엔터프라이즈 AI 에이전트가 잘 안착하지 못하는 이유를 모델 성능 부족으로만 설명하기는 어렵다. 이미 모델은 코드를 쓰고, PR을 리뷰하고, 간단한 풀스택 앱을 빠르게 만들 수 있다. 그런데 실제 조직의 Jira epic은 여전히 잘 움직이지 않고, 운영 사고를 해결하는 데 필요한 맥락은 여전히 사람 머릿속에 남아 있다.
AI Engineer 채널의 워크숍 영상 **“Demand-Driven Context: A Methodology for Coherent Knowledge Bases Through Agent Failure”**는 이 간극을 정면으로 다룬다. 발표자인 Raj Navakoti는 자신을 IKEA의 delivery and services 도메인에서 일하는 staff software engineer라고 소개하며, 에이전트가 실패하는 지점을 지식 베이스 설계의 입력으로 삼는 Demand-Driven Context, DDC를 설명한다.
이 글의 핵심 해석은 간단하다. DDC는 RAG나 MCP를 더 많이 붙이는 방법론이 아니다. 오히려 “무엇을 문서화해야 하는가”를 사람이 미리 정하지 않고, 실제 work item에서 에이전트가 실패하며 요구한 지식만 큐레이션하는 방식이다.
무엇을 다루는 영상인가
이 영상은 약 68분짜리 워크숍이다. 초반에는 AI 에이전트가 왜 엔터프라이즈 업무에서 막히는지 설명하고, 중반에는 DDC의 한 사이클과 자동 스캐너 데모를 보여 준다. 후반에는 GitHub 기반 지식 저장소, meta-model, Q&A를 통해 확장성과 권한, 비용, 회의 transcript 활용 같은 운영 질문을 다룬다.
영상에는 공식 챕터와 영어 자막이 제공된다. 설명란의 외부 링크는 발표자 LinkedIn 하나뿐이지만, 발표 중에는 ea-toolkit/ddc GitHub 저장소와 DDC preprint가 언급된다. 실제 companion repo의 README는 DDC를 “TDD for knowledge bases”라고 정의하고, arXiv 2603.14057 논문 제목도 “Demand-Driven Context: A Methodology for Building Enterprise Knowledge Bases Through Agent Failure”로 확인된다.
문제 정의: 에이전트는 일반 지식보다 조직 지식에서 실패한다
발표의 도입부는 영화 Memento 비유로 시작한다. 주인공이 15분 이상 기억을 유지하지 못해 메모와 문신에 의존하듯, 오늘날 에이전트도 reasoning, computation, code generation은 강하지만 조직 내부의 문맥을 지속적으로 갖고 있지 못한다는 것이다.
이어 발표자는 Jira ticket을 예로 들며 지식을 세 색으로 나눈다. 초록색은 모델이 이미 알고 있는 일반 지식이다. 주황색은 skills, rules, extensions처럼 사용자가 가르칠 수 있는 작업 방식이다. 빨간색은 조직 안의 institutional knowledge, 즉 시스템 간 의존성, 운영 절차, 사람만 아는 예외, 오래된 의사결정 같은 지식이다.
문제는 에이전트가 실제 업무 ticket을 끝내려면 이 세 영역을 모두 채워야 한다는 점이다. 모델은 초록색과 주황색에서는 점점 강해지지만, 빨간색 지식은 회사마다 다르고 문서화도 불완전하다. 발표자가 지적하듯, 많은 팀이 여기에 RAG, MCP, knowledge graph를 붙이지만 출력이 나오는지 확인할 뿐, 그 정보가 실제 문제 해결에 충분한지는 잘 평가하지 않는다.
DDC의 전환: push가 아니라 pull
DDC의 핵심은 지식 공급 방향을 바꾸는 것이다. 기존 접근은 대체로 push 방식이다. 사람이 Confluence, Slack, GitHub, 운영 문서를 미리 정리하고, 그것을 RAG나 MCP 서버로 에이전트에게 제공한다. 하지만 이 방식은 무엇이 중요한지 모르는 상태에서 문서 전체를 끌어안기 쉽고, 오래되거나 중복되거나 사람 머릿속에만 있는 지식은 여전히 남는다.
DDC는 반대로 pull 방식이다. 새로 입사한 사람에게 모든 조직 지식을 먼저 졸업시키지 않고 실제 task를 주듯, 에이전트에게도 실제 incident나 Jira ticket을 준다. 에이전트가 실패하면, 그 실패가 “이 문제를 풀기 위해 무엇이 부족한가”라는 demand checklist를 만든다.
