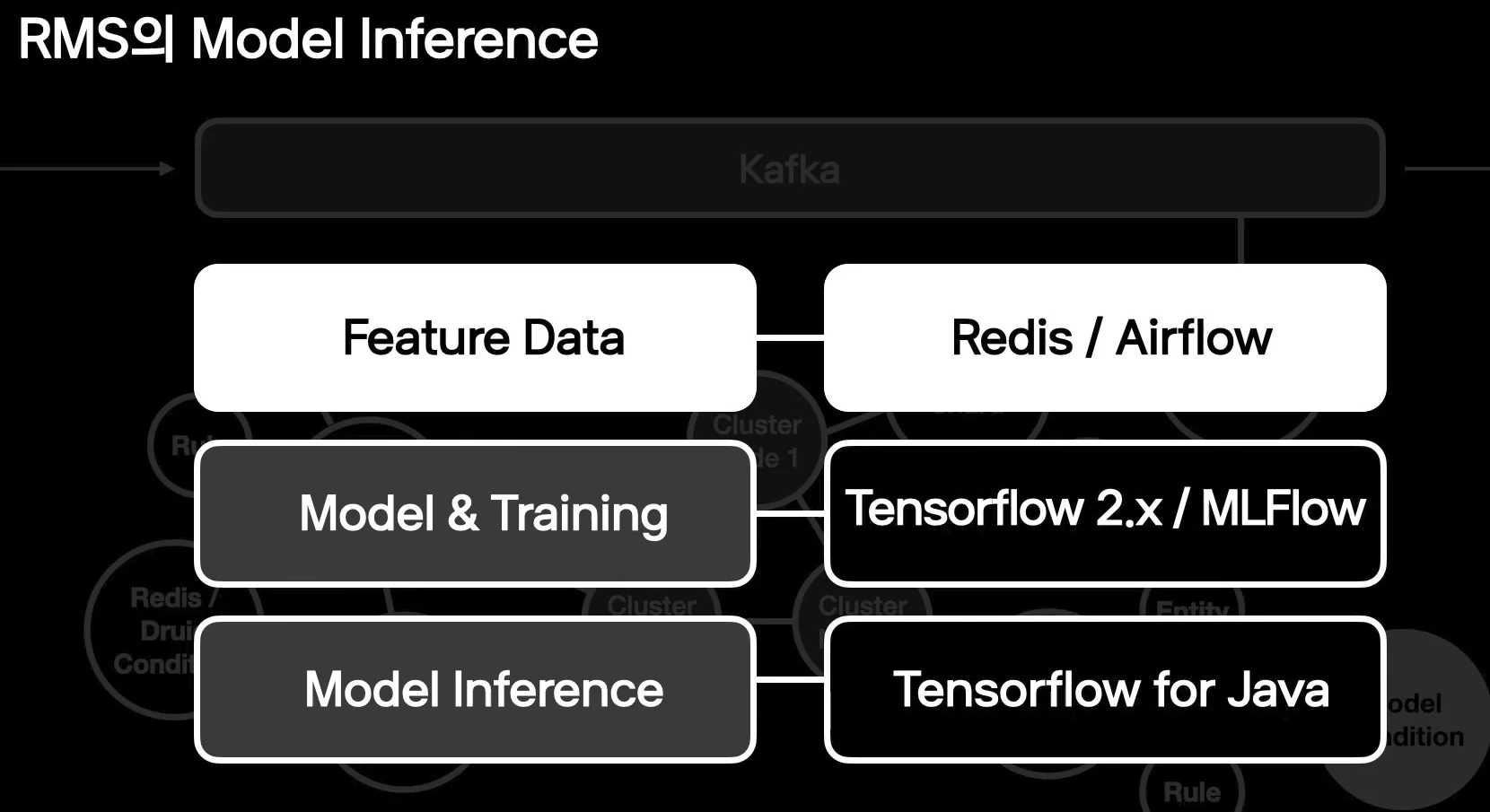
피처 데이터는 Redis에 올리고, 해당 작업은 Airflow로 주기 실행한다.
모델 학습은 MLflow를 통해 관리하고, 모델 파일 버전 관리는 Git을 사용한다.
