최근 LLM 경쟁력은 모델 아키텍처만으로 설명되지 않는다.
실제 성능 차이는 어떤 데이터를 모으고, 어떻게 정제하고, 어떤 합성 파이프라인으로 학습 신호를 만들었는지에서 갈린다.
문제는 이 중요한 데이터 준비 단계가 여전히 프로젝트별 임시 스크립트와 느슨한 워크플로우에 의존하는 경우가 많다는 점이다.
실험은 돌아가더라도 재현성이 떨어지고, 운영으로 넘어가면 파이프라인이 사람에게 종속된다.
DataFlow가 흥미로운 이유는 바로 이 지점을 시스템 레벨에서 다루기 때문이다.
이 프레임워크는 데이터 준비를 단순 전처리나 필터링 작업이 아니라, 생성(generate)·평가(evaluate)·필터링(filter)·정제(refine)를 조합하는 프로그래밍 가능한 데이터플로우로 본다. arXiv 기술 문서 기준으로 DataFlow는 거의 200개의 재사용 가능한 연산자와 6개의 범용 파이프라인을 제공하며, 자연어 명세를 실행 가능한 파이프라인으로 바꾸는 DataFlow-Agent까지 포함한다.

무엇을 해결하려는가
데이터 중심 AI에서는 모델을 한 번 더 학습시키는 것보다, 어떤 데이터를 어떤 구조로 흘려보낼 것인지가 더 중요해진다.
특히 텍스트, 수학, 코드, Text-to-SQL, Agentic RAG, 지식 추출처럼 데이터 생성과 정제가 복잡하게 섞인 작업에서는 단순 수집이나 중복 제거만으로는 충분하지 않다.
모델이 직접 데이터 생성 루프에 들어오는 model-in-the-loop 워크플로우까지 고려하면, 파이프라인은 더 이상 일회성 스크립트로 유지되기 어렵다.
PyTorchKR 리뷰와 논문 초록이 공통으로 강조하는 문제도 여기에 있다.
현재 실무는 ad-hoc script와 느슨한 워크플로우가 지배적이고, 이 방식은 재현성을 해치며 의미론적으로 풍부한 데이터 준비를 어렵게 만든다.
DataFlow는 이 공백을 메우기 위해 모듈화된 시스템 추상화, PyTorch 스타일 파이프라인 API, 재사용 가능한 연산자 계층을 제공해 데이터 준비를 디버깅 가능하고 최적화 가능한 엔지니어링 대상으로 바꾸려 한다.
핵심 아이디어 / 구조 / 동작 방식
DataFlow의 핵심은 데이터 준비를 연산자(operator) 중심 파이프라인으로 표준화하는 데 있다.
GitHub README는 이를 “Generate, Clean, and Prepare LLM Data, All-in-One”으로 설명하고, noisy source에서 고품질 학습 데이터를 만드는 시스템으로 정의한다.
즉 원천 데이터는 PDF, 일반 텍스트, 저품질 QA처럼 제각각일 수 있지만, 처리 단계는 생성·정제·평가·필터링이라는 공통 인터페이스 위에서 결합된다.
공식 소개에 따르면 이 시스템은 크게 네 계층으로 볼 수 있다.
DataFlow-Core는 스토리지, LLM 서빙, 연산자, 프롬프트 템플릿 같은 실행 기반을 맡고, Pipeline Zoo는 텍스트·수학·코드·Text-to-SQL·에이전트 RAG 등 도메인별 파이프라인 묶음을 제공한다.
Control Layer에는 CLI와 DataFlow-Agent가 위치해 사용자의 명시적 명령 또는 자연어 의도를 파이프라인 실행으로 연결하고, Ecosystem 계층은 외부 연산자와 확장 패키지를 받아들이는 배포 단위를 담당한다.