그 다음 사람은 전체 문서를 정리하는 대신, 에이전트가 요구한 gap만 채운다. 에이전트는 그 보충 정보를 구조화된 entity로 큐레이션하고, 다시 같은 문제를 풀어 본다. 이 과정을 반복하면 지식 베이스는 사용될지 모르는 거대한 문서 모음이 아니라, 실제 문제 해결에서 demand가 발생한 context block의 집합으로 바뀐다.
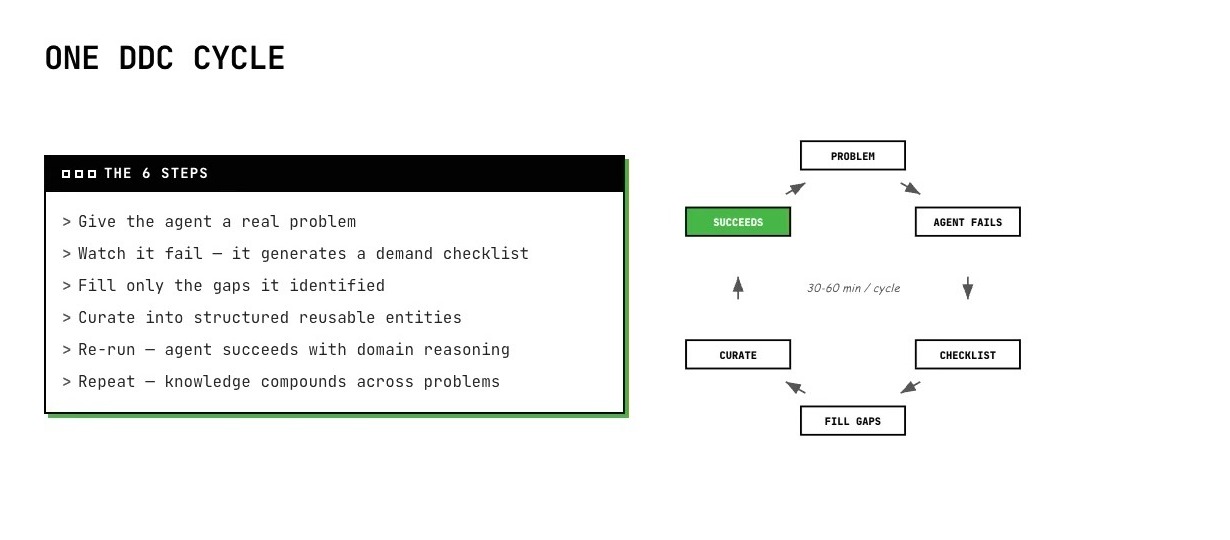
이 비유가 흥미로운 이유는 TDD와 닮았기 때문이다. TDD에서는 실패하는 test case가 필요한 코드를 드러낸다. DDC에서는 실패하는 agent attempt가 필요한 조직 지식을 드러낸다. 그래서 companion repo의 README도 DDC를 “failing agents drive curation, not failing tests”라고 설명한다.
타임라인으로 보는 핵심 구간
| 구간 | 영상 흐름 | 관찰 포인트 |
|---|---|---|
| 00:00–02:47 | 발표자 소개와 워크숍 구조 | 주제는 agent와 context management이며, 상황·문제·hands-on demo로 나뉜다. |
| 02:47–05:33 | Memento 비유와 enterprise AI 문제 | 모델은 똑똑하지만 조직 지식이 없으면 Jira epic이나 business delivery가 움직이지 않는다는 문제 제기. |
| 05:33–10:11 | 초록/주황/빨강 지식 구분 | 일반 지식, 가르칠 수 있는 작업 방식, 조직 내부 지식을 분리하고, 빨간 지식이 병목이라고 설명. |
| 10:11–13:05 | knowledge monolith와 DDC 소개 | 문서의 40%가 tribal knowledge라는 식의 문제를 제시하고, monolith를 context block으로 나누자고 제안. |
| 13:05–17:46 | pull strategy와 one DDC cycle | 지식을 미리 push하지 않고, 실제 work item에서 agent failure를 통해 필요한 지식을 pull한다. |
| 17:46–26:27 | incident root cause analysis demo | incident를 주고, agent가 missing entities를 발견하고, 사람이 보충한 정보를 새 knowledge base로 큐레이션한다. |
| 26:27–33:01 | 자동 스캔과 context gap scanner | 과거 incident들을 사용해 knowledge base의 coverage, tribal gap, stale documentation을 진단한다. |
| 33:01–36:27 | GitHub 저장소와 meta-model | 지식 저장소는 PR/review/conflict resolution이 있는 GitHub가 실용적이라고 보고, domain relationship map을 제안한다. |
| 36:27–43:33 | 가치와 takeaways | knowing the unknown, agent as knowledge manager, 80/20 context block, repo/scanner/prompt 실습을 정리한다. |
| 43:33–끝 | Q&A | 대규모 적용, team/domain scope, 권한, 비용, SaaS화, transcript 활용, documentation과 operation의 관계를 논의한다. |
지식 모놀리스를 어디에 끼워 넣을 것인가
DDC가 놓이는 위치는 발표 후반의 “complete picture” 슬라이드에서 가장 선명하다. 왼쪽에는 Confluence, Jira, SharePoint, GitHub, Slack처럼 흩어진 조직 context가 있다. 발표자는 이를 messy, tribal, outdated라고 부른다. 오른쪽에는 RAG, Graph RAG, MCP, API 같은 retrieval 계층과 agent가 있다.