RMS의 룰 엔진은 Scala 환경이므로 TensorFlow for Java 라이브러리를 통해 모델을 인퍼런스한다.
또 하나의 운영 포인트는 모델 교체다.
발표자는 Akka Typed의 behavior 교체를 활용해 액터를 재생성하지 않고 새 모델 인스턴스가 담긴 behavior로 바꾸는 방식을 소개한다.
즉 모델 업데이트는 “서버를 내리고 새 모델을 올리는” 형태가 아니라, 실행 중인 분산 룰 엔진 안에서 다음 이벤트 처리부터 새 모델을 쓰게 만드는 문제로 다뤄진다.
통계성 질의에는 Druid도 등장한다.
발표에서는 행동 데이터를 Kafka와 Druid로 실시간 인제스트하고, Druid의 roll-up을 활용해 특정 시간 범위의 출현 횟수나 합계 같은 실시간 통계를 산출한다고 설명한다.
이 통계는 대시보드와 룰 엔진에서 함께 활용된다.
세 가지 탐지 방식은 서로 보완해야 한다
발표 후반의 데이터 분석 파트는 RMS 위에 올라가는 모델과 알고리즘을 세 가지로 나눈다.
비지도 모델, 지도 모델, 룰 기반 알고리즘이다.
| 방식 | 장점 | 한계 |
|---|---|---|
| 비지도 모델 | 기존에 보지 못한 새로운 행동이나 아웃라이어를 관찰할 수 있다 | 명확한 평가 기준이 부족하고, “사기를 당했습니다” 이후의 관찰에 가까워질 수 있다 |
| 지도 모델 | 라벨링된 데이터를 기준으로 비교적 높은 정확도를 기대할 수 있다 | 라벨 데이터 확보가 어렵고, 변화하는 사기 수법에 유연하게 대응하기 어렵다 |
| 룰 기반 알고리즘 | 빠른 대응과 결과 해석이 쉽다 | 조건이 구체화될수록 유연성이 떨어지고 운영 인력이 많이 든다 |
이 표의 결론은 “어떤 모델이 정답인가”가 아니다.
사기 탐지에서는 새로운 패턴을 빨리 보는 능력, 이미 알고 있는 고위험 조건을 명확히 막는 능력, 라벨이 있는 사례를 안정적으로 분류하는 능력이 모두 필요하다.
따라서 발표는 하나의 모델로 모든 것을 해결하기보다, 각 방식의 상호보완성을 이해하고 혼합하는 것이 중요하다고 본다.
하지만 발표자는 여기서 한 번 더 나아간다.
세 방식을 섞어도 충분하지 않다면 무엇을 놓치고 있는가.
답은 그 순간의 행동만 보는 한계다.
사용자의 과거 행적과 주변 관계를 함께 보아야 한다는 문제의식이 이어진다.
관계: 계좌 네트워크는 단일 행으로 보이지 않는 위험을 드러낸다
관계 분석의 출발점은 유저, 계좌, 상점 하나만 보아서는 잡히지 않는 패턴이다.
발표에서는 특히 유저와 계좌 관계를 이용한 계좌 네트워크를 다룬다.
카카오페이 환경에서는 계좌와 계좌 사이의 직접 거래가 존재하지 않는다.
그래서 발표팀은 계좌와 유저 사이의 거래를 단서로 계좌 간 연결을 만든다.
예를 들어 두 계좌에 공통으로 송금한 사용자가 일정 수 이상이면, 두 계좌 사이에 관계가 있다고 보는 식이다.
