에이전트가 실제 제품 워크플로우를 맡기 시작하면, 성능 병목은 더 이상 모델의 일반 능력만으로 설명되지 않는다.
같은 LLM을 써도 어떤 도구를 언제 호출하는지, 실패한 중간 단계에서 어떻게 복구하는지, 멀티 에이전트 시스템 안에서 어느 역할이 병목인지에 따라 결과가 크게 달라진다.
그런데 지금까지 많은 에이전트 개선 작업은 프롬프트를 손으로 다시 쓰거나, 체인을 뜯어고치거나, 로그를 보고 감으로 조정하는 식에 가까웠다.
AI Sparkup 글이 짚은 Agent Lightning의 흥미로운 지점은 바로 이 수동 튜닝 문제를 강화학습 기반의 반복 가능한 학습 루프로 바꾸려 한다는 점이다.
다만 이 글을 그대로 옮기기보다, 공식 GitHub 저장소와 arXiv 논문을 따라가 보면 Agent Lightning의 핵심은 단순히 “에이전트에 RL을 붙였다”가 아니다.
진짜 포인트는 기존 에이전트 실행 로직과 RL 학습 인프라를 분리하면서도, 그 사이를 연결하는 통합 데이터 인터페이스와 계층형 credit assignment 구조를 만들었다는 데 있다.
무엇을 해결하려는가
기존 LLM 강화학습 프레임워크는 대체로 단일 프롬프트-단일 응답 구조를 전제로 설계되어 있다.
수학 풀이, 선호도 정렬, reasoning 같은 작업에서는 이 전제가 어느 정도 맞지만, 실제 에이전트는 훨씬 복잡하다.
한 번의 작업 안에 여러 차례 LLM 호출이 들어가고, 그 사이에 검색·SQL 실행·API 호출·코드 실행 같은 도구 사용이 끼어들며, 멀티 에이전트 구조에서는 서로 다른 역할의 에이전트가 상태를 주고받는다.
이런 흐름을 단순히 긴 시퀀스로 이어 붙여 RL을 거는 방식은 컨텍스트가 비대해지고, 어떤 호출이 최종 보상에 얼마나 기여했는지 credit assignment가 어려워진다.
Agent Lightning은 이 문제를 “에이전트를 RL 친화적으로 다시 쓰자”가 아니라 “기존 에이전트의 실행 궤적을 학습 가능한 단위로 재구성하자”로 푼다.
논문은 이를 위해 agent execution을 Markov decision process로 공식화하고, 상태(state)·행동(action)·보상(reward) 중심의 unified data interface를 정의한다.
이 구조 덕분에 LangChain, OpenAI Agents SDK, AutoGen 같은 프레임워크 위의 에이전트뿐 아니라 순수 Python으로 짠 에이전트도 거의 같은 학습 경로로 들어올 수 있게 된다.
핵심 아이디어 / 구조 / 동작 방식
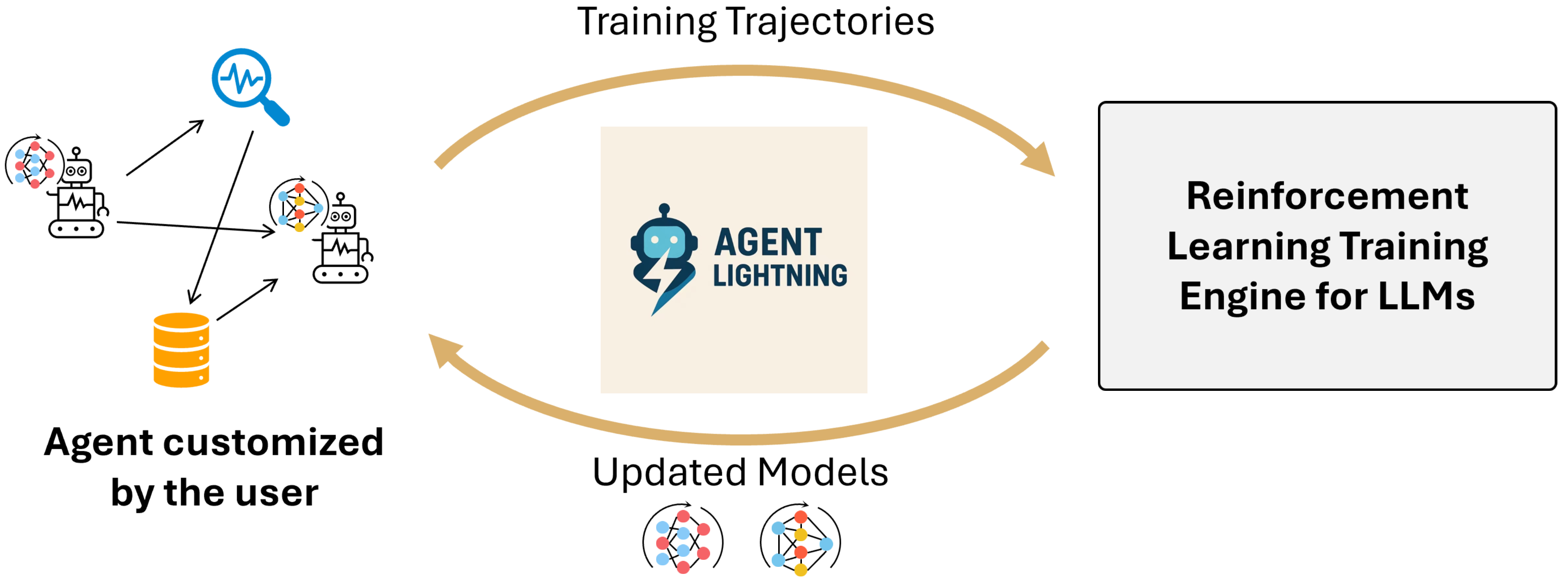
Agent Lightning의 첫 번째 핵심은 execution과 training의 decoupling이다.
