인프라를 코드처럼 관리한다는 말은 이제 너무 익숙하다.
하지만 실제 운영 조직에서 그 말은 단순히 Terraform 파일을 저장소에 넣는다는 뜻으로 끝나지 않는다.
어떤 리소스를 코드로 묶을지, 환경별 차이는 어디에 둘지, 콘솔에서 급하게 고친 변경을 어떻게 다시 코드와 맞출지, 런타임에서 장애와 스케일링을 어떻게 자동 복구 루프로 넘길지까지 같이 정해야 한다.
[if(kakao)2020] DevOps at GroundX: 인프라도 코드처럼은 그 지점을 꽤 실무적으로 보여주는 영상이다.
발표는 GroundX가 Klip, KAS, Klaytn 기반 서비스를 준비하면서 마주한 고가용성, 보안, 개발 속도 요구를 Terraform과 Kubernetes/EKS, Helm, CI/CD, Kubernetes 생태계 도구로 어떻게 나눠 풀었는지를 설명한다.
핵심은 특정 도구 하나의 도입기가 아니다.
Terraform은 클라우드 리소스를 재현 가능한 베이스로 만들고, Kubernetes는 애플리케이션 런타임을 선언형 상태로 유지하며, 팀 프로세스는 콘솔 변경과 코드 drift를 막는 운영 규칙으로 붙는다.
이 세 층이 같이 있어야 “인프라를 코드처럼”이라는 말이 실제 서비스 운영 언어가 된다.
무엇을 다루는 영상인가
영상의 발표자는 GroundX DevOps 엔지니어 Austin Brown과 Jade다.
설명의 출발점은 GroundX가 운영하던 Klip 지갑, KAS API 서비스, 그리고 그 기반이 되는 Klaytn 블록체인 플랫폼이다.
사용자가 Klip에서 자산을 조회하거나 전송하면 Klip은 KAS에 요청하고, KAS는 내부 Klaytn endpoint node와 통신해 트랜잭션과 블록 정보를 다룬다.
이 구조에서 한 컴포넌트의 장애는 지갑과 API 서비스 모두에 영향을 줄 수 있다.
블록체인·지갑 서비스라는 성격상 보안과 규제 대응도 설계 초기에 고려해야 한다.
동시에 제품 요구 사항은 계속 바뀌기 때문에, 인프라 변경을 수동 콘솔 작업에 묶어 두면 출시 속도와 운영 신뢰성이 같이 흔들린다.

핵심 아이디어: 프로비저닝과 런타임을 분리한 IaC
발표의 첫 번째 축은 Terraform이다.
GroundX는 AWS 기반 인프라에서 네트워크, Kubernetes, 데이터베이스, 로드 밸런서 등 필요한 리소스를 Terraform 코드로 정의해 구축·관리한다고 설명한다.
영상에서 언급된 서비스 수만 40개가 넘기 때문에, 콘솔에서 환경을 반복 생성하는 방식은 시간도 많이 들고 운영 중 변경 이력도 흐려진다.
Terraform이 주는 직접적인 이점은 세 가지다.
같은 코드로 여러 환경을 재현할 수 있고, 변경 이력을 Git history로 추적할 수 있으며, 리소스 구성이 코드 자체로 문서화된다.
여기서 중요한 것은 Terraform을 “한 번 생성하고 끝내는 스크립트”가 아니라, 운영 중 변경까지 포괄하는 source of truth로 둔다는 점이다.
발표는 Terraform 모듈화도 강조한다.
VPC, private/public subnet, route table, NAT gateway, internet gateway 같은 base layer 리소스는 하나의 모듈로 묶고, EKS나 static site, RDS, cache, application-specific API 리소스는 별도 모듈로 나눈다.
이렇게 base layer와 application layer를 분리하면 애플리케이션 리소스를 수정할 때 네트워크·클러스터 베이스에 주는 영향을 줄일 수 있다.