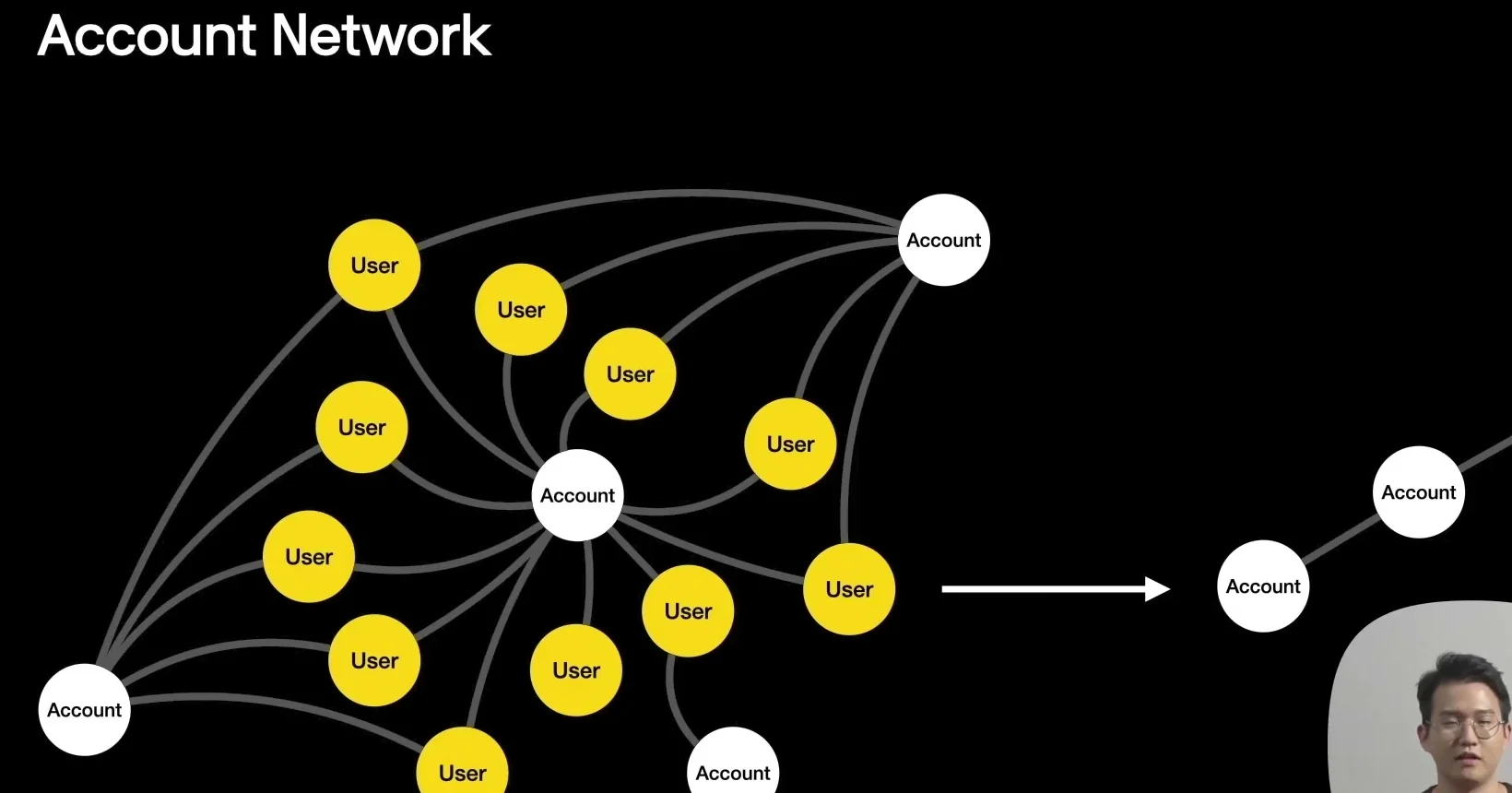
이렇게 만든 네트워크에서는 비슷한 성질의 계좌가 군집으로 묶인다.
발표에서는 사설도박 등 비정상적 목적으로 사용된 계좌들이 같은 군집에서 확인되는 사례를 언급한다.
중요한 점은 “계좌 하나가 수상하다”에서 멈추지 않고, 수상한 계좌를 기점으로 주변 계좌와 블랙리스트 후보를 추적할 수 있다는 것이다.