공식 논문 표현대로 이 프레임워크는 agent execution과 RL training 사이의 complete decoupling을 목표로 한다.
에이전트는 기존처럼 실행되고, 그 과정에서 발생하는 프롬프트, 응답, 도구 호출, 상태 변화, 보상 신호가 수집된다.
이 데이터는 단순 로그가 아니라 transition 단위의 구조화된 trajectory로 정리된다.
여기서 중요한 점은 LLM 호출뿐 아니라 비LLM 컴포넌트가 만든 상태 변화도 함께 캡처된다는 것이다.
두 번째 핵심은 LightningRL이다.
논문은 기존 single-turn RL 알고리즘을 에이전트 환경으로 직접 확장하기 어렵다고 보고, trajectory를 action transition들로 분해한 뒤 hierarchical RL 방식으로 credit assignment를 수행한다.
즉 episode-level return을 먼저 각 action으로 나누고, 다시 그 action 내부 토큰 수준 supervision으로 연결한다.
이 구조 덕분에 GRPO, PPO, REINFORCE++ 같은 기존 single-turn RL 알고리즘을 완전히 새로 쓰지 않고도 에이전트 학습에 재사용할 수 있다.
세 번째 핵심은 Training-Agent Disaggregation 아키텍처다.
논문과 GitHub README를 함께 보면, 이 프레임워크는 Lightning Server와 Lightning Client로 나뉜다.
Server는 RL training과 모델 업데이트를 담당하고 OpenAI-like API를 노출한다.
Client는 실제 에이전트를 실행하면서 데이터 송수신과 trajectory collection을 맡는다.
덕분에 GPU 자원과 학습 프레임워크는 서버 쪽에 두고, 애플리케이션 로직과 도구 체인은 상대적으로 자유로운 클라이언트 쪽에 둘 수 있다.
README가 반복해서 말하는 “ZERO CODE CHANGE (almost)“는 바로 이 분리 위에서 성립한다.
필요하면 agl.emit_xxx() 헬퍼를 넣거나 tracer를 통해 자동 수집을 켤 수 있다.
또 하나 실무적으로 중요한 장치는 AIR(Automatic Intermediate Rewarding)다.
에이전트 학습은 최종 성공/실패만 보상으로 주면 reward sparsity가 심해지기 쉽다.
Agent Lightning은 tool call status 같은 시스템 모니터링 신호를 intermediate reward로 변환할 수 있게 설계해, 중간 단계에서 더 촘촘한 학습 신호를 만들 수 있게 한다.
이는 실제 워크플로우형 에이전트에서 꽤 중요한 차이다.
| 접근 방식 | 에이전트 개선 방식 | 장점 | 한계 |
|---|---|---|---|
| 수동 프롬프트/체인 튜닝 | 사람이 프롬프트와 흐름을 반복 수정 | 빠르게 시작 가능하고 도구가 단순함 | 재현성이 낮고 규모가 커질수록 운영 피로가 큼 |
| 에이전트와 강하게 결합된 RL | 특정 프레임워크/실행 구조에 맞춰 학습 파이프라인 구성 | 특정 스택에서는 높은 최적화 가능 | 다른 에이전트로 이식이 어렵고 코드 침습성이 큼 |
| Agent Lightning | 실행 궤적을 unified interface로 수집하고 LightningRL로 최적화 | 기존 에이전트를 거의 안 건드리고 학습 루프를 붙일 수 있음 | reward 설계·credit assignment 품질·운영 복잡도는 여전히 중요 |
공개된 근거에서 확인되는 점
공식 논문은 Agent Lightning을 세 가지 대표 시나리오로 검증한다.
첫째는 LangChain 기반 text-to-SQL 에이전트다.
Spider 데이터셋을 사용했고, SQL 작성·검사·재작성 흐름을 가진 3-agent 구조에서 두 개의 에이전트만 선택적으로 최적화한다.
이 사례는 멀티 에이전트 시스템 전체를 다시 학습시키지 않고 일부 역할만 골라 성능을 올릴 수 있다는 점을 보여준다.