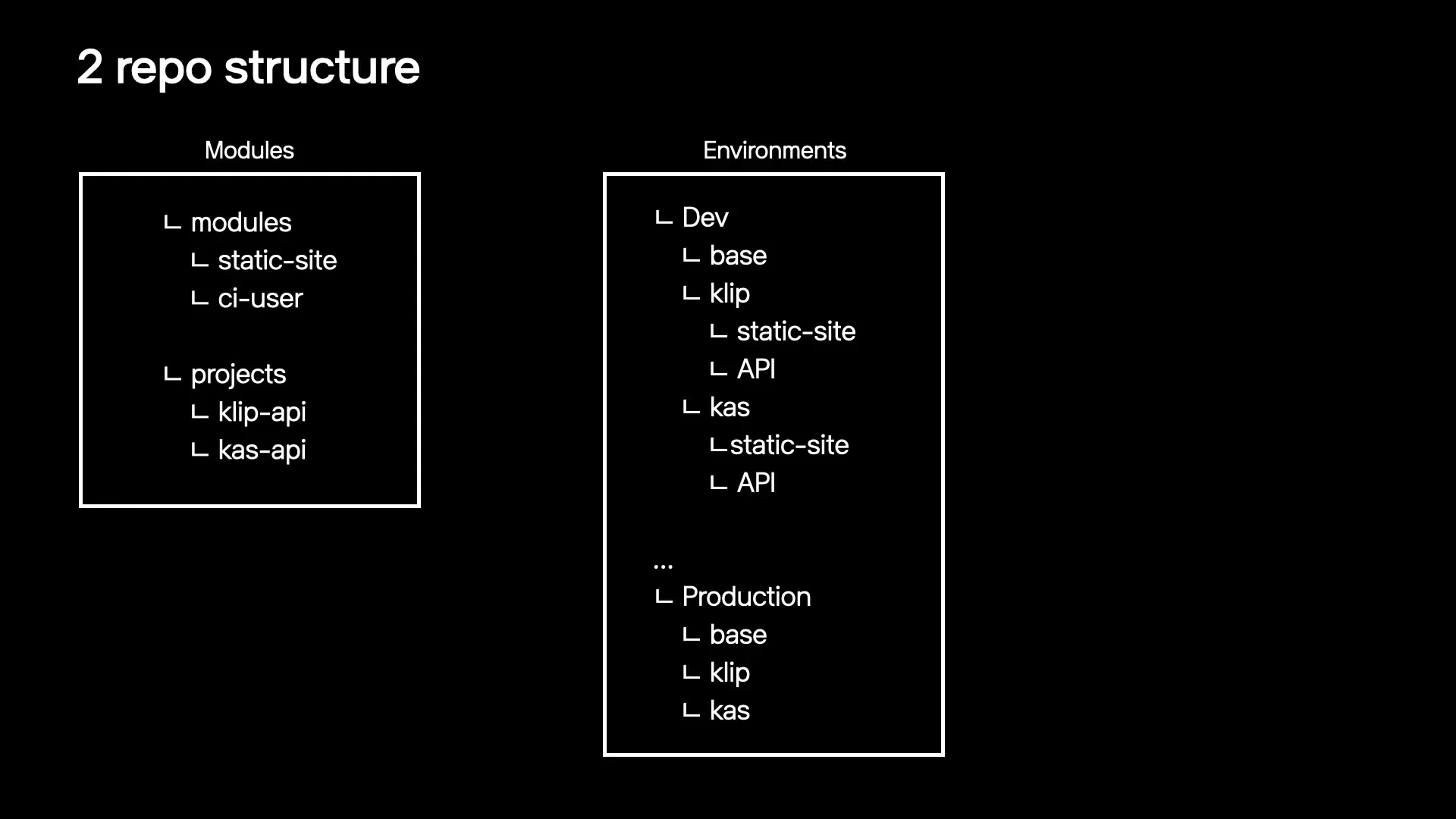
다만 발표가 솔직하게 짚는 대목은 Terraform 도입 자체가 쉬운 일은 아니라는 점이다.
처음 작성할 때는 콘솔에서 바로 만드는 것보다 시간이 더 들어간다.
프로덕션에서 급한 변경을 콘솔로 처리하면 이후 Terraform apply 시 충돌이 생길 수 있다.
그래서 해법은 도구만이 아니라 문화와 프로세스다.
모든 팀원이 Terraform으로 리소스를 만들고 변경하는 흐름을 익혀야 하고, Terraform이 꼭 필요하지 않은 실험용 리소스는 별도 sandbox AWS account로 분리할 수 있다.