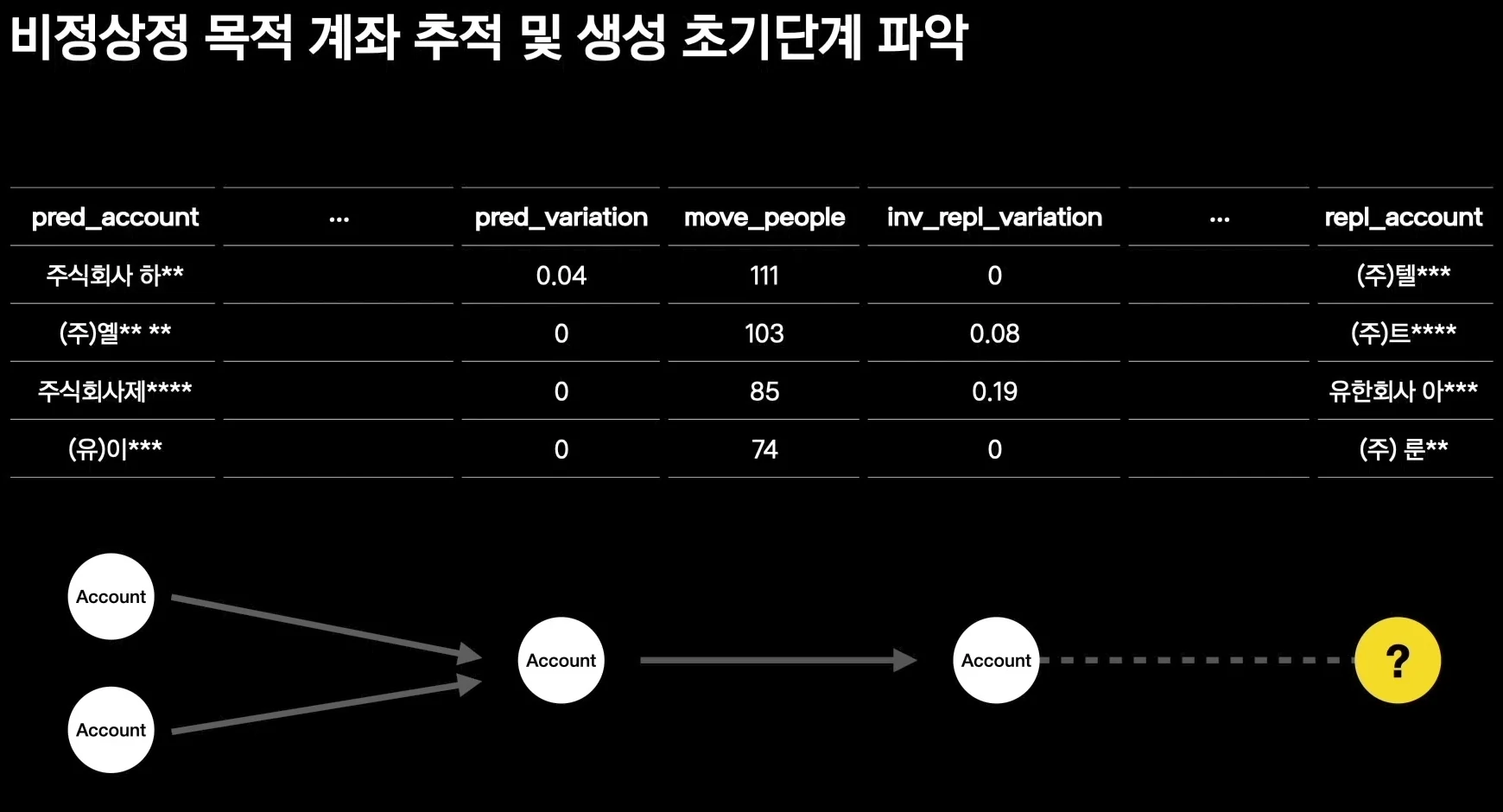
더 흥미로운 부분은 계좌의 생성과 소멸이다.
비정상 목적의 계좌는 주기적으로 만들어지고 사라질 수 있다.
이때 발표자는 “계좌가 사라지면 그 계좌를 이용하던 사람들도 같이 사라졌을까”라고 묻는다.
실제로는 이용자들이 새 계좌로 이동할 수 있으므로, 소멸하는 계좌와 급격히 상승하는 계좌 사이의 이동을 추적해야 한다.
관계 피처는 여기서 끝나지 않는다.