DDC는 그 사이의 missing piece로 배치된다. 역할은 extract, consolidate, curate다. 즉 DDC는 retrieval을 대체하는 것이 아니라, retrieval이 읽을 수 있는 더 작은 agent-ready block을 만드는 전처리·큐레이션 계층에 가깝다.
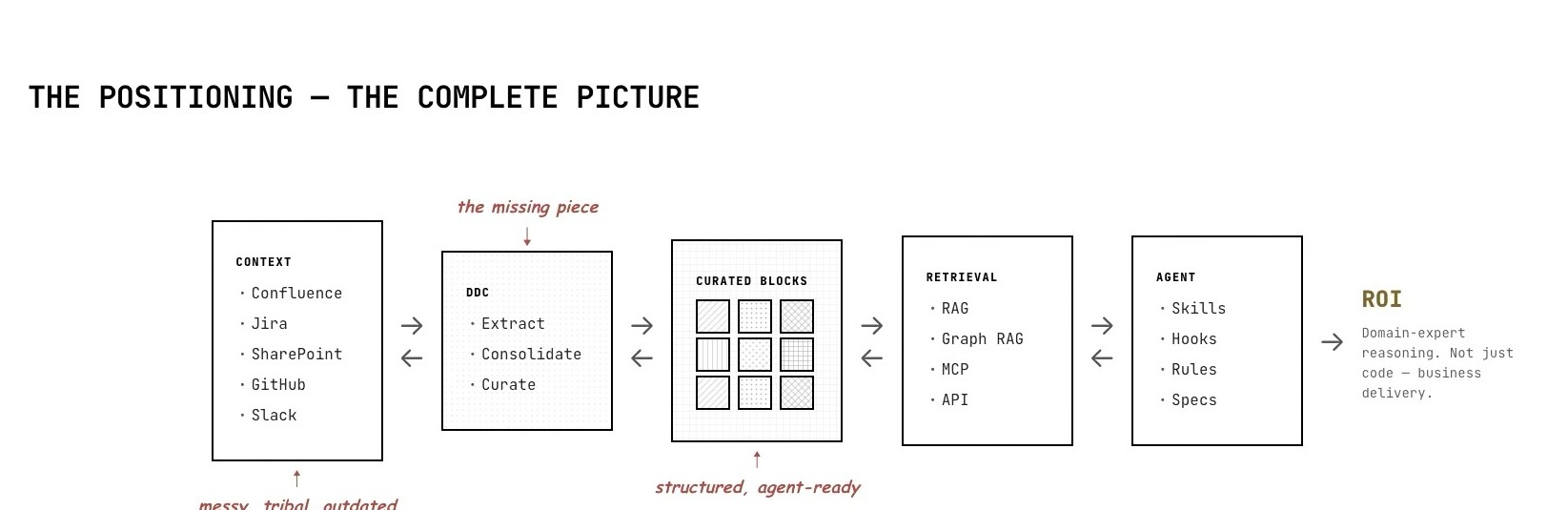
이 관점은 엔터프라이즈 RAG의 흔한 실패를 잘 설명한다. 문서가 낡고 중복되고 불완전한 상태라면, retrieval은 그 상태를 더 빠르게 검색할 뿐이다. 에이전트가 필요한 것은 “문서 전체”가 아니라 현재 문제를 해결하는 데 필요한 최소 맥락, 그리고 그 맥락이 어떤 system, API, business process, data model과 연결되는지에 대한 구조다.