더 나아가 Terraform Enterprise나 Atlantis 같은 도구로 인프라 변경 주체를 CI/CD 흐름 안으로 모으는 방향도 제시한다.
두 번째 축은 Kubernetes/EKS다.
Terraform이 클라우드 베이스를 준비한다면, Kubernetes는 그 위에서 애플리케이션을 어떻게 배포하고 유지할지 담당한다.
발표는 여러 마이크로서비스가 각기 다른 요구 조건을 갖고 있기 때문에, 설치 자동화와 설정 관리만으로는 부족하고 배포 이후 runtime management까지 한 플랫폼에서 다뤄야 한다고 설명한다.
Kubernetes 쪽 설명은 선언형 리소스를 중심으로 진행된다.
Deployment는 원하는 pod replica 수와 container image, CPU·memory 요구 조건을 선언한다.
Service는 여러 pod를 하나의 endpoint처럼 묶고 health check를 통해 정상 pod로만 연결한다.
Ingress는 외부 요청을 어떤 service로 보낼지 정하는 layer 7 load balancing 인터페이스다.
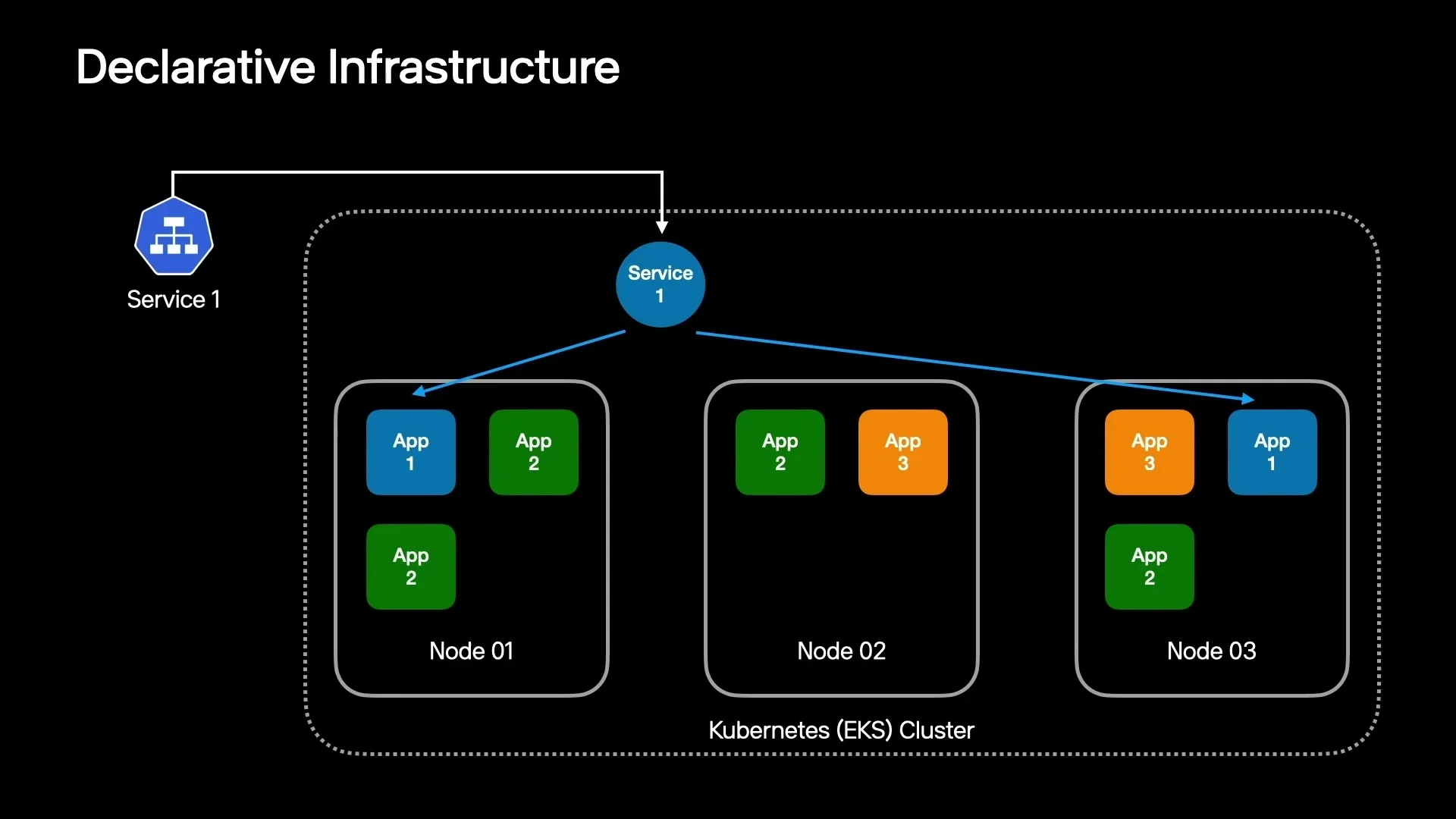
이 구조가 고가용성과 연결되는 지점은 자동 복구다.