발표는 계좌 네트워크에서 코어 넘버, 트라이앵글, 디그리, 네트워크 임베딩 같은 그래프 피처를 뽑아 관계 위험도 산출과 모델에 활용한다고 설명한다.
이 부분은 전형적인 테이블 피처 엔지니어링보다 그래프 기반 위험 신호에 가깝다.
행적: 거래 시간을 헬릭스 구조로 펼쳐 행동 피처를 만든다
두 번째 축은 행적이다.
사기는 대개 기존 행동과 다른 행동을 보인다는 공통점이 있다.
그러려면 사용자의 과거 행동을 한눈에 보고, 시간의 흐름에 따른 변화를 구조화할 방법이 필요하다.
발표자는 이를 설명하기 위해 테서랙트와 헬릭스 구조를 가져온다.
4차원을 그대로 다루기 어렵기 때문에, 두 차원은 현실 공간처럼 쓰고 한 차원은 시간축으로 두자는 아이디어다.
나선 계단을 떠올리면 이해하기 쉽다.
한 바퀴는 24시간, 층수는 날짜, 계단 위의 흔적은 거래 이벤트가 된다.
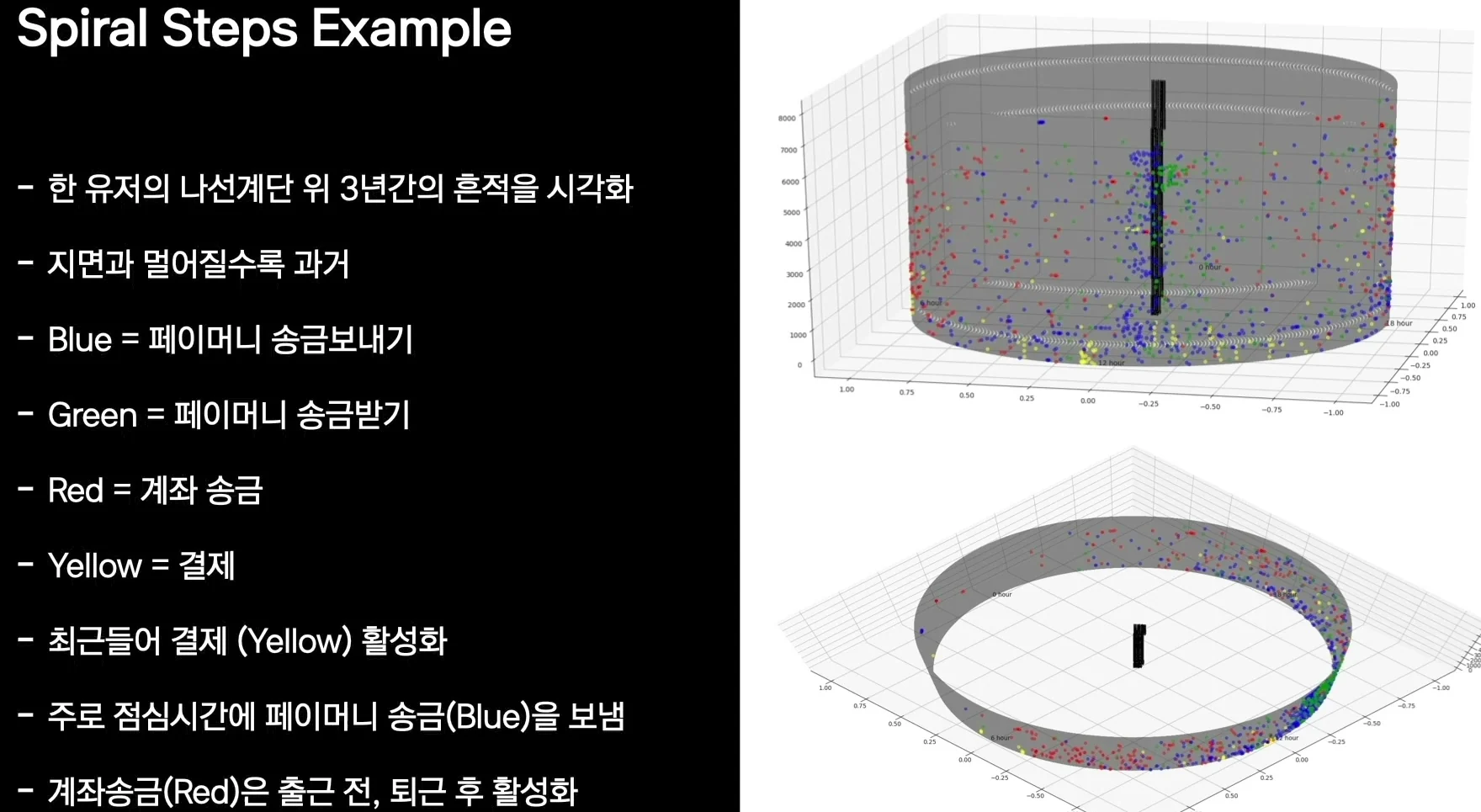
이 구조에서 추출하는 피처는 꽤 실용적이다.