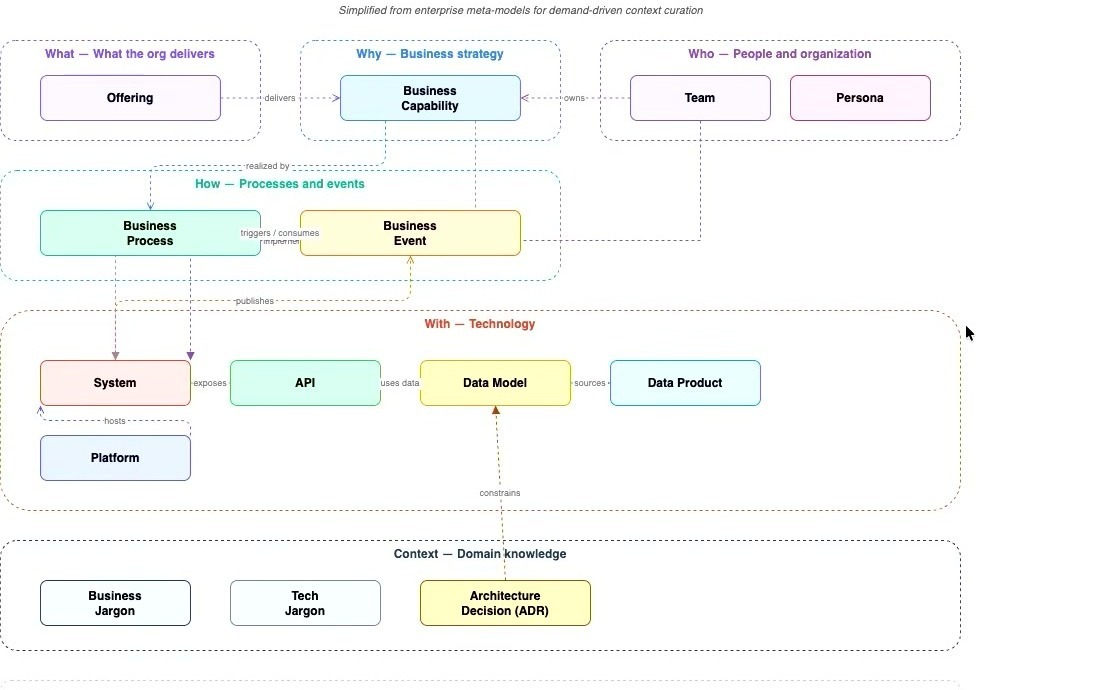
meta-model은 에이전트가 지식 베이스를 탐색하는 지도다
발표자는 DDC 자체에 meta-model이 필수는 아니지만, 있으면 더 큰 가치를 만든다고 말한다. meta-model은 조직의 제공물, 비즈니스 capability, 팀과 persona, process와 event, system/API/data model/platform, business jargon과 tech jargon, ADR 같은 domain knowledge 사이의 관계를 정의하는 지도에 가깝다.
이 지도 없이 에이전트에게 파일 묶음만 주면, 에이전트는 어떤 파일이 어떤 업무 맥락과 연결되는지 매번 추론해야 한다. 반대로 파일 구조와 entity relationship이 meta-model을 반영하면, 에이전트는 “이 system을 바꾸면 어떤 business process와 API가 영향을 받는가” 같은 질문을 더 잘 따라갈 수 있다.
데모에서 보이는 것: 에이전트를 knowledge consumer에서 knowledge manager로 바꾸기
중반 데모는 incident root cause analysis로 진행된다. 발표자는 incident description과 기존 지식 파일을 주고, 에이전트가 먼저 monolith knowledge base에서 정보를 찾게 한다. 이 부분은 전통적인 RAG/MCP와 비슷하다. 차이는 그 다음이다.