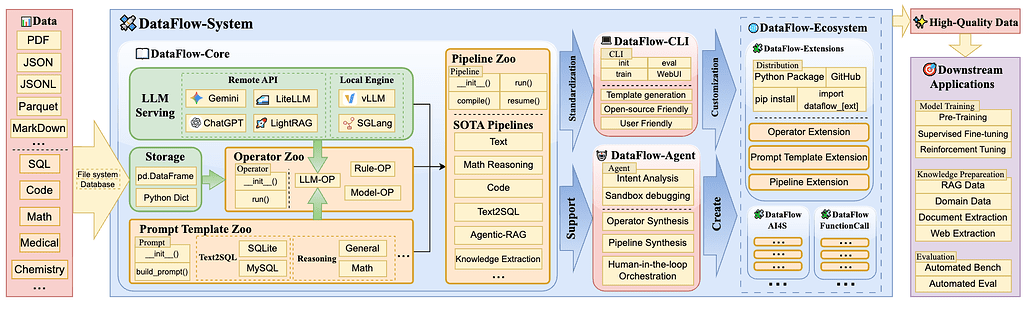
읽기 쉽게 정리하면 DataFlow가 기존 데이터 정제 계열 도구와 구분되는 포인트는 다음에 가깝다.
| 관점 | 일반적인 데이터 정제 도구 | DataFlow |
|---|---|---|
| 주된 초점 | 기존 데이터 추출, 필터링, 중복 제거 | 생성 + 평가 + 필터링 + 정제를 하나의 파이프라인으로 통합 |
| 모델의 역할 | 주로 후단 소비자 | 데이터 생성과 변환 과정에 직접 참여하는 model-in-the-loop 구성 |
| 워크플로우 형태 | 작업별 스크립트 또는 개별 배치 | 재사용 가능한 operator/pipeline 조합 |
| 확장 방식 | 도구별 플러그인 또는 별도 코드 | PyTorch 스타일 계층 구조와 extension ecosystem |
| 사용 인터페이스 | CLI, 스크립트, 개별 서비스 | CLI + Agent + WebUI + distributed orchestration |
이 프레임워크의 설계가 특히 실용적으로 느껴지는 부분은 인터페이스를 세분화한 방식이다.
기술 문서에 따르면 DataFlow는 글로벌 스토리지 추상화, 계층적 프로그래밍 인터페이스, 연산자 분류 체계, 확장 메커니즘이라는 네 개의 기둥 위에 서 있다.
스토리지는 read-transform-write 패턴을 따르며, 연산자는 입력 키와 출력 키를 바인딩해 서로 다른 스키마를 가진 데이터셋에도 유연하게 재사용된다.
또한 프롬프트 템플릿을 연산자 로직과 분리해 Text-to-SQL 같은 작업에서 동일한 연산자 코드를 유지한 채 프롬프트만 교체할 수 있게 한다.
DataFlow-Agent도 중요한 차별점이다.
논문과 커뮤니티 글 기준으로 이 에이전트는 의도 분석, 데이터 라우팅, 연산자 검색, 연산자 합성, 파이프라인 구성, 검증 에이전트가 협력하는 구조를 가진다.
사용자는 자연어로 목적을 말하고, 시스템은 필요하면 기존 연산자를 검색하고, 없으면 새 연산자 코드를 합성하며, 최종적으로 검증 가능한 DAG 형태의 파이프라인을 조립한다.
이건 단순 자동완성보다 한 단계 위의 오케스트레이션 계층이다.
공개된 근거에서 확인되는 점
논문 초록에서 가장 강하게 드러나는 주장은 성능과 범위다.
DataFlow는 거의 200개의 reusable operator와 6개의 대표 사용 사례 파이프라인을 제공하며, Text-to-SQL에서는 SynSQL 대비 최대 3% execution accuracy 향상, 코드 벤치마크에서는 평균 7% 개선, 수학 벤치마크에서는 MATH·GSM8K·AIME에서 1~3포인트 향상을 보고한다.
또한 DataFlow가 만든 통합 10K 샘플 데이터셋이 1M 규모 Infinity-Instruct 기반 학습 모델을 능가했다고 주장한다.
PyTorchKR 글은 이 결과를 더 세부적으로 풀어준다.