헬릭스를 위에서 내려다보듯 XY 평면에 투영한 뒤 DBSCAN 같은 밀도 기반 클러스터링을 적용하면 사용자의 주요 거래 시간을 추정할 수 있다.
거래 흔적 사이의 라디안 차이를 계산하면 거래 속도를 볼 수 있고, 3차원 밀도 기반 클러스터링을 적용하면 연속 거래 횟수나 최대 연속 거래 패턴을 파악할 수 있다.
발표에서는 거래 데이터에서 금액과 시간 정보를 뽑아 amount, day, radian 형태로 바꾸고, PySpark로 각 유저의 헬릭스 구조를 만든 뒤 주요 거래 시간, 거래 속도, 단기간 연속 거래 횟수 등을 피처로 활용한다고 설명한다.
흔히 쓰는 RFM(Recency, Frequency, Monetary)보다 더 구체적인 시간 행동 표현을 만들려는 시도다.
실무 관점에서의 해석
이 발표의 가치는 특정 기술 조합 자체보다 관점에 있다.
금융 사기 탐지는 모델 정확도 경쟁만으로 운영되지 않는다.
실제 서비스에서는 거래가 들어오는 순간 판단해야 하고, 판단 근거가 대시보드와 룰로 이어져야 하며, 모델은 배치 산출물이 아니라 실시간 룰 엔진 안에서 실행되고 교체되어야 한다.
그래서 RMS는 세 층의 문제를 동시에 푼다.
| 층 | 발표에서의 구현 방향 | 의미 |
|---|---|---|
| 실시간 실행 | Kafka, Akka Streams, Akka Cluster Sharding, Kubernetes | 거래 이벤트를 낮은 지연으로 분산 처리한다 |
| 피처·모델 운영 | Redis, Airflow, MLflow, TensorFlow for Java, Git | 분석 모델을 운영 룰 엔진 안에서 사용할 수 있게 한다 |
| 위험 표현 | 계좌 그래프, 계좌 이동, 헬릭스형 행적 피처 | 단일 거래 행으로는 보이지 않는 관계·시간 패턴을 만든다 |
동시에 한계도 분명하다.
이 영상은 if(kakao)2020 세션이므로 현재 카카오페이의 최신 FDS/RMS 구현을 그대로 설명한다고 볼 수는 없다.
공개 발표라 세부 성능 지표, 오탐·미탐 trade-off, 개인정보 보호 설계, 운영 알림 정책, 모델별 실제 precision/recall 같은 정보도 제한적으로만 드러난다.
그럼에도 이 발표는 여전히 참고할 만하다.
사기 탐지와 리스크 관리는 “AI 모델 하나를 붙이면 해결되는 문제”가 아니라, 스트리밍 데이터 플랫폼과 데이터 분석 표현을 함께 설계해야 하는 문제라는 점을 아주 구체적인 운영 언어로 보여주기 때문이다.
공격자는 계속 새로운 사각지대를 찾는다.
방어 시스템도 그래서 정적인 모델이 아니라, 데이터를 더 빨리 모으고, 관계와 행적을 더 잘 표현하고, 룰과 모델을 더 안전하게 교체하는 플랫폼으로 진화해야 한다.
이 발표의 메시지는 바로 그 지점에 있다.