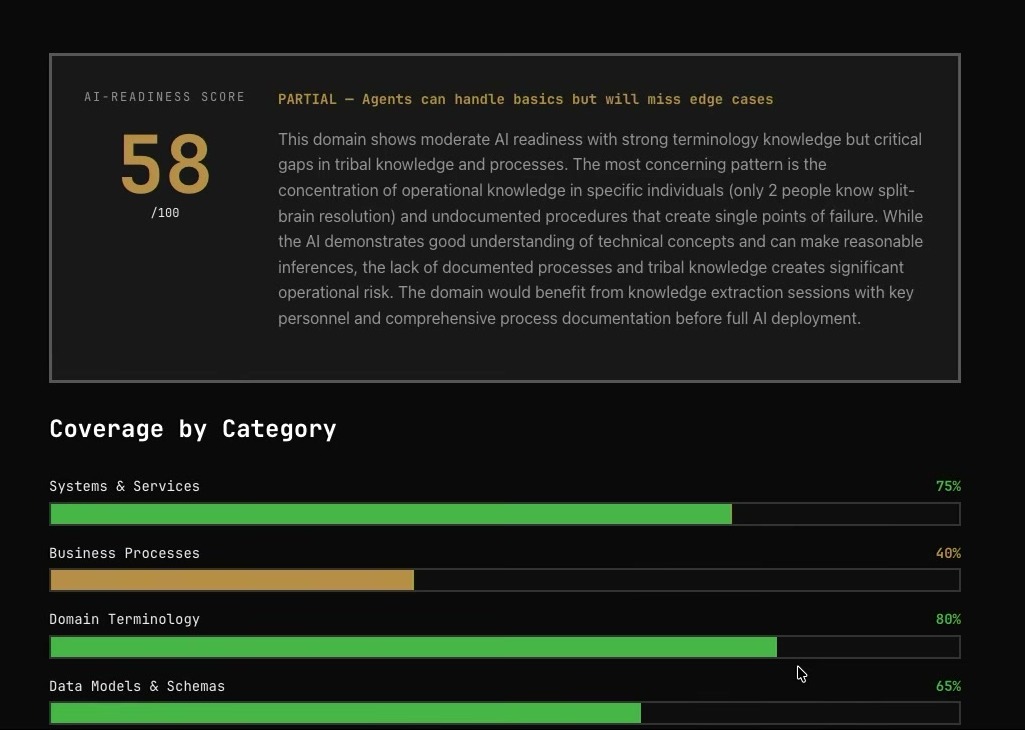
에이전트가 충분한 정보를 찾지 못하면, 해결에 필요한 missing information을 checklist로 만든다. 발표자는 준비해 둔 답변을 넣고, 에이전트는 새 entity를 발견·추가한다. 자막 기준으로 발표자는 한 문제에서 문서화되지 않은 여섯 개 안팎의 entity가 surfaced되고, 보충 정보를 준 뒤 다시 다섯여섯 개의 entity가 큐레이션되는 흐름을 설명한다.
이어 14개 incident를 반복하면 confidence가 약 1.5에서 4.4 수준으로 올라간다고 설명한다. 이것은 엄밀한 benchmark라기보다 워크숍 데모의 내부 score지만, 메시지는 분명하다. 에이전트를 단순히 지식을 소비하는 주체로 두지 말고, 문제 해결 중 발견한 gap을 다시 지식 베이스로 남기는 knowledge manager로 만들자는 것이다.
이 데모의 강점은 “새로운 에이전트 프레임워크”보다 “운영 루프”를 보여 준다는 점이다. DDC는 Claude Code, Copilot, 다른 agent harness 위에서 구현될 수 있다고 설명된다. 핵심은 특정 도구가 아니라 problem → failure → demand checklist → human gap fill → curation → retry라는 반복 루프다.
연결 자료에서 확인되는 점
공식 companion repo는 ea-toolkit/ddc다. GitHub API 기준 이 저장소는 MIT 라이선스이며, 조회 시점 기준 약 20 stars, 6 forks를 가진 초기 공개 프로젝트다. README는 DDC를 “TDD for knowledge bases”라고 정의하고, METHODOLOGY.md, WHY.md, CLAUDE.md, meta/, templates/, tooling/, examples/healthcare-claims/, ddc-cycle-log/ 등을 포함한다고 설명한다.
README의 quick start는 tooling 디렉터리에서 healthcare claims 예제 지식 베이스를 띄워 보고, templates/domain-skeleton을 복사해 자기 domain을 시작하는 흐름을 안내한다. 즉 워크숍의 데모는 단순 발표 슬라이드가 아니라, 실제 repo 구조와 예제 domain skeleton에 연결되어 있다.
arXiv 2603.14057 페이지에서는 논문 제목이 “Demand-Driven Context: A Methodology for Building Enterprise Knowledge Bases Through Agent Failure”로 확인된다. 저자는 Raj Navakoti와 Saideep Navakoti이며, 2026년 3월 14일 날짜의 cs.AI preprint다. abstract 역시 top-down knowledge engineering과 bottom-up automation의 한계를 지적하고, agent failure를 domain knowledge curation의 primary signal로 쓰는 problem-first methodology라고 설명한다.