예를 들어 Text-to-SQL에서는 9만 개 규모의 DataFlow-Text2SQL-90K가 250만 개의 SynSQL보다 평균 실행 정확도에서 더 낫다고 요약하고, AgenticRAG 실험에서는 인간이 구축한 데이터셋 대비 더 강한 OOD 일반화 성능을 보였다고 설명한다.
코드 도메인에서도 실행 기반 필터링을 포함한 파이프라인이 단순 오픈소스 instruction 데이터보다 더 안정적인 성능 향상을 준다는 식으로 해석된다.
GitHub README에서 확인되는 실용 정보도 있다.
현재 설치 패키지는 open-dataflow이며 Python 3.10 이상을 지원하고, dataflow webui로 시각적 파이프라인 빌더를 실행할 수 있다.
README는 DataFlow Suite를 WebUI, Agent, Ecosystem, RayOrch의 네 축으로 설명하며, 분산 오케스트레이션 계층까지 포함한 확장 계획을 공개하고 있다.
즉 이 프로젝트는 단순 연구 프로토타입이 아니라, 패키징·배포·시각화·분산 실행까지 염두에 둔 제품형 오픈소스에 가깝다.
커뮤니티 글에 포함된 파이프라인 사례들도 DataFlow의 포지션을 잘 보여준다.
Text-to-SQL에서는 SQL Generator, SQL Augmentor, Execution Filter, Question Generator, CoT Generator를 조합하고, 수학 추론 데이터 준비에서는 문제 합성, 품질 검증, CoT 생성을 분리하며, 지식 추출에서는 MinerU 기반 문서 정규화와 QA 생성을 연결한다.
이 모든 예시는 결국 DataFlow가 “모델 학습을 위한 데이터 생성 공장”을 만들려는 방향이라는 점을 드러낸다.
실무 관점에서의 해석
내가 보기에 DataFlow의 가장 큰 가치는 데이터 준비를 모델 성능의 전처리 단계가 아니라, 독립적인 시스템 설계 문제로 다룬다는 데 있다.
실제 팀에서는 모델 교체보다 데이터 파이프라인 개선이 더 자주 일어나고, 더 큰 성능 차이를 만들기도 한다.
그런데 이 과정이 스크립트와 프롬프트 조각에 흩어져 있으면 품질 개선의 이유를 재현하거나 조직적으로 공유하기 어렵다.
DataFlow는 그 흩어진 결정을 operator, prompt, pipeline, storage abstraction으로 분리해 팀 자산으로 남기려 한다.
또 하나 중요한 점은 이 프레임워크가 데이터 양보다 데이터 설계의 효율을 강조한다는 것이다.
논문과 커뮤니티 글 모두 “소량의 잘 설계된 합성/정제 데이터가 대규모 일반 데이터보다 더 좋은 결과를 만들 수 있다”는 메시지를 강하게 민다.
만약 이 주장이 현장에서 반복 검증된다면, DataFlow 같은 시스템은 단순 편의 도구가 아니라 학습 비용 구조 자체를 바꾸는 도구가 된다.
물론 한계도 있다.
범용 프레임워크가 강력해질수록 운영 복잡도도 함께 커진다.
연산자 품질, 프롬프트 템플릿 관리, 검증 기준, LLM backend 비용, 데이터 거버넌스 기준을 팀이 직접 설계해야 하기 때문이다.
DataFlow-Agent가 자연어에서 파이프라인을 만들 수 있다 해도, 최종 품질 책임은 여전히 도메인 전문가와 플랫폼 엔지니어에게 있다.
그래서 이 프로젝트는 “데이터 준비를 자동화해준다”보다 “데이터 준비를 시스템적으로 운영할 수 있게 해준다”라고 이해하는 편이 정확하다.
데이터 중심 AI, synthetic data ops, Agentic RAG 데이터셋 구축, Text-to-SQL 학습 데이터 설계 같은 문제를 다루는 팀이라면 이 프레임워크는 충분히 볼 가치가 있다.
특히 데이터 준비를 모델 학습 전의 잡무가 아니라, 경쟁 우위를 만드는 생산 시스템으로 보는 팀일수록 더 크게 공감할 프로젝트다.