한 노드가 장애를 일으키면 Deployment의 desired state에 따라 pod가 정상 노드로 이동하고, Service는 살아 있는 replica로 트래픽을 보낸다.
사용자가 보는 영향을 줄이기 위해 장애 대응을 사람의 수동 조치가 아니라 control plane의 reconcile loop로 넘기는 셈이다.

스케일링도 같은 맥락이다.
Horizontal Pod Autoscaler는 pod의 CPU·memory 사용량이 임계치를 넘으면 replica 수를 늘린다.
그런데 기존 node 자원이 부족하면 pending pod가 생긴다.
이때 Cluster Autoscaler가 pending 상태를 감지해 AWS Auto Scaling Group의 desired capacity를 늘리고, 새 EKS node가 등록되면 남은 pod가 스케줄링된다.
배포 단계에서는 Helm과 CircleCI가 나온다.
애플리케이션이 릴리스되면 CI가 이미지를 빌드하고 Git hash로 image tag를 지정한다.
이후 Helm은 환경별 values 파일과 chart template을 사용해 Kubernetes resource를 생성·수정하고, 새 pod가 정상 시작될 때까지 기다린다.
실패하면 일정 시간 후 기존 설정으로 복구하는 방식까지 포함된다.
타임라인으로 보는 핵심 구간
| 구간 | 내용 | 읽을 포인트 |
|---|---|---|
| 00:10–03:10 | GroundX 서비스와 과제 소개 | Klip, KAS, Klaytn 구성에서 고가용성·보안·개발 속도가 동시에 중요해진다. |
| 03:10–06:50 | Terraform으로 AWS 리소스 프로비저닝 | 40개가 넘는 서비스 리소스와 여러 환경을 콘솔이 아니라 코드로 재현한다. |
| 06:50–09:20 | Terraform 모듈과 두 저장소 구조 | base layer와 application layer, modules repo와 environments repo를 분리해 변경 영향 범위를 줄인다. |
| 09:20–10:50 | Terraform 운영의 어려움과 프로세스 | 콘솔 변경으로 생기는 drift를 막기 위해 팀 문화, sandbox account, Atlantis/CI 흐름이 필요하다. |
| 10:50–14:50 | 애플리케이션 오케스트레이션 요구와 EKS 선택 | 배포, 접근 제어, 로깅, 모니터링, 패치, service discovery까지 runtime platform 관점으로 본다. |
| 15:00–18:50 | Deployment, Service, Ingress, 장애 복구, autoscaling | Kubernetes의 desired state와 scheduler/reconcile loop가 장애와 부하 변동을 흡수한다. |
| 18:50–21:20 | Helm, CircleCI, 운영 생태계 도구 | chart, values, image tag, logging operator, Vault, service mesh로 배포와 운영 작업을 코드화한다. |
| 21:20–23:50 | 결과와 향후 과제 | 발표 기준으로 downtime 없이 운영·업데이트했고, 앞으로 Atlantis 연동과 인프라 테스트/롤백 프로세스를 강화하려 한다. |
영상에서 확인되는 점
이 영상에는 공식 챕터가 없고, 설명란에도 별도 GitHub 저장소나 문서 링크가 붙어 있지 않다.
따라서 이 글은 YouTube 메타데이터, 설명란, 자동 한국어 transcript, 그리고 영상 속 슬라이드 프레임을 기준으로 정리했다.