다만 근거의 성격은 분리해서 읽어야 한다. GitHub README는 empirical evaluation으로 50개 real enterprise ticket, 기존 documentation이 fully answer한 demanded knowledge 20.2%, missing or tribal 39.4%, 24개 DDC-curated entity가 127개 documentation page 위 RAG보다 5점 척도에서 4.49 대 3.20으로 높았다는 수치를 제시한다. 동시에 IEEE Software 평가는 under review라고 적혀 있으므로, 공개 글에서는 이를 확정된 산업 표준 결과가 아니라 프로젝트 측이 보고한 초기 평가 수치로 다루는 것이 안전하다.
| 근거 | 확인한 내용 | 해석 |
|---|---|---|
| YouTube metadata | AI Engineer 채널, 2026-05-05 업로드, 약 68분, 공식 챕터 19개 | 워크숍형 발표이며, 자막과 챕터로 구조를 재구성할 수 있다. |
| Transcript | Memento 비유, green/orange/red knowledge, monolith, pull strategy, 14 incidents, GitHub repo, meta-model, Q&A | 영상의 실제 주장은 지식 큐레이션 운영 루프에 집중된다. |
ea-toolkit/ddc README |
DDC is TDD for knowledge bases, repo structure, quick start, research links, key findings | 영상에서 소개한 방법론이 공개 repo와 문서로 이어진다. |
arXiv 2603.14057 |
DDC paper, Raj Navakoti / Saideep Navakoti, cs.AI preprint, 18 pages | 방법론의 연구적 framing은 preprint로 공개되어 있다. |
| Q&A | 작은 team/domain부터 시작, 권한은 구현 방식 문제, manual cycle은 고통스럽고 automation이 중요 | 대규모 전사 적용보다 좁은 scope에서 반복 루프를 검증하는 접근이 현실적이다. |
실무 관점에서의 해석
DDC의 가장 좋은 점은 “문서화를 더 열심히 하자”라고 말하지 않는다는 데 있다. 조직 지식 베이스가 실패하는 이유는 사람들이 게을러서만이 아니다. 무엇이 중요한지 모르고, 사용되지 않을 문서까지 미리 쓰려 하며, 실제 업무에서 발생하는 질문과 문서 구조가 맞지 않기 때문이다.
DDC는 이 문제를 demand signal로 바꾼다. 어떤 incident, ticket, customer support case를 풀 때 에이전트가 막힌다면, 그 막힘은 지식 베이스의 결함 위치를 알려 준다. 이 신호를 모으면 “무엇을 먼저 문서화해야 하는가”라는 knowledge backlog가 생긴다. 발표에서 Context Gap Scanner가 Kanban board와 priority를 만드는 것도 이 맥락이다.
또 하나의 가치 있는 관점은 GitHub를 지식 저장소로 보는 선택이다. 발표자는 향후 SaaS가 나올 수 있겠지만, 지금은 GitHub repository가 practical하다고 말한다. 여러 팀과 여러 agent가 같은 지식 베이스에 기여하면 conflict, review, permission, versioning이 필요하고, GitHub는 이 운영 메커니즘을 이미 갖고 있기 때문이다.
물론 이 접근은 만능이 아니다. Q&A에서 발표자도 enterprise 전체 범위로 곧장 적용하기보다는 작은 team, 작은 domain, 해당 팀의 Jira ticket과 Confluence page 수준으로 scope를 줄이는 편이 빠르고 유용하다고 말한다. 또한 수동으로 cycle을 반복하는 것은 고통스럽고, 실제 가치는 automation에서 나온다고 설명한다.
이 점에서 DDC는 대형 지식 그래프 구축 프로젝트라기보다, 에이전트가 실패할 수 있는 실제 문제를 테스트 케이스처럼 모으고, 그 실패를 조직 지식의 리팩터링 backlog로 바꾸는 운영 방법론에 가깝다. 에이전트 시대의 문서화는 위키 페이지를 더 많이 쓰는 일이 아니라, agent failure를 관찰하고, 반복 가능한 context block과 entity relationship으로 남기는 일이 될 가능성이 크다.
한 줄로 요약하면
Demand-Driven Context는 에이전트에게 조직 지식을 미리 모두 밀어 넣는 대신, 실제 업무에서 에이전트가 실패하며 요구한 지식만 pull해 구조화하고, 그 과정을 반복해 knowledge monolith를 agent-ready context block으로 바꾸는 방법론이다.