둘째는 OpenAI Agents SDK 기반의 RAG 에이전트다.
논문은 retrieve-augmented generation 흐름을 unified data interface의 대표 예시로 사용하며, 질의 생성, 검색, 최종 답변 생성이 각각 transition으로 분해될 수 있음을 보여준다.
셋째는 AutoGen 기반의 math tool-use 에이전트다.
즉 이 프레임워크는 단일 도메인 데모가 아니라, 서로 다른 agent framework와 task pattern을 대상으로 공통 학습 루프를 제시하려 한다.
정량 결과를 논문이 전부 한 줄 숫자로 요약하지는 않지만, Figure 5 이하 reward curve들은 text-to-SQL, RAG, math tool-use 시나리오에서 지속적이고 안정적인 개선 경향을 보여주는 근거로 제시된다.
논문 초록 역시 이 실험들이 stable, continuous improvements를 보였다고 요약한다.
또한 Figure 3은 LightningRL이 기존 multi-turn GRPO류 방식과 달리 trajectory를 transition으로 분해해 grouping과 advantage estimation을 다룬다는 점을 시각적으로 설명한다.
오픈소스 프로젝트의 외형적 신호도 무시하기 어렵다.
현재 GitHub 저장소 기준으로 약 17.1k stars, 1.5k forks, 255 commits, 130 branches가 보이며, agentlightning, docs, examples, dashboard, docker 같은 디렉터리가 분리돼 있다.
README는 LangChain, OpenAI Agent SDK, AutoGen, CrewAI, Microsoft Agent Framework를 지원 대상으로 명시하고 있고, 설치는 pip install agentlightning으로 안내한다.
또한 RL뿐 아니라 Automatic Prompt Optimization, SFT 등도 수용한다고 설명해, 장기적으로는 “에이전트 학습 런타임”을 지향하고 있음을 보여준다.
| 공개된 근거 | 확인된 내용 | 의미 |
|---|---|---|
| arXiv 논문 | unified data interface, LightningRL, TA Disaggregation 제안 | Agent RL을 단순 트릭이 아니라 알고리즘+시스템 문제로 다룸 |
| 실험 태스크 | LangChain text-to-SQL, OpenAI Agents SDK RAG, AutoGen math tool-use | 특정 프레임워크 전용이 아니라는 주장에 근거를 부여 |
| GitHub README | ZERO CODE CHANGE (almost), multi-agent selective optimization, AIR, 설치 가이드 | 실제 도입 관점에서 필요한 포지셔닝과 사용 경로를 문서화 |
| 저장소 상태 | 높은 star/fork와 활발한 commit 흐름 | 단발성 데모보다 커뮤니티 관심과 유지 가능성이 높음 |
실무 관점에서의 해석
내가 보기에 Agent Lightning의 진짜 의미는 “에이전트를 만들고 끝”이 아니라 “에이전트를 운영하며 학습시킨다”는 관점을 시스템 수준에서 밀어붙인다는 데 있다.
지금까지 많은 에이전트 프레임워크는 orchestration에는 강했지만, 그 실행 데이터가 어떻게 학습 루프로 되돌아가는지는 상대적으로 약했다.
Agent Lightning은 바로 그 지점을 노린다.
관측 가능한 runtime data를 training data로 재구성하고, observability stack과 RL stack을 연결하는 운영 레이어를 만든다는 점이 핵심이다.
이 관점은 특히 기업 내부 에이전트나 private-domain agent에서 중요하다.
프롬프트만 손보는 방식으로는 사내 데이터, 내부 도구, 조직별 워크플로우에 맞는 행동을 안정적으로 학습시키기 어렵다.
반면 Agent Lightning이 제안하는 구조는 실제 배포 환경에서 생성되는 trajectory를 수집해 agent-specific adaptation에 활용할 수 있다는 점에서 더 현실적이다.
물론 한계도 있다.
“코드 변경 거의 없음”은 좋은 메시지이지만, 실제로는 reward function 설계, 실패 케이스 정의, 어떤 agent를 선택적으로 최적화할지, intermediate reward를 어떻게 줄지 같은 운영 설계가 필요하다.
또한 RL이 들어가는 순간 학습 비용, 평가 안정성, 오버피팅, policy drift 같은 문제가 새로 생긴다.
다시 말해 Agent Lightning은 수동 튜닝을 완전히 없애는 마법봉이 아니라, 수동 튜닝을 더 체계적인 학습 인프라로 치환하려는 시도에 가깝다.
그럼에도 불구하고 이 프로젝트는 에이전트 시스템이 앞으로 어떤 형태로 진화할지를 꽤 선명하게 보여준다.
에이전트 프레임워크가 단순 orchestration tool을 넘어서, 실행·관측·학습이 닫힌 루프를 이루는 adaptive system으로 가야 한다는 신호다.
Agent Lightning은 그 전환점에서 “agent training infrastructure”라는 새로운 층을 제안하는 프로젝트로 보는 편이 가장 정확해 보인다.