자동 자막에는 일부 ASR 오류가 있으므로, 도구명과 서비스명은 제목·설명란·슬라이드 맥락을 함께 보고 보정했다.
확인 가능한 범위에서 발표의 주요 사실은 다음과 같다.
- 발표 제목은
DevOps at GroundX: 인프라도 코드처럼이며, 채널은kakao tech다. - 발표자는 GroundX DevOps engineer Austin Brown과 Jade로 소개된다.
- 대상 서비스는 Klip, KAS, Klaytn platform이며, 운영 요구는 고가용성, 보안, 개발 속도로 반복 정리된다.
- 클라우드 리소스 프로비저닝에는 Terraform을 사용하고, VPC/EKS 등 일부 영역에서는 Terraform Registry의 공개 모듈도 활용한다고 설명한다.
- 애플리케이션 오케스트레이션에는 Kubernetes와 AWS EKS를 선택했고, Deployment, Service, Ingress, HPA, Cluster Autoscaler를 핵심 예시로 든다.
- 배포와 운영 도구로 Helm, CircleCI, Logging Operator, dashboard, HashiCorp Vault, service mesh, metrics, cluster autoscaling이 언급된다.
- 향후 과제로는 Terraform 협업 강화를 위한 Atlantis 연동, 더 안전한 staged/canary 계열 배포 프로세스, 클러스터 인프라 자체에 대한 테스트와 rollback 프로세스가 제시된다.

실무 관점에서의 해석
이 발표의 가장 좋은 점은 “Terraform을 썼다”나 “Kubernetes를 썼다”에서 멈추지 않는다는 것이다.
GroundX의 사례는 인프라 자동화가 결국 프로비저닝 코드, 런타임 desired state, 변경 승인 프로세스의 결합이라는 점을 보여준다.
셋 중 하나만 빠져도 IaC는 쉽게 흔들린다.
Terraform은 리소스를 만들 수 있지만, 콘솔에서 변경한 운영 현실까지 자동으로 정리해 주지는 않는다.
그래서 source of truth를 코드로 유지하려면 팀원이 Terraform을 실제 변경 경로로 받아들여야 한다.
PR, CI, Atlantis 같은 도구는 그 합의를 강제하거나 보조하는 장치다.
Kubernetes도 마찬가지다.
Deployment, Service, Ingress, HPA는 운영자가 매번 직접 복구·확장 스크립트를 작성하지 않아도 되게 해 준다.
하지만 이 또한 “설정이 곧 운영 정책”이 되는 구조이기 때문에, chart와 values, secret, traffic policy, monitoring rule이 모두 테스트와 리뷰 대상이 된다.
발표 마지막의 “인프라 도구 자체에 대한 테스트와 rollback이 필요하다”는 말은 지금 들어도 꽤 정확하다.
또 하나 배울 점은 계층 분리다. base layer와 application layer를 나누고, modules repo와 environments repo를 구분하는 설계는 조직이 커질수록 중요해진다.
모든 리소스를 한 파일이나 한 모듈에 몰아넣으면 재사용은 쉬워 보이지만 변경 blast radius가 커진다.
반대로 계층을 잘 나누면 팀은 공통 인프라를 안정적으로 유지하면서도 서비스별 변경을 빠르게 반영할 수 있다.
물론 이 영상은 if(kakao)2020 세션이므로, 오늘의 Kubernetes 운영 표준과는 세부 도구 선택이 달라질 수 있다.
그래도 기본 질문은 그대로다.
어떤 것은 Terraform state로 관리할 것인가.
어떤 것은 Kubernetes desired state로 둘 것인가.
어떤 변경은 PR과 CI를 통과해야 하는가.
어떤 실험은 sandbox에서 허용할 것인가.
운영 장애와 배포 실패는 사람이 대응하기 전에 시스템이 어디까지 흡수해야 하는가.
그 질문들에 대한 하나의 실무적 답으로 이 발표는 여전히 유효하다.
“인프라도 코드처럼”은 코드 파일을 만든다는 선언이 아니라, 인프라 변경을 재현 가능하고 리뷰 가능하며 복구 가능한 운영 루프로 밀어 넣는 